







0. 前言
本文总结了几个在深度学习中比较常用的激活函数:Sigmoid、ReLU、LeakyReLU以及Tanh,从激活函数的表达式、导数推导以及简单的编程实现来说明。
1. Sigmoid激活函数
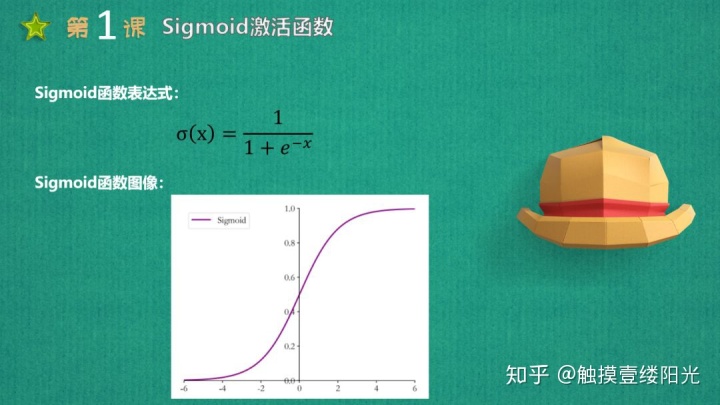

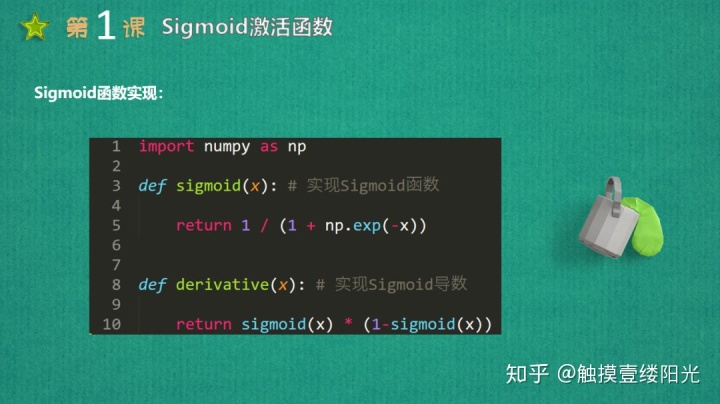
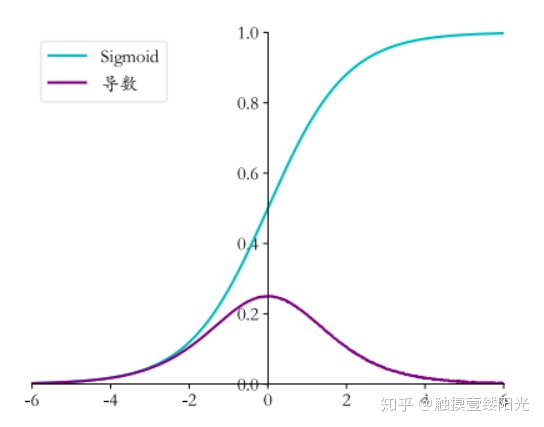
Sigmoid激活函数也叫做Logistic函数,因为它是线性回归转换为Logistic(逻辑回归)的核心函数,这也是Sigmoid函数优良的特性能够把X ∈ R的输出压缩到X ∈ (0, 1)区间。Sigmoid激活函数在其大部分定义域内都会趋于一个饱和的定值。当x取绝对值很大的正值的时候,Sigmoid激活函数会饱和到一个高值(无限趋近于1);当x取绝对值很大的负值的时候,Sigmoid激活函数会饱和到一个低值(无限趋近于0)。Sigmoid函数是连续可导函数,在零点时候导数最大,并在向两边逐渐降低,可以简单理解成输入非常大或者非常小的时候,梯度为0没有梯度,如果使用梯度下降法,参数得不到更新优化。
Sigmoid函数最大的特点就是将数值压缩到(0, 1)区间,在机器学习中常利用(0, 1)区间的数值来表示以下意义:
- 概率分布:根据概率公理化定义知道,概率的取值范围在[0, 1]之间,Sigmoid函数的(0, 1)区间的输出和概率分布的取值范围[0, 1]契合。因此可以利用Sigmoid函数将输出转译为概率值的输出。这也是Logistic(逻辑回归)使用Sigmoid函数的原因之一;
- 信号强度:一般可以将0~1理解成某种信号的强度。由于RNN循环神经网络只能够解决短期依赖的问题,不能够解决长期依赖的问题,因此提出了LSTM、GRU,这些网络相比于RNN最大的特点就是加入了门控制,通过门来控制是否允许记忆通过,而Sigmoid函数还能够代表门控值(Gate)的强度,当Sigmoid输出1的时候代表当前门控全部开放(允许全部记忆通过),当Sigmoid输出0的时候代表门控关闭(不允许任何记忆通过)。
上面介绍了Sigmoid激活函数将输出映射到(0, 1)区间在机器学习中的两个意义,这也是Sigmoid激活函数的优点。接下来介绍一下Sigmoid激活函数的缺点:
- 经过Sigmoid激活函数输出的均值为0.5,即输出为非0均值;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4001
4001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









