






在人工智能技术飞速发展的当下,如何高效地管理和利用海量信息成为关键问题。基于检索增强生成(Retrieval-Augmented Generation,RAG)技术的解决方案应运而生,而 RAGFlow 作为其中极具潜力的工具,为搭建智能知识库提供了全新思路。接下来,我们将深入了解 RAGFlow,掌握从 0 到 1 搭建 RAG 知识库的方法。
一、RAGFlow 的定义
RAGFlow 是一款专注于检索增强生成技术落地的开源框架,旨在简化 RAG 系统的搭建与部署流程。它以模块化、可扩展的设计理念,整合了数据处理、检索、生成等多个核心环节,为开发者提供了一站式的 RAG 解决方案。通过 RAGFlow,用户无需深入复杂的底层技术细节,就能快速构建出适配不同业务场景的 RAG 知识库,实现基于大规模文本数据的智能问答、内容生成等功能。
二、RAGFlow 的特点
(一)高度模块化
RAGFlow 将 RAG 系统拆分为数据摄取、数据预处理、向量存储、检索模块、生成模型等多个独立模块。每个模块都有明确的功能和接口,开发者可以根据实际需求,灵活选择和替换不同模块。例如,在向量存储部分,既可以选择常用的 Chroma、Milvus 等开源向量数据库,也可以接入企业内部已有的存储系统,极大地提升了系统的适配性。
(二)易于扩展
