






 本文介绍了如何使用按键精灵抓取网页指定的文字,包括处理无特征值的文本元素,以及如何获取并保存网页中的图片。通过HtmlGet命令获取元素信息,结合InStr、Mid等函数过滤和提取文本,实现网页内容的提取。此外,还讲解了如何保存静态与动态图片的方法。
本文介绍了如何使用按键精灵抓取网页指定的文字,包括处理无特征值的文本元素,以及如何获取并保存网页中的图片。通过HtmlGet命令获取元素信息,结合InStr、Mid等函数过滤和提取文本,实现网页内容的提取。此外,还讲解了如何保存静态与动态图片的方法。
抓取网页指定内容(资料),获取网页里的图片最近有遇到同学反馈,网页里的那些没有特征值的文本元素不知道怎么获取。以及,不知道怎么获取保存网页里出现的图片。

获取网页指定文字:
目前按键支持的元素特征值有这些: frame(框架) 、id(唯一标识) 、tag(标签) 、type(类型)、txt(文本) 、value(特征) 、index(索引) 、name(名字) 拥有这些特征值的元素才能直接使用HtmlGet命令来获取元素文本信息。
命令名称:HtmlGet获取网页元素的信息
命令功能:获取网页元素指定属性的信息
命令参数:参数1:字符串型,网页元素属性类型:text、html、outerHtml、value、src、href、offset
参数2:字符串型,网页元素特征字符串
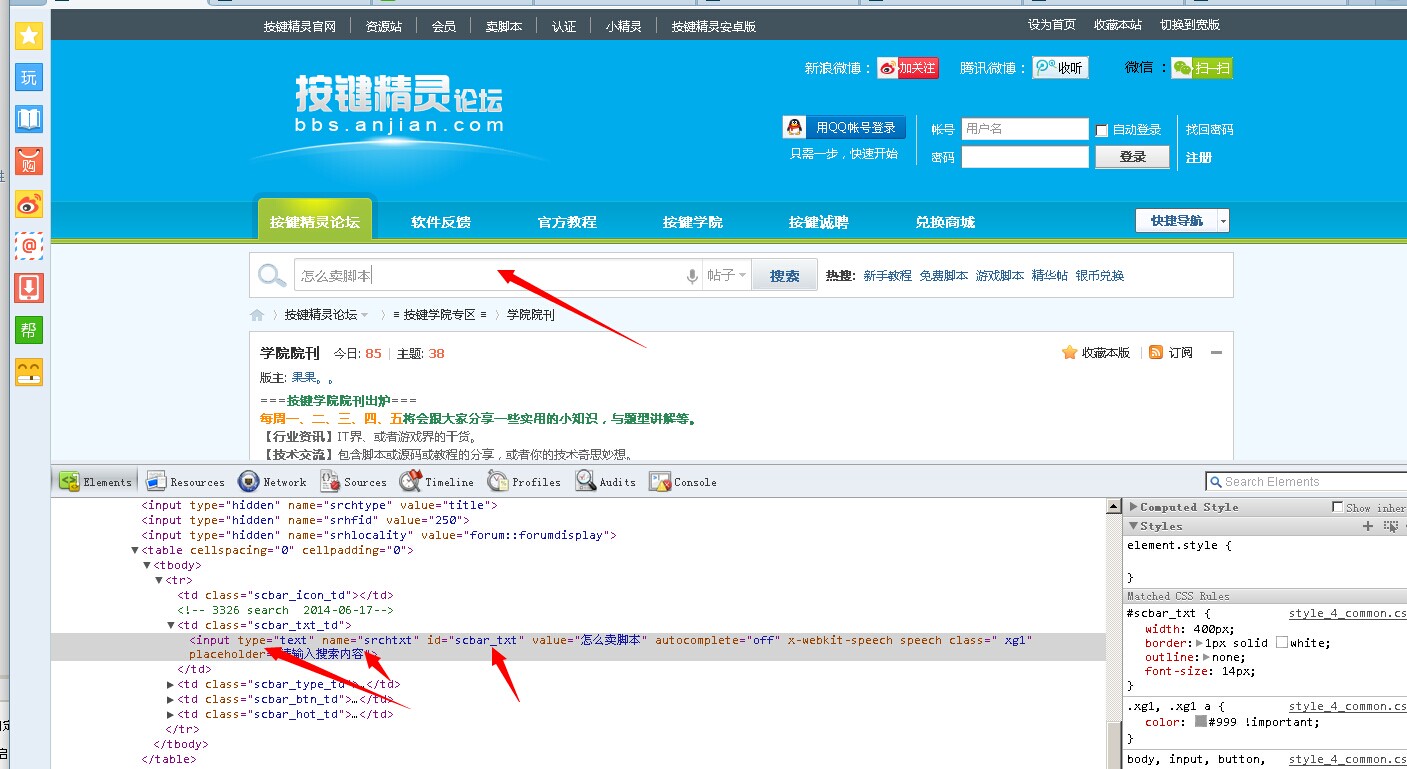
例如下面的例子,按键精灵论坛搜索框,它有type、name、id这三个特征值。

 1.jpg(217.62 K)
