







目前,在很多OLTP场景中,MySQL数据库都有着广泛的应用,也有很多不同的使用方式。从数据库的业务需求、架构设计、运营维护、再到扩容迁移,不同的MySQL架构有不同的特点,适应一定的业务场景,或者解决一定的业务问题。
本文从MySQL常见架构、业务环境分类、业务与架构结合使用原则三个方面对MySQL数据库和业务场景进行探讨和说明,让大家先分别对MySQL的架构和业务分类有所了解,然后再将两者贯通起来,使得能够在进行业务与MySQL架构设计时纲举目张,让用户可以用合适的技术解决支撑业务需求。
一、MySQL数据库常见架构
为了对MySQL数据库常见架构,能够有进行比较清晰的认识,下面先从MySQL三种通用基础架构、五种特殊需求架构、架构组合与综合使用三个方面进行说明。
1、MySQL三种常见基础架构
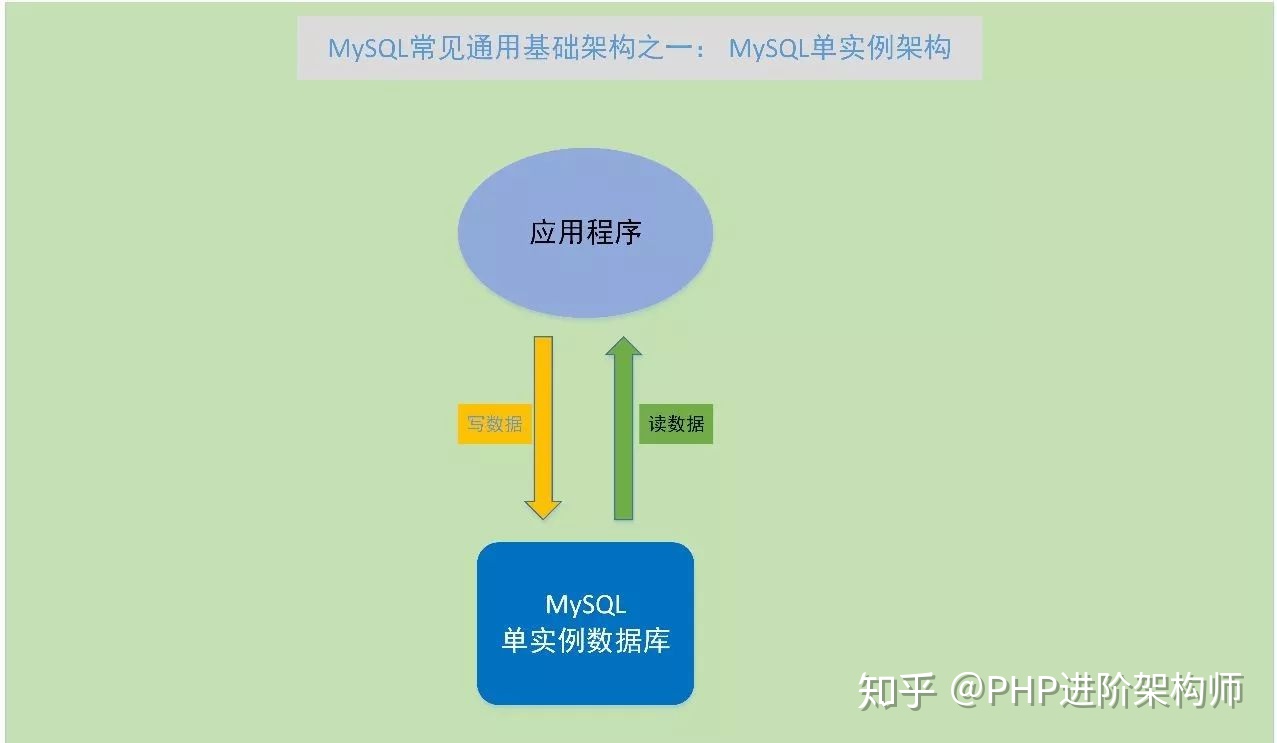
(1)MySQL单实例架构
MySQL单实例,就是在服务器上部署一个MySQL实例来对外提供服务,这是最开始接触MySQL数据库会使用的方式,也是常见学习、研究MySQL数据库的使用方式。
MySQL单实例的使用方式,是MySQL数据库使用的第一阶段,通常这种情况下,MySQL数据库与应用程序会在同一个服务器上。
这种方式主要好处就是部署和使用简单,直接通过编译安装,或者二进制包解压安装,很快就可以有一个可以使用的MySQL数据库环境。同时,这种方式,依赖性少,不需要依赖其他第三方工具或者软件,维护和故障定位也比较容易。
熟悉和掌握好MySQL单实例环境的技能,也是维护其它MySQL架构的基础。
需要注意的是,MySQL单实例在学习和开发环境可以使用一下,但这种方式的可用性和灾备性较弱,如果作为业务系统使用的数据库,尽量不要用这种方式。

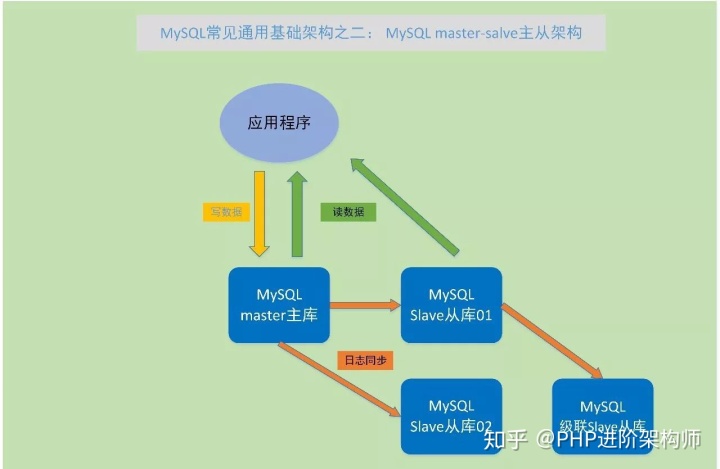
(2)MySQL master-slave主从架构
MySQL master-slave主从环境,是在MySQL单实例环境的基础上,将MySQL进行全库备份,再恢复出一个或多个MySQL实例,通过change master命令,指定新恢复出的MySQL实例,从那个MySQL节点上读取变化日志,并在本地应用,使新恢复的实例与原来的MySQL实例数据一致保持一致。
所以,原来的数据一致变化的实例,叫master主节点;从master节点获取日志,并在本地应用,使数据与master阶段保持一致的节点,叫slave从节点;这样的架构环境,就叫 master-slave主从环境。