随着业务的发展和技术的更新,RAGFlow 支持轻松扩展新的功能。无论是引入新的预训练模型,还是增加自定义的数据处理逻辑,都能通过简单的配置和代码修改实现。这种扩展性使得 RAG 知识库能够不断进化,持续满足企业日益增长的智能化需求。
(三)高效性能
在数据处理和检索环节,RAGFlow 采用了一系列优化策略。例如,在数据预处理阶段,利用多线程和并行计算技术加速文本清洗、分词等操作;在检索过程中,结合语义检索和关键词检索,快速定位相关信息,减少响应时间,为用户提供高效的交互体验。
(四)低门槛使用
对于没有深厚 AI 技术背景的开发者和企业来说,RAGFlow 提供了友好的操作界面和丰富的文档资源。通过简单的配置和少量的代码编写,就能完成 RAG 知识库的搭建,降低了技术使用门槛,让更多人能够享受到 RAG 技术带来的便利。
三、RAGFlow 应用场景
(一)智能客服
在企业客服场景中,RAGFlow 搭建的知识库可以整合产品手册、常见问题解答、历史服务记录等大量数据。当用户咨询问题时,系统快速检索相关信息,并结合生成模型生成准确、自然的回答,提升客服效率和服务质量,同时减少人工客服的工作压力。
(二)知识问答平台
针对教育、金融、医疗等领域的专业知识问答平台,RAGFlow 能够处理领域内复杂的专业文档和知识图谱。无论是学生的学科问题,还是投资者的金融咨询,或是患者的医疗疑问,系统都能基于知识库给出专业、可靠的答案,成为用户获取知识的得力助手。
(三)内容生成