1.jpg(217.62 K)
2016/9/8 11:02:10
我们取它id特征值带入到HtmlGet 命令来查看下结果:
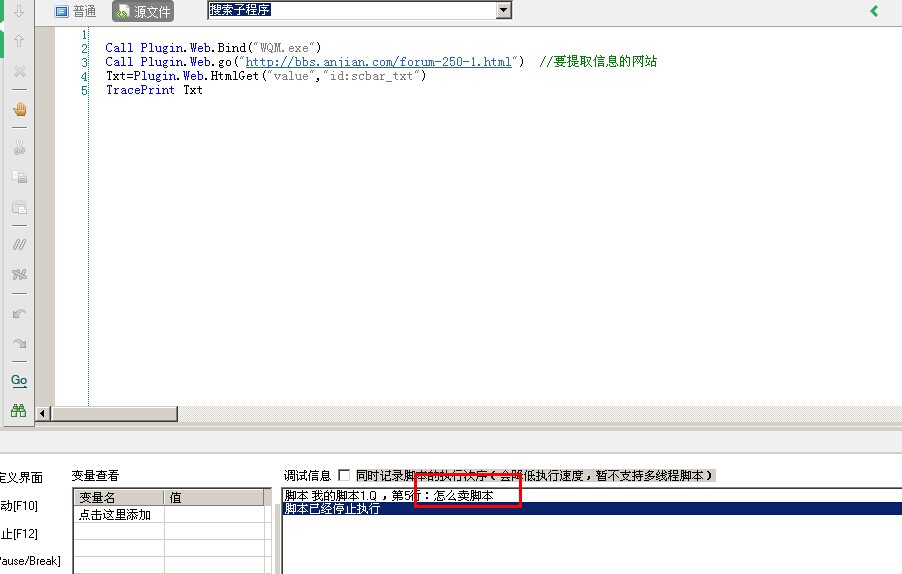
Call Plugin.Web.Bind("WQM.exe")
Call Plugin.Web.go("http://bbs.anjian.com/forum-250-1.html") //要提取信息的网站
Txt=Plugin.Web.HtmlGet("value","id:scbar_txt")
TracePrint Txt复制代码
1.jpg(69.66 K)
2016/9/8 11:02:10
成功获取到了搜索框的value值。
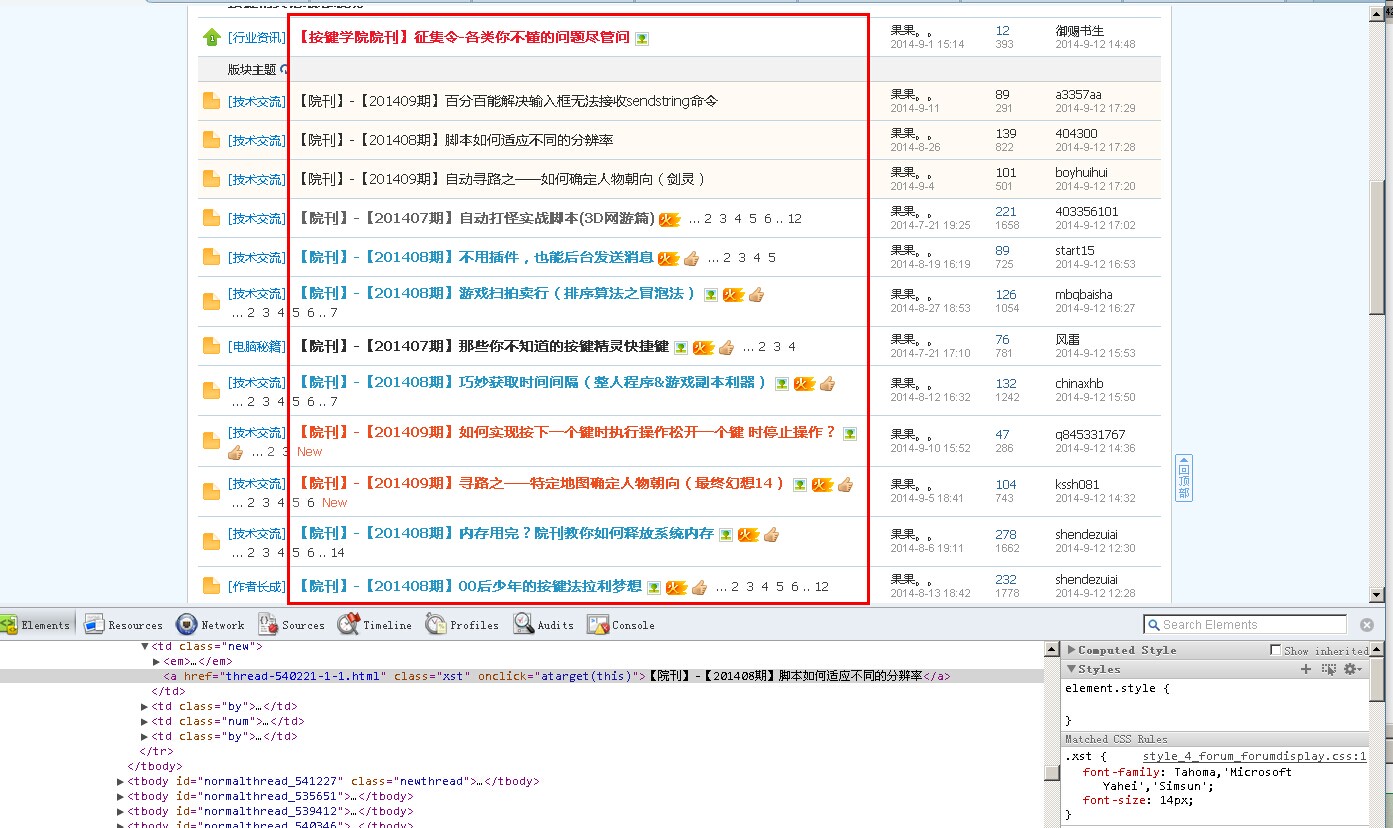
我们现在想要取下面红色区域块的帖子标题,想要把一个页面中的这些帖子名称都取出来。
该怎么办?
1.jpg(275.08 K)
2016/9/8 11:02:10
这些文字,都没有特征值的。我们不能使用特征值的方式去找他们。
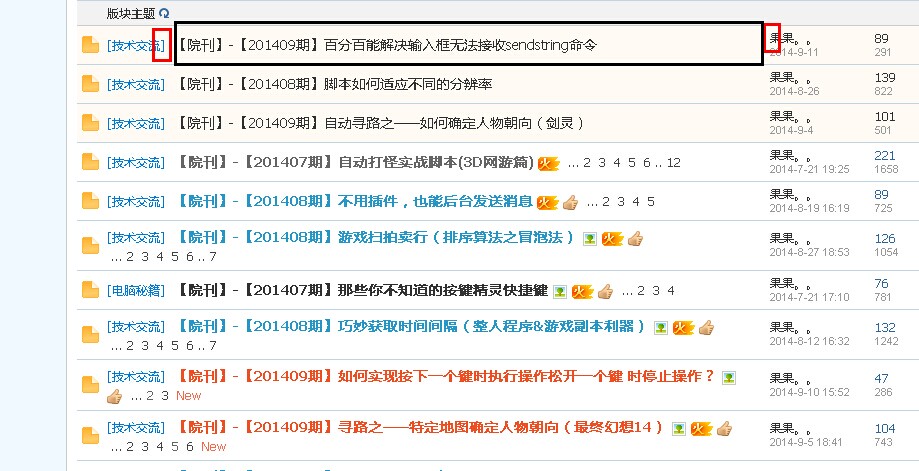
我们可以这样——获取到整个网页的文本之后,去找我们要取的标题,前后不变的字符。
1.jpg(130.39 K)
2016/9/8 11:02:10
大家会发现,这个页面中,帖子标题前后不便的字符是:“]“和“果果。。“那我们就将”]“字符前面的文本都过滤掉,“果果。。“后面的文本也过率掉,这样就能得到我们所需要的文本。
首先,我们需要复习下几个函数:InStr函数描述