Master-slave主从环境,是MySQL数据库非常具有特色的功能,也是MySQL数据库应用在生产环境的常见架构。
通过master-slave架构,就可以使线上数据库的数据有了多份,起到了一定的数据备份功能。Slave从库数据变化只通过应用日志实现,一般不会主动产生写数据的情况,但可以提供对外数据读服务,这样通过增加几个slave从库,让只进行数据读取的业务到slave从库上查询,就都可以大大提高业务的读性能和吞吐量。在互联网行业中,非常多的数据读操作远高于数据写操作的业务场景,通过在master主节点写数据,在slave节点上读数据,进行这种读写分离的架构,可以很好地满足业务需求。
当然,MySQL的master-slave主从架构,具体实现也可以非常灵活,1个master主节点,可以有1个或多个slave从节点;而一个slave节点,也可以当做其它节点的slave节点,如果一个slave节点后面再有其它节点当做这个节点的slave从节点,就叫做级联复制。
MySQL的master-save架构,在MySQL单实例架构的基础上,提高了MySQL数据库的性能、可用性和可扩展性,同时也为MySQL数据库追求更高的可用性,提供了基础保障。
(3MySQL MHA高可用架构
虽然MySQL数据库的master-salve主从架构,使数据库有了多份,但这些maste主节点和slave从节点之间,仍然是相对独立的,尤其是master主节点如果出现故障了,仍然是不能对外提供数据库服务的。为了应该各种故障和特殊情况,实现数据库更高的可用性,就需要在master-slave的基础上,通过其它组件来实现更高的可用性。MySQL高可用性的方案比较多,但目前比较主流、比较成熟的方案,还是MySQL + MHA高可用架构。
简单来说,为了实现更高的可用性,就要在master-slave主从环境的基础上,将业务连接master的IP,有master主机的实际IP,变成虚拟的VIP或者域名。应用程序通过VIP访问数据库,进行数据读写,在正常情况下,业务在master上进行读写;如果master节点出现故障,高可用组件会监测到这个故障,并将VIP切换到slave从库上,同时对于slave从库上进行日志的传输和应用,保证slave上的数据,与master节点故障前的数据尽量一致,这样切换后新的slave节点就仍然可以对外提供数据库服务。
当然,对于具体实现来说,在MySQL的master-slave主从结构外,VIP和数据库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