在新闻写作、文案创作、报告生成等场景下,RAGFlow 可以根据用户输入的主题和要求,从知识库中检索相关素材,并辅助生成高质量的内容。例如,新闻工作者可以利用它快速收集事件背景资料,生成新闻稿件初稿,提高创作效率。
(四)企业内部知识管理
企业内部往往积累了大量的技术文档、项目经验、规章制度等知识资产。通过 RAGFlow 搭建的知识库,员工可以快速检索到所需信息,促进知识共享和传承,提升企业整体的协作效率和创新能力。
四、RAGFlow 系统架构
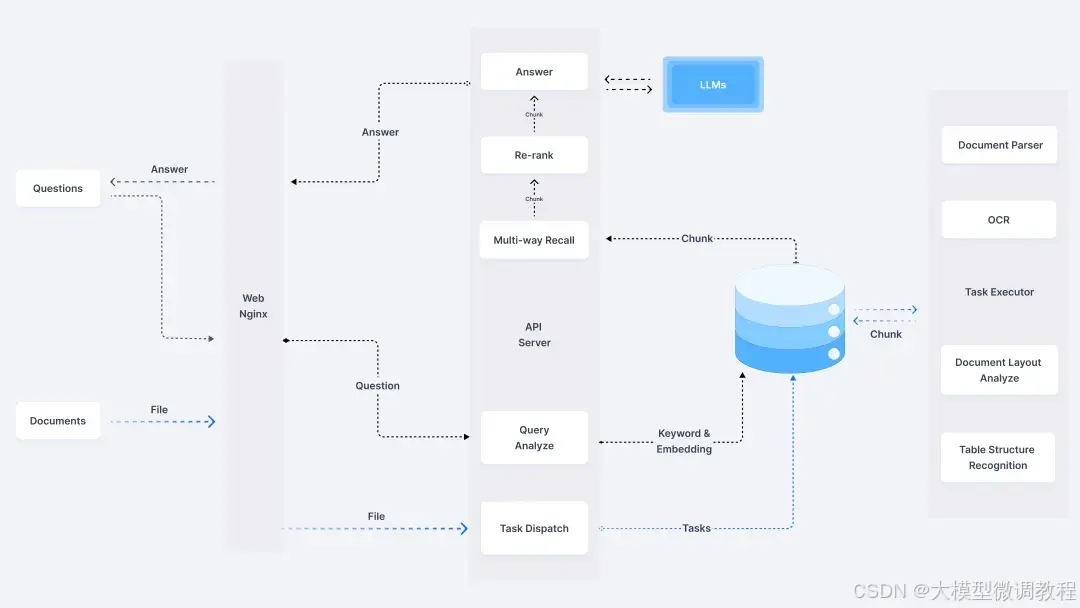
(一)数据层
数据层是 RAGFlow 的基础,负责数据的采集和存储。它支持从多种数据源获取数据,如本地文件(PDF、Word、Excel 等)、数据库、网页、云端存储等。采集到的数据会被存储在原始数据仓库中,等待进一步处理。
(二)处理层
-
数据预处理:对原始数据进行清洗、去重、格式转换等操作,提取关键文本信息。同时,利用自然语言处理技术进行分词、词性标注、命名实体识别等,为后续的向量表示做准备。
-
向量生成:将处理后的文本数据转换为向量形式,常用的方法是通过预训练的语言模型(如 BERT、GPT 等)生成文本嵌入向量,并将这些向量存储到向量数据库中,建立文本与向量的映射关系。
(三)检索层
检索层负责根据用户输入的问题,在向量数据库中检索相关信息。它采用语义检索和关键词检索相结合的方式,首先通过语义模型计算问题与知识库中文本的语义相似度,筛选出最相关的文本片段;然后结合关键词匹配,进一步缩小检索范围,提高检索的准确性和召回率。
