






零基础学习梯度下降算法
作者:Philipp Muens
翻译:老齐
与本文相关的图书推荐:《数据准备和特征工程》
梯度下降法是机器学习中最基本的优化技术之一。那么,什么是梯度? 下降的是什么?我们要优化的是什么?
这些可能是第一次接触梯度下降时想到的一些问题,本文就从零基础开始实现梯度下降,并在过程中回答这些问题。
优化和损失函数
许多机器学习问题需要某种形式的优化。通常,算法首先对正确答案进行初步猜测,然后慢慢地调整参数,使其在每次预测检验中的误差变小。
这个学习过程反复进行,直到算法学会了“正确地”预测到结果为止。
为了弄清楚算法在预测上的误差,我们需要定义一个损失函数的概念。损失函数将猜测值与实际值进行比较,并将两者之间的差异转化为一种度量标准,我们可以用它来量化算法的质量。重要的损失函数包括均方误差(MSE)、均方根误差(RMSE)或平方误差和(SSE)。
想象这样一种情境:将算法所造成的误差放到一个平面上,然后找到误差最少的地方,这正是梯度下降发挥作用的地方。在梯度下降的情况下,我们遍历这个表面,以便找到这样一个地方。
梯度下降
我们已经发现,在处理机器学习问题时,损失函数和优化通常是相互交织的。虽然把它们放在一起学习很有意义,但我个人认为:在探索核心思想时,更有价值的做法是保持简单和专注。因此,接下来,我们只专注于把梯度下降作为一种数学优化技术。这种技术可以应用于各种不同的领域(包括机器学习问题)。
抛物面
我们要做的第一件事就是定义用来运行梯度下降算法的函数。大多数例子用单变量函数解释算法的核心概念,比如从抛物线类(例如 )中获取的函数。单变量函数可以很容易地沿着 和 轴在二维空间中绘制出来。除了其他不错的性质,只处理二维会让复杂的数学变得容易很多。然而,现实世界的机器学习问题处理的数据的维数更高,虽然从2D到3D有一个稍微陡峭的学习曲线,但是从3D到nD没有什么新的东西需要学习。正因为如此,我们将选择含有2个变量的函数来研究梯度下降法。
大多数人在学校都是通过抛物线来学习二次函数的性质的。我们可以在三维中绘制出一个等价的函数吗?假设你有一个抛物线,它像离心机一样沿着 轴旋转,最终会得到一个被称为抛物面的曲面,一个“三维抛物线”。
定义抛物面的方法有很多,但在这里我们使用"无限抛物面",它的定义如下:
将数学转化为代码,结果是:
def paraboloid(x: float, y: float) -> float: return x ** 2 + y ** 2很简单。接下来,我们应该生成一些测试数据,将其传到抛物面函数中,并绘制结果,看看是否一切都如预期的那样:
# Test data generation (only really necessary for the plotting below)xs_start = ys_start = -10xs_stop = ys_stop = 11xs_step = ys_step = 1xs: List[float] = [i for i in range(xs_start, xs_stop, xs_step)]ys: List[float] = [i for i in range(ys_start, ys_stop, ys_step)]zs: List[List[float]] = []for x in xs: temp_res: List[float] = [] for y in ys: result: float = paraboloid(x, y) temp_res.append(result) zs.append(temp_res)print(f'xs: {xs}\n')# xs: [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(f'ys: {ys}\n')# ys: [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(f'zs: {zs[:5]} ...