start可选的。规定每次搜索的起始位置。默认是搜索起始位置是第一个字符。如果已规定compare参数,则必须有此参数。
string1必需的。需要被搜索的字符串。
string2必需的。需搜索的字符串。
compare必需的。规定要使用的字符串比较类型。默认是0。可采用下列值:0= vbBinaryCompare -执行二进制比较。1 = vbTextCompare -执行文本比较。
Mid函数描述
string必需的。从其中返回字符的字符串表达式。如果字符串包含Null,则返回Null。
start必需的。规定起始位置。如果设置为大于字符串中的字符数目,则返回空字符串("")。
length可选的。要返回的字符数目。如果省略或length超过文本的字符数,将返回字符串中从start到字符串结 束的所有字符。
Len函数描述
string任意有效的字符串表达式。如果 string 参数包含Null,则返回 Null。
varname任意有效的变量名。如果 varname参数包含 Null,则返回 Null。
脚本过程:
1.先打开一个要提取信息的网站。
2.用 HtmlGet 命令 获取整个网页的文本信息,存到Txt变量里面
3.过滤]符号前面的文本
4.从文本里的"]"符号后面的位置开始取字符串,这里取了一百个字符放到命名为cc的变量里。如下图,也可以设置取80个字符,60个字符,但是长度一定要把“果果。。” 给截进来,因为后面我们要通过“果果。。”作为基准,去过滤掉不要的文字。

1.jpg(65.96 K)
2016/9/8 11:02:10
5.在cc变量里,找果果。。出现的位置,找到之后,截取“果果。。”之前的文本,也就是我们需要接取的地方。