(四)生成层
生成层基于检索到的相关信息和用户问题,利用预训练的生成模型(如 GPT 系列、LLaMA 等)生成回答。生成过程中,模型会结合检索内容的语义和逻辑,生成连贯、准确的自然语言回答,确保答案的质量和实用性。
(五)交互层
交互层是用户与 RAG 知识库的接口,它提供了多样化的交互方式,如 Web 界面、API 接口、移动端应用等。用户可以通过这些接口输入问题,获取回答,并对回答进行反馈,以便系统不断优化和改进。
以上全面介绍了 RAGFlow 相关知识和搭建 RAG 知识库的方法。若你对搭建过程有
五、环境准备与系统搭建
1、环境需求
在搭建RAGFlow系统前,需要确保开发与运行环境满足以下要求:
- 硬件配置:建议采用多核CPU、充足内存(16GB及以上)以及支持高并发访问的存储设备;如需部署大规模检索服务,可考虑使用分布式存储集群。
- 操作系统:推荐使用Linux发行版(如CentOS、Ubuntu)以便于Shell脚本自动化管理;同时也支持Windows环境,但在部署自动化脚本时可能需要适当调整。
- 开发语言与工具:主要使用Java进行系统核心模块开发,同时结合Shell脚本实现自动化运维。
- 依赖环境:需要安装Java 8及以上版本,同时配置Maven或Gradle进行依赖管理;对于数据检索部分,可采用ElasticSearch、Apache Solr等开源检索引擎;生成模块则依赖于预训练模型,可以借助TensorFlow或PyTorch进行实现。