\n')# zs: [[200, 181, 164, 149, 136, 125, 116, 109, 104, 101, 100, 101, 104, 109, 116, 125, 136, 149, 164, 181, 200], [181, 162, 145, 130, 117, 106, 97, 90, 85, 82, 81, 82, 85, 90, 97, 106, 117, 130, 145, 162, 181], [164, 145, 128, 113, 100, 89, 80, 73, 68, 65, 64, 65, 68, 73, 80, 89, 100, 113, 128, 145, 164], [149, 130, 113, 98, 85, 74, 65, 58, 53, 50, 49, 50, 53, 58, 65, 74, 85, 98, 113, 130, 149], [136, 117, 100, 85, 72, 61, 52, 45, 40, 37, 36, 37, 40, 45, 52, 61, 72, 85, 100, 117, 136]] ...可以使用以下代码来绘制图形(使用Plotly库):
fig = go.Figure(go.Surface(x=xs, y=ys, z=zs, colorscale='Viridis'))fig.show()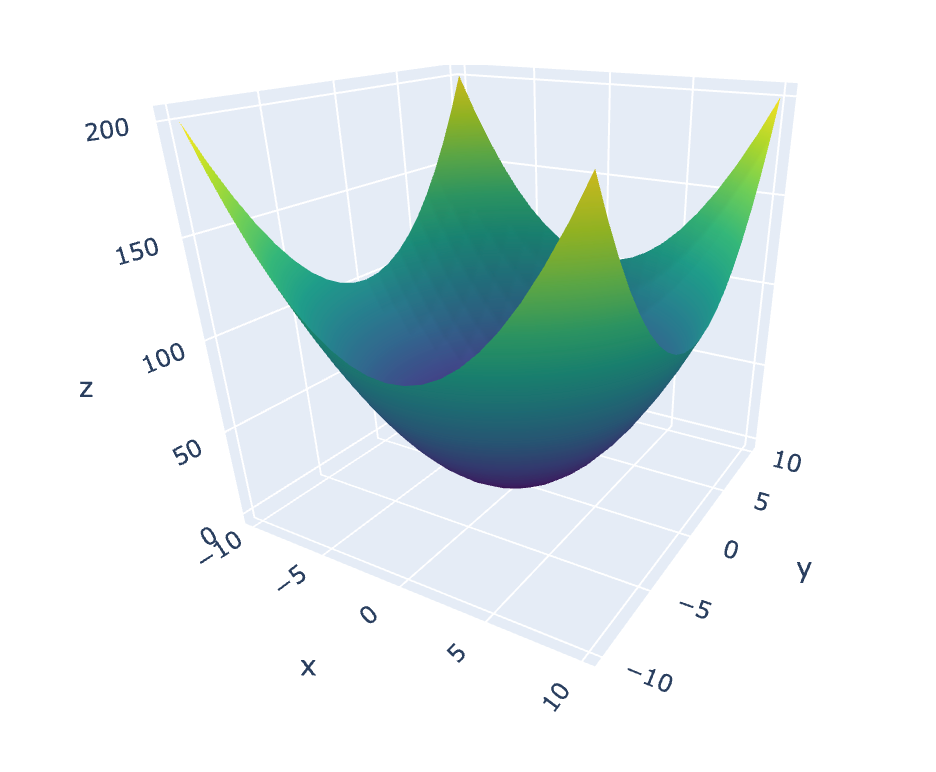
梯度和导数
根据维基百科,梯度的定义是:
…… 向量值函数 …… 在点 处的值是向量,该向量的分量是点 处 的偏导数。
这个定义听起来很有道理,但梯度的核心概念真的很简单。上面这句话试图表达的是:对于函数绘制的曲面上的任意点,都有一个由偏导数组成的向量,该向量指向最大的递增方向。
有了这样的解释,我们唯一需要理清的概念就是偏导数的概念。
如果你学过微积分,你肯定会遇到过导数问题。快速回顾一下:导数测量的是函数输出方面的变化相对于其输入方面的变化的敏感度。
导数可以是不同阶的。最重要的导数之一就是一阶导数,它是一条切线的斜率,它告诉我们函数在任意一点上是递增还是递减。
微分过程遵循几个规则。我们将在遍历下面的示例时应用其中的一些规则,以便重新唤起我们对微积分基础的美好记忆。
计算下列函数的一阶、二阶和三阶导数:
根据微分规则,一阶导数为:
二阶导数为:
三阶导数为:
我们为什么要这么做?通过上述内容,你可能还记得:梯度是函数在点处的偏导数向量。所以为了计算梯度,我们需要计算函数的偏导数。
上面展示了如何计算导数,但是我们如何计算偏导数呢?如果你知道如何计算导数,你就已经知道如何计算偏导数了。偏导数的奇妙之处在于:你在对一个变量求导的同时,把其他变量看成常数。
让我们应用这个规则来计算抛物面函数的偏导数:
我们计算的第一个偏导数是相对于的导数,将视为常数:
第二个偏导数的计算遵循同样的模式,即以为常数,对相对于求导:
注意:不要被这里的符号搞糊涂了。当你使用来表示“普通”导数时,你只需使用来表示偏导数。
就是这样。有了这些偏导数,我们现在可以计算函数的标绘表面上任意点ppp的任何梯度。让我们把我们的发现转化成代码:
def compute_gradient(vec: List[float]) -> List[float]: assert len(vec) == 2 x: float = vec[0] y: float = vec[1] return [2 * x, 2 * y]梯度下降
让我们回顾一下迄今为止所取得的成就。首先,编写并绘制了一个名为“无限抛物面”的函数,在本篇文章中使用它来演示梯度下降算法。接下来,我们研究了梯度,重温了对微分的记忆。最后计算了抛物面函数的偏导数。
我们将文字转化成心智图像,函数 在三维空间中生成一个面。取该面上的任意点 ,我们可以使用梯度(通过它的偏导数)找到一个向量,该向量指向增幅最大方向。
做得很好,但是我们处理的是一个优化问题,对于许多这样的应用来说,通常需要找到全局或局部的最小值。现在,梯度向量向上指向增幅最大的方向。我们需要让这个向量指向相反的方向,这样它就指向减幅最大的方向。
线性代数告诉我们,这样做就像梯度向量乘以 一样简单。另一个巧妙的线性代数技巧是将一个向量乘以 以外的一个数,以改变其大小(长度)。举例来说,如果我们把梯度向量乘以 ,就会得到一个向量,它的长度是原来长度的。
构成梯度下降算法的所有模块终于准备就绪了,该算法最终找到任何给定函数的最接近局部最小值的值。
算法的工作原理如下。
给定一个需要运行梯度下降的函数:
- 获取上的起始位置(以向量表示)
- 计算点处的梯度
- 用梯度乘以负的“步长”(通常小于)
- 通过将重新缩放的梯度向量添加到向量上,计算在表面上的下一个位置
- 使用新的重复步骤2,直到收敛
我们把上述操作变成代码。首先,我们应该定义一个compute_step函数,它以向量和“步长”为参数(我们称之为learning_rate),并根据函数梯度计算的下一个位置:
def compute_step(curr_pos: List[float], learning_rate: float) -> List[float]: grad: List[float] = compute_gradient(curr_pos) grad[0] *= -learning_rate grad[1] *= -learning_rate next_pos: List[float] = [0, 0] next_pos[0] = curr_pos[0] + grad[0] next_pos[1] = curr_pos[1] + grad[1] return next_pos接下来,我们应该定义一个随机的起始位置:
start_pos: List[float]# Ensure that we don't start at a minimum (0, 0 in our case)while True: start_x: float = randint(xs_start, xs_stop) start_y: float = randint(ys_start, ys_stop) if start_x != 0 and start_y != 0: start_pos = [start_x, start_y] breakprint(start_pos)# [6, -3]最后,我们将compute_step函数封装到一个循环中,以迭代方式遍历表面,最终达到局部最小值:
epochs: int = 5000learning_rate: float = 0.001 best_pos: List[float] = start_posfor i in range(0, epochs): next_pos: List[float] = compute_step(best_pos, learning_rate) if i % 500 == 0: print(f'Epoch {i}: {next_pos}') best_pos = next_pos print(f'Best guess for a minimum: {best_pos}')# Epoch 0: [5.988, -2.994]# Epoch 500: [2.2006573940846716, -1.1003286970423358]# Epoch 1000: [0.8087663604107433, -0.4043831802053717]# Epoch 1500: [0.2972307400008091, -0.14861537000040456]# Epoch 2000: [0.10923564223981955, -0.054617821119909774]# Epoch 2500: [0.04014532795468376, -0.02007266397734188]# Epoch 3000: [0.014753859853277982, -0.007376929926638991]# Epoch 3500: [0.005422209548664845, -0.0027111047743324226]# Epoch 4000: [0.0019927230353282872, -0.0009963615176641436]# Epoch 4500: [0.0007323481432962652, -0.0003661740716481326]# Best guess for a minimum: [0.00026968555624761565, -0.00013484277812380783]大功告成了。我们已经成功地实现了从零基础开始的梯度下降算法!
结论
梯度下降算法是一种广泛应用于机器学习的基本优化算法。它被用于算法预测中误差的最小化,因而成为算法“学习”的核心。
在这篇文章中,我们剖析了梯度下降算法的所有不同的部分,研究了数学公式并将其用代码来表达。在我们的例子中,这些代码可以用来求抛物面函数的全局最小值。请注意,这里的优化不是为了提高性能,而是为了可读性和学习的有用性。你可能不需要在生产中使用此代码。
现代机器学习库,如TensorFlow或PyTorch,具有自动计算偏导数的内置微分功能,无需自己进行繁琐的数学运算。
我希望这篇文章对你有所帮助,并揭示了你在日常项目中使用的机器学习库的内部工作原理。
原文链接:https://philippmuens.com/gradient-descent-from-scratch/
阅读更多精彩文章















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