6.最后,设置叠加的变量x,把每次找到的"]" 这个符号的位置放到变量x里进行累加,累加之后第二次循环,就会跳过之前找过的内容,进行新的内容的寻找。
源码:
Call Plugin.Web.Bind("WQM.exe")
Call Plugin.Web.go("http://bbs.anjian.com/forum-250-1.html") //要提取信息的网站
Delay 1000 // 如果网页打开速度慢,可适当添加延迟
Txt =Plugin.Web.HtmlGet("text","") //获取网页的文本
x=1
Do
aa = "]" //过滤]符号前面的文本
bb = InStr(x, Txt, aa) // 返回aa变量里的"["这个字符 在整个网页文本txt里的位置
cc = Mid(Txt, bb + Len(aa), 100)//从文本里的"]"符号后面的位置开始取字符串,这里取了一百个字符
dd = InStr(1, cc, "果果。。")//找cc字符串里,果果。。出现的位置,果果。。的位置就是我们要接取的字符串的长度
ee = Mid(cc, 1, dd)//从文本里cc里第一个字符开始,取到果果。。文字出现的位置
If Len(ee) <> 0 Then //判断有没有取到匹配的字符
pp = Left(ee, Len(ee)-1) //如果有取到,我们还要做下处理,因为前面ee字符串是取到了果果。。出现的位置,所以果字也被取了,我们这里长度-1,去掉果字
TracePrint pp