2、服务器配置
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
3、安装
修改 max_map_count
确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
$ sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置:
# 这里我们设为 262144:
$ sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
下载仓库代码
git clone https://github.com/infiniflow/ragflow.git
Docker拉取镜像
修改镜像为国内镜像并且选择embedding版本
修改文件docker/.env/
默认配置为:RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim
修改为国内镜像:RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.16.0
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|---|---|---|---|
| v0.16.0 | ≈9 | ✔️ | Stable release |
| v0.16.0-slim | ≈2 | ❌ | Stable release |
| nightly | ≈9 | ✔️ | Unstable nightly build |
| nightly-slim | ≈2 | ❌ | Unstable nightly build |
运行命令拉取镜像
docker compose -f docker/docker-compose.yml up -d
 查看日志
查看日志
docker logs -f ragflow-server
提示下面提示说明启动成功
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
访问IP,进入 RAGFlow,注意不是 9380 端口,Web是http://127.0.01默认为 80 端口
六、应用
注册账号
注册完直接登录
添加模型
本文用到的模型类型:Chat 和 Embedding。 Rerank 模型等后续在详细介绍。
点击右上角->模型提供商->添加模型
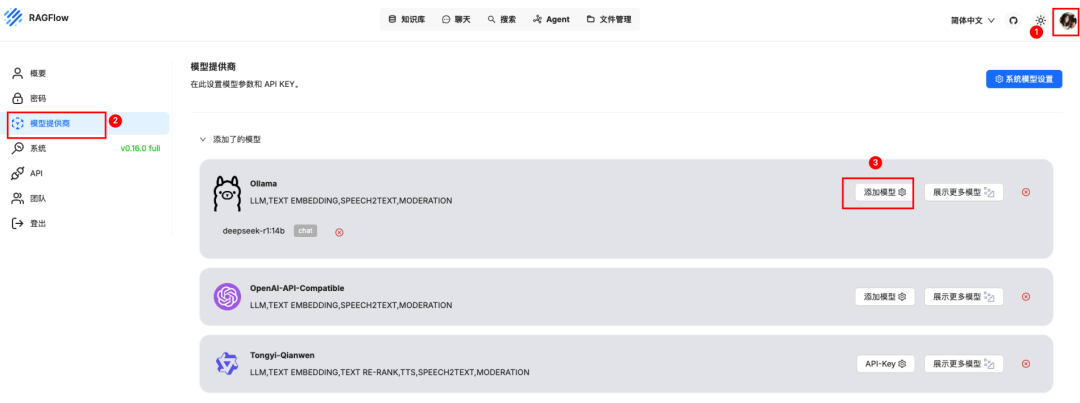
填写模型信息,模型类型选 chat
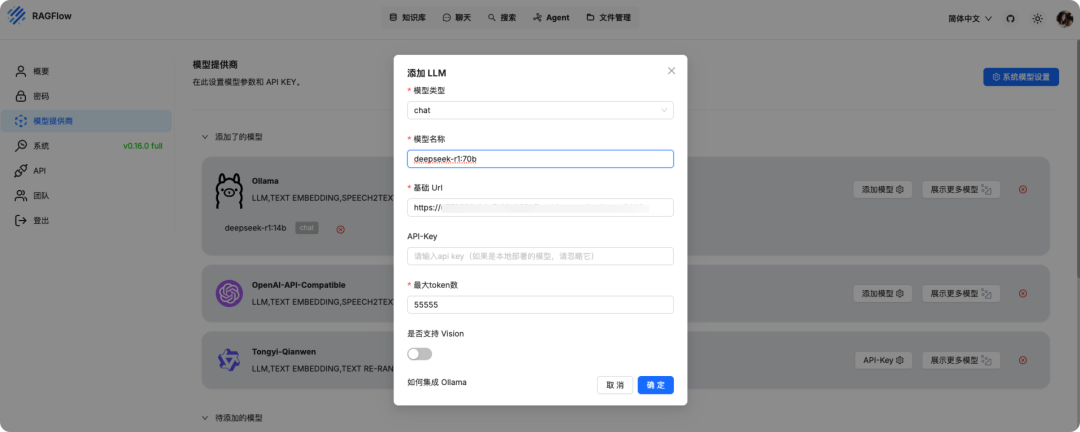
再添加一个 Embedding 模型用于知识库的向量转换(RAGFlow 默认也有 Embedding)
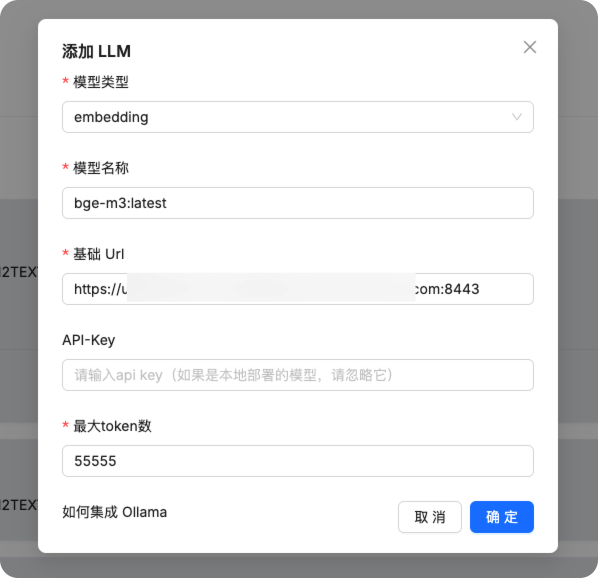
在系统模型设置中配置聊天模型和嵌入模型为我们刚刚添加的模型
创建知识库

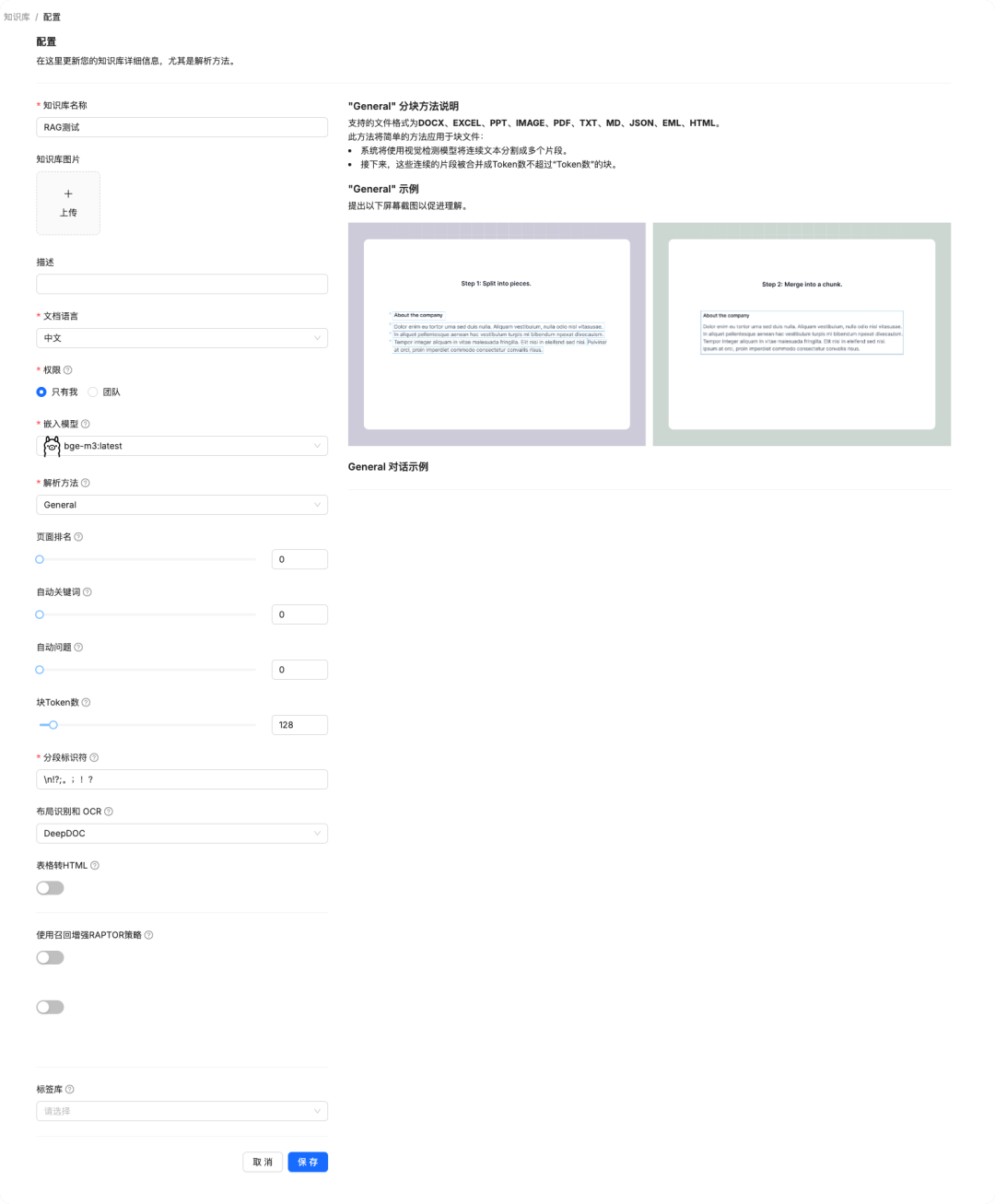
填写相关配置
- 文档语言:中文
- 嵌入模型:选择我们自己运行的
bge-m3:latest,也可以用默认的。具体效果大家自行评估
上传文件
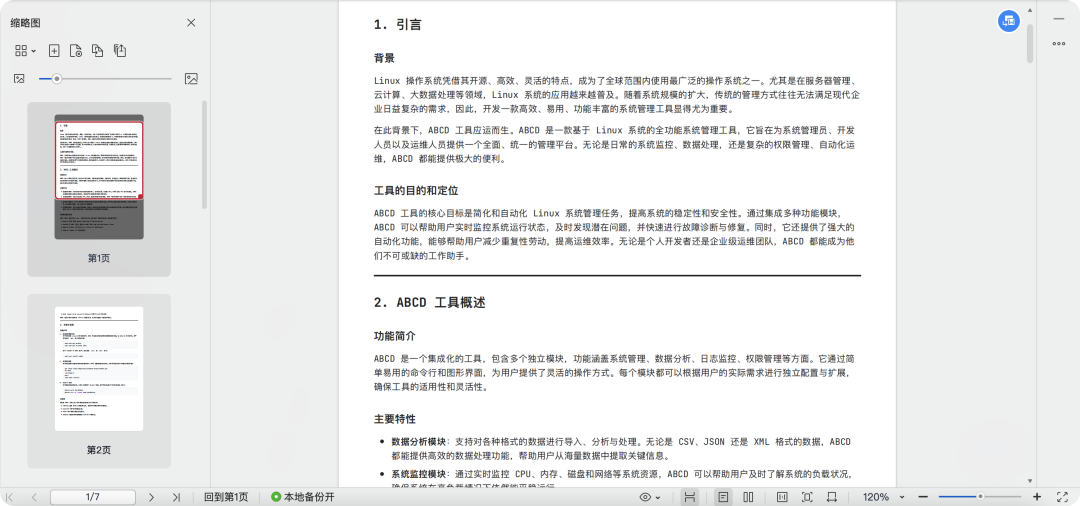
这里我自己造了一个测试文档来验证知识库,内容是编的,介绍一个 ABCD 工具,文档在文末提供下载。
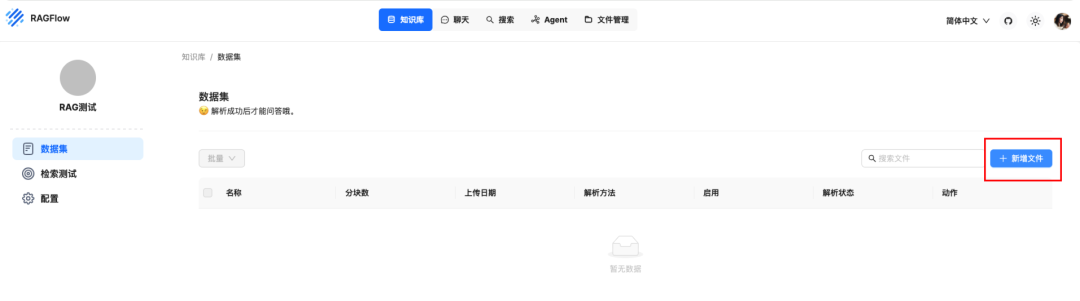
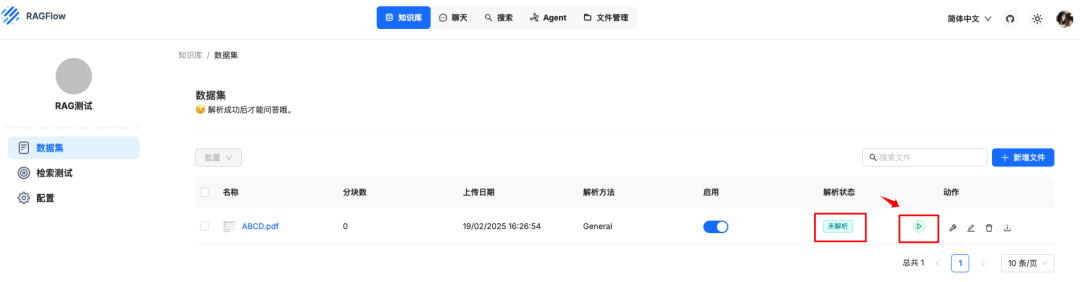
文件上传后是未解析状态,需要解析才可以使用,点击解析
解析成功后点击文件可以看到解析效果
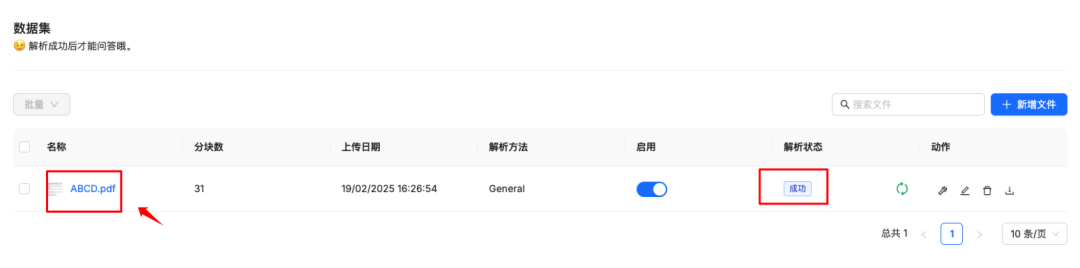
效果

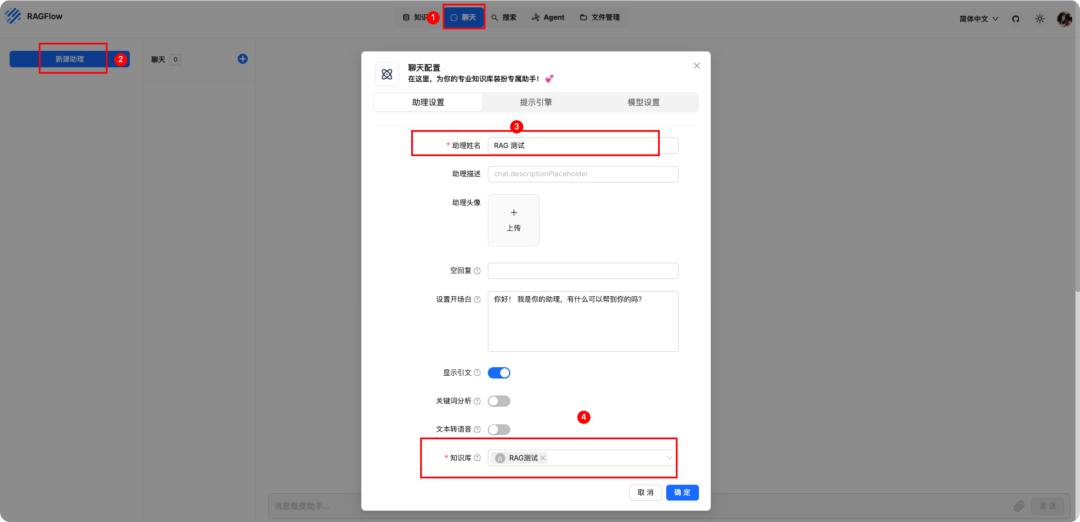
创建聊天
设置模型。token 调整大一些
验证效果
问题一:直接发送 ABCD
知识库回答
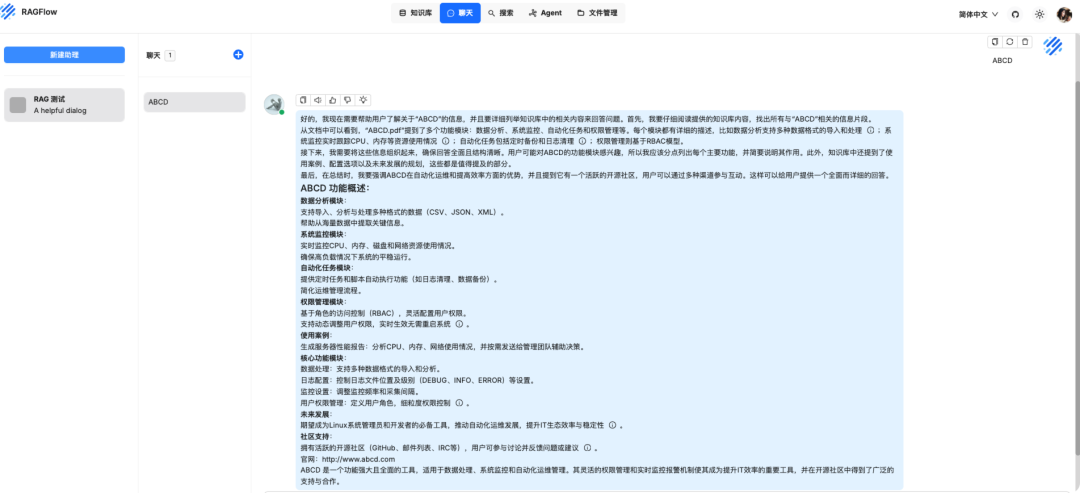
原文档