x = InStr(x, Txt, pp) //这里做个记号,把每次找到的"]" 这个符号的位置进行累加,累加之后第二次循环,就会跳过之前找过的内容,进行新的内容的寻找。
Else
Exit Do //如果没有找到匹配的 就退出
End If
Loop复制代码
最终效果:
1.jpg(170.42 K)
2016/9/8 11:02:10
标题后面的?…234这样的字符是帖子总回帖的页数
获取网页图片
我们截图按键精灵官网的图标:

1.jpg(9.33 K)
2016/9/8 11:02:10
1.jpg(173.20 K)
2016/9/8 11:02:10
我们可以查看图片的具体地址
代码如下:
Call Plugin.Web.Bind("WQM.exe")
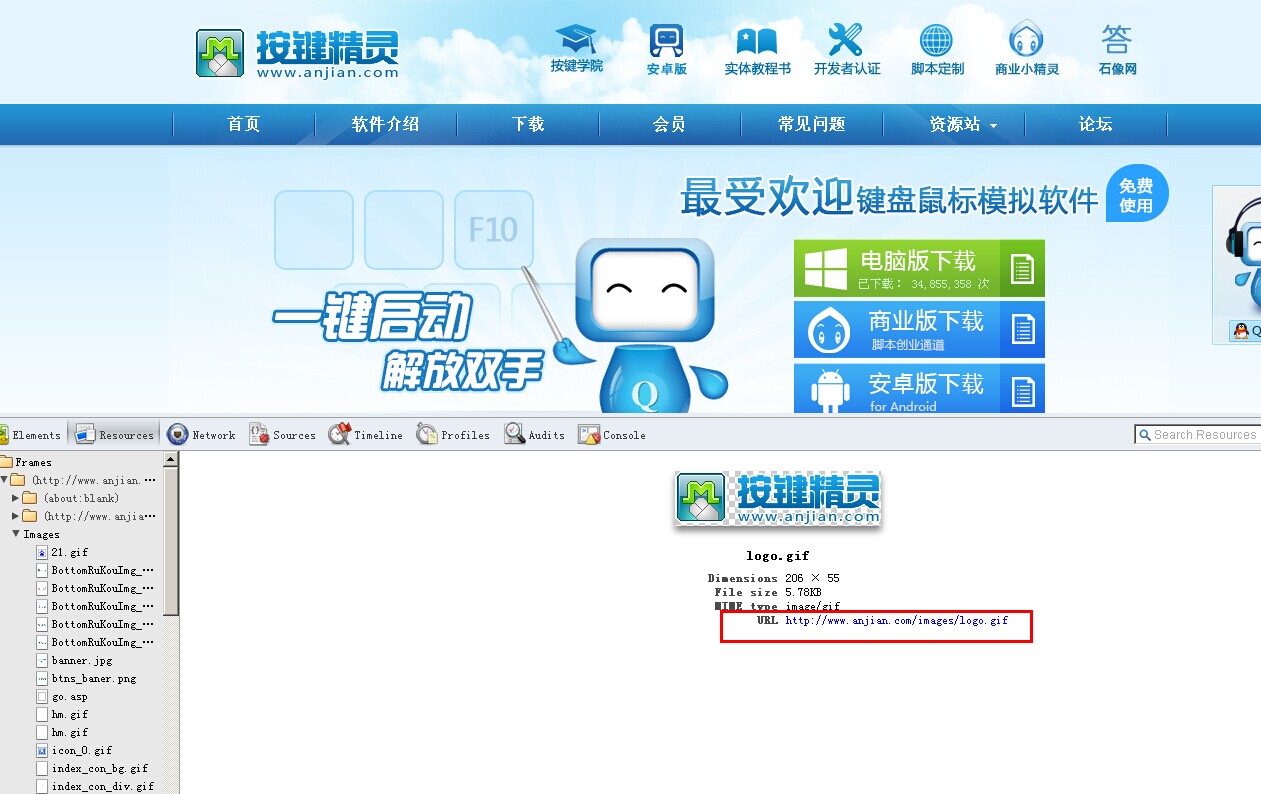
Call Plugin.Web.Go("http://www.anjian.com") //打开按键官网地址
Call Plugin.Web.Save("http://www.anjian.com/images/logo.gif", "d:\123.gif")
Delay 3000
RunApp "mspaint.exe"&" d:\123.gif" //打开画图工具,看看保存的图片的效果复制代码命令名称:Save保存网页或图片
命令功能:保存指定URL的文件到本地磁盘
命令参数:参数1:字符串型,需要保存的目标Url参数2:字符串型,本地文件名
最终效果:

1.jpg(150.99 K)
2016/9/8 11:02:10
大家有没有注意到,这里的按键精灵官网图标,是gif格式的,可以保存。如果是一个链接呢?
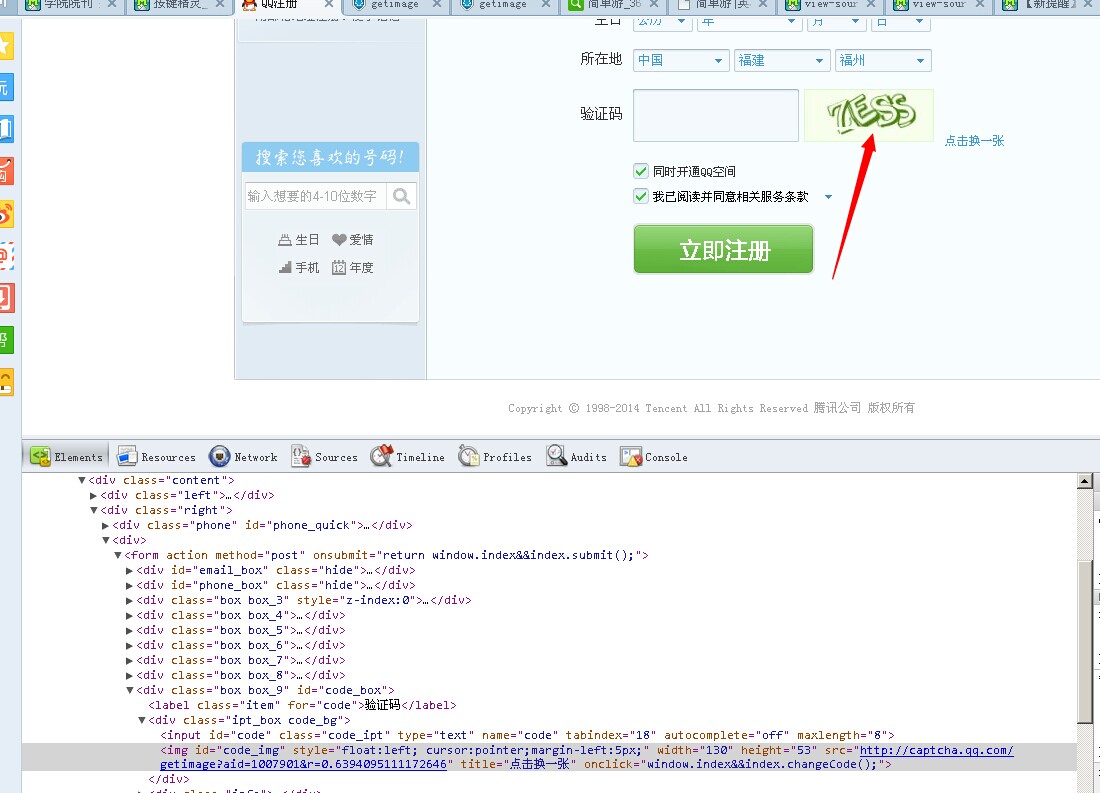
例如,腾讯QQ注册页面里的这种验证图片:
2.jpg(154.34 K)
2016/9/8 11:02:10
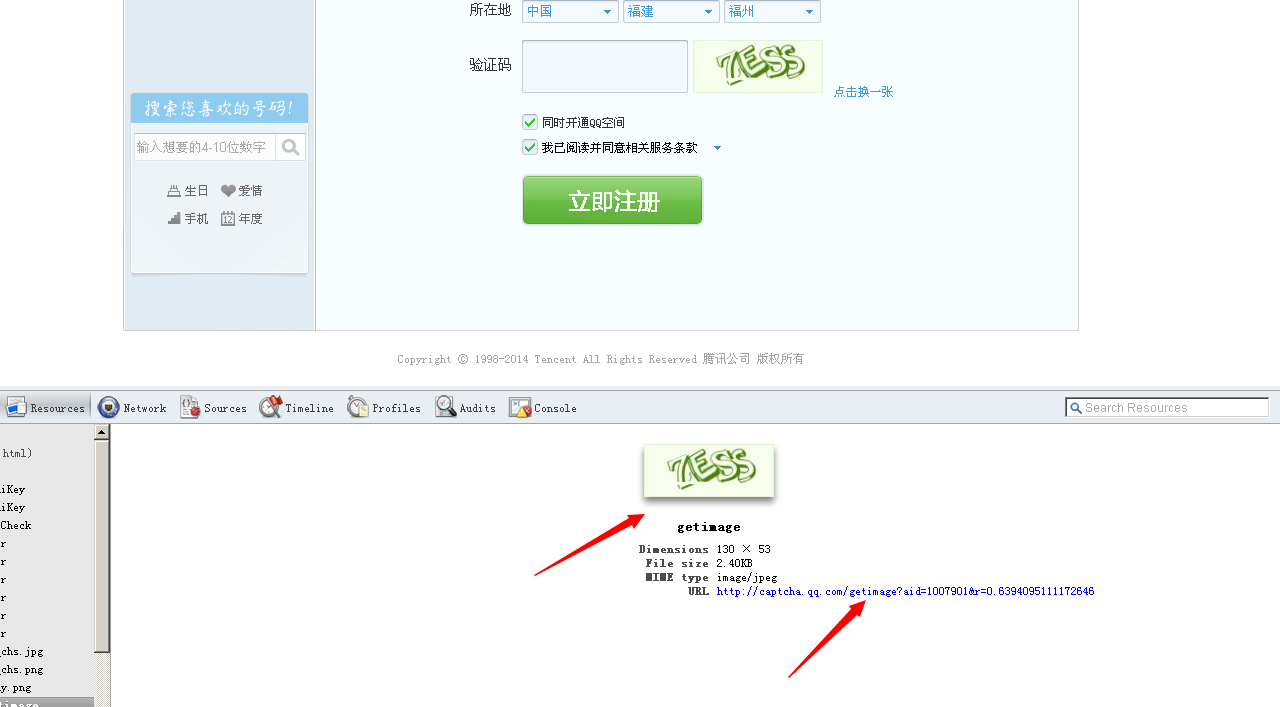
大家看,它的图片是保存在一个链接里的,这样就无法获取。
3.png(58.92 K)
2016/9/8 11:02:10
地址是没有变化的,但是点击进去之后,生成的就是另一张验证图片了。
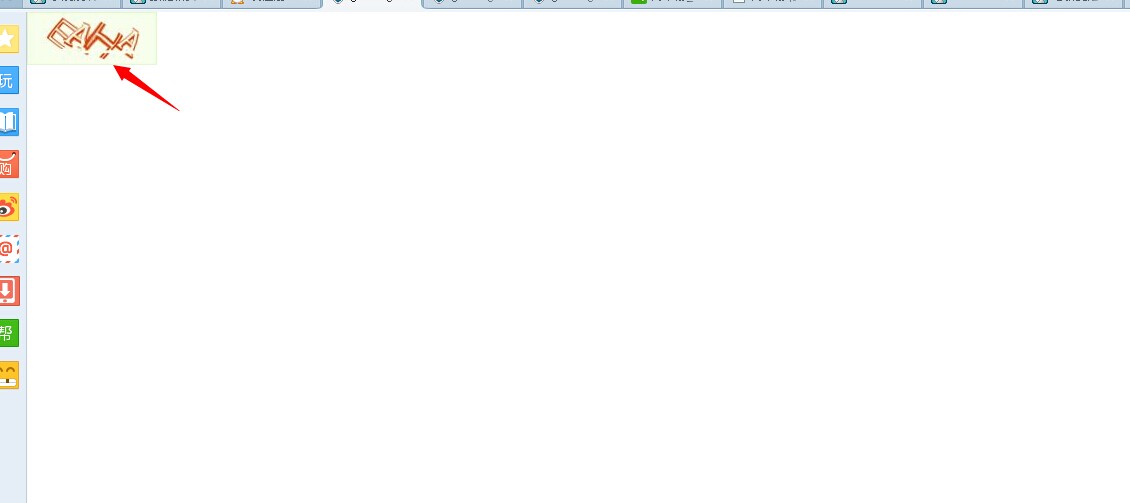
4.jpg(23.81 K)
2016/9/8 11:02:10
所以,遇到这种链接方式的图片,大家还是使用查找图片的区域坐标,然后用屏幕范围截图命令来截图保存:
//下面这句在屏幕区域范围内截图保存到(内存)里,以备后面调用。
Call Plugin.ColorEx.PrintScreen(0, 0, 1024, 768)
//下面这句在屏幕区域范围内按方式0,查找颜色,返回左上角第一点颜色位置坐标
XY = Plugin.ColorEx.FindColor(0, 0, 1024, 768, "0000FF", 1, 0)
//下面这句用于分割字符串
ZB = InStr(XY, "|")
//下面这句将字符串转换成数值
X = Clng(Left(XY, ZB - 1)): Y = Clng(Right(XY, Len(XY) - ZB))
//释放屏幕截图信息时请使用以下命令
Call Plugin.ColorEx.Free()复制代码
 本文由按键学院提供技术支持
本文由按键学院提供技术支持

















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