问题二:ABCD 错误代码有哪些
知识库回答
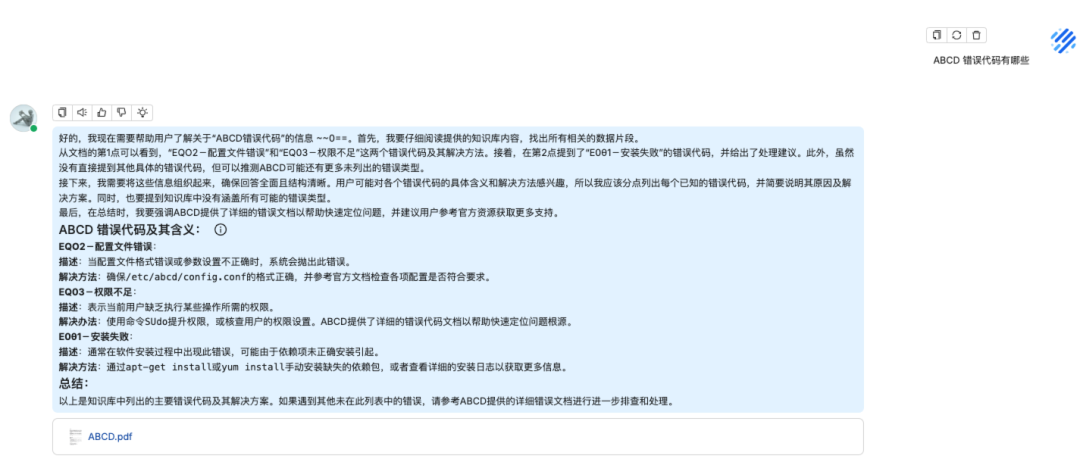
原文档

问题三:ABCD 支持哪些系统
知识库回答
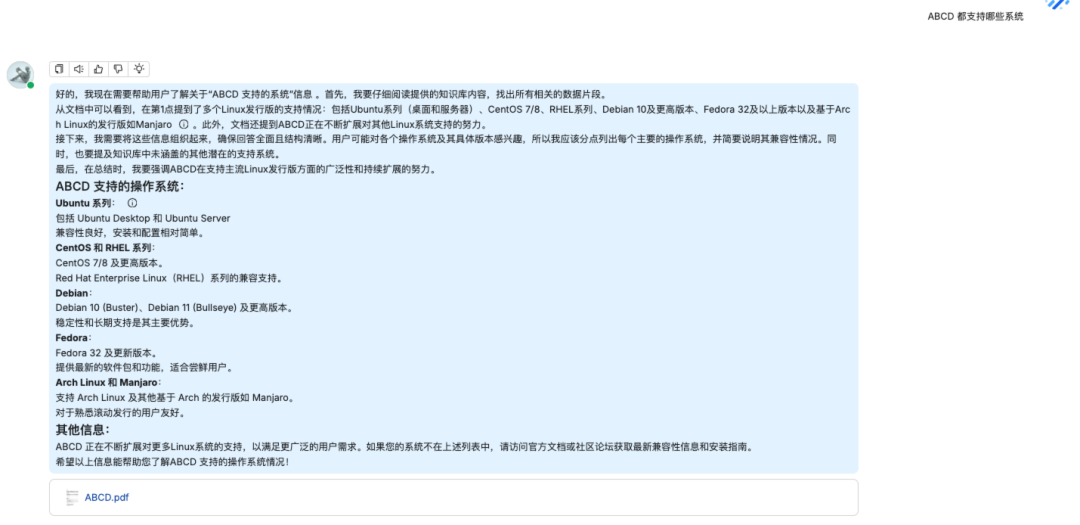
原文档
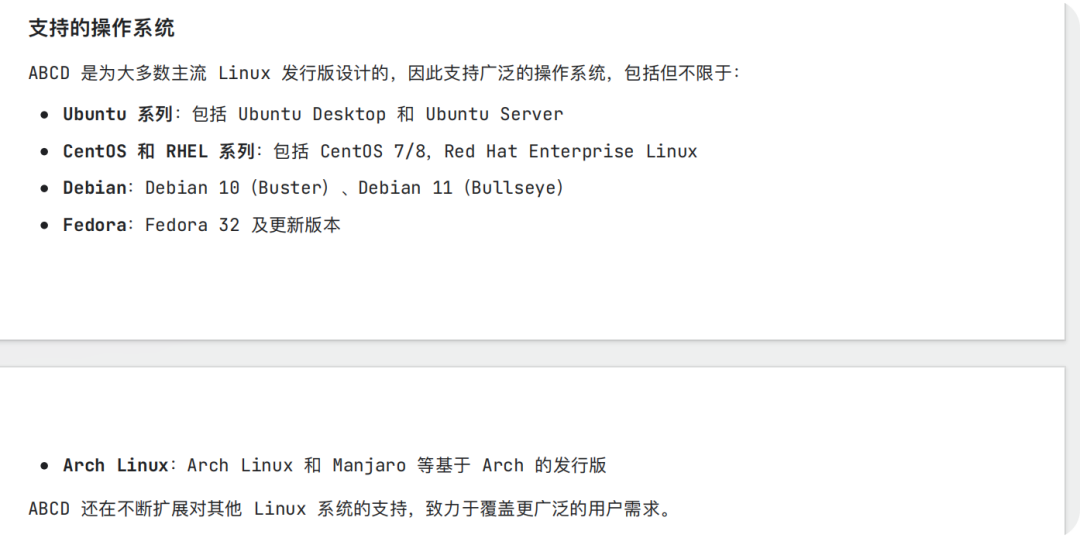
问题四:ABCD 官网
知识库回答
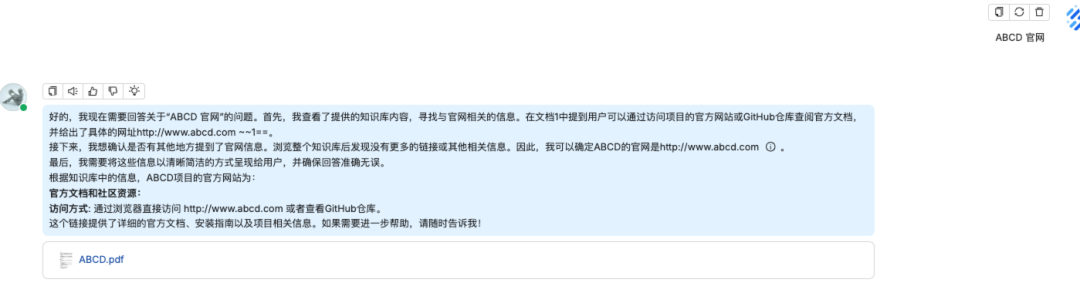
你也可以在回答的结果看到他引用的知识库
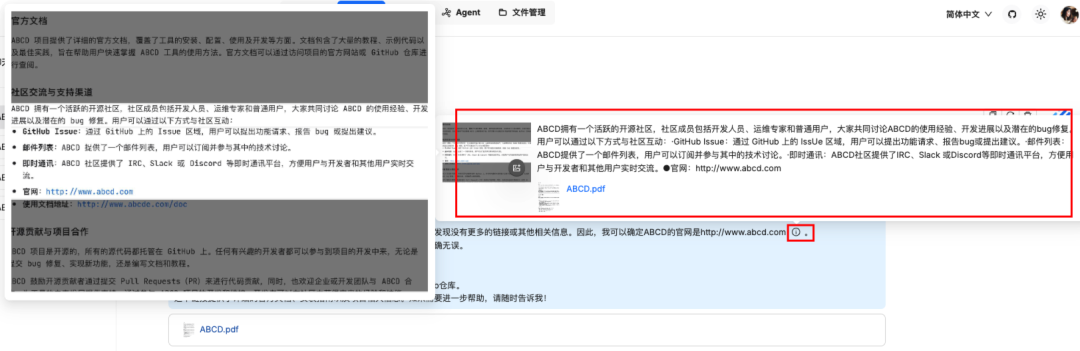
原文档

总结
本文介绍了 RAGFlow 的基础使用方法,从演示效果来看尚可。然而,在实际应用场景中,各类文件格式与结构各不相同,文件解析成为一大难题。一旦解析不准确,即便使用性能强劲的 Deepseek-R1 大模型(经亲测),也会出现分析错误的情况。因此,在 RAG 过程中,文件解析、Embedding 以及 LLM 是提升准确率的三大关键攻克点。疑问,或想了解更多 RAGFlow 的进阶应用,欢迎和我交流。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 3533
3533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









