







继续上一节的内容,当我们生成了KD树之后,下一步就是预测测试集中的样本目标点。对于查找样本目标点,我们首先要找到该目标点的叶子节点,然后以目标点为圆心,目标点到叶子节点的距离为半径,建立一个超球体,我们要找寻的最近邻点一定是在该球体内部。接着返回叶子结点的父节点,检查另一个子结点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。如果不相交直接返回父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。
KD树的划分可以减少无谓的最近邻搜索,下面我们举一个例子来说明KD树是如何对点(2,4.5)进行最近邻点的查找的。
我们用昨天内容讲的那颗KD树进行查找,首先是二叉查找,从(7,2)查找到(5,4)节点,在进行查找时是由y=4为分割超平面的,由于查找点y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但(4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点;接下来以目标点(2,4.5)为圆心,以3.041为半径作圆,可见该圆和y=4超平面交割,所以需要进行(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得到<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离点(2,4.5)比(5,4)要近。所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直至最后回溯到根节点(7,2),以(2,4.5)为圆心,以1.5为半径作圆,并不和x=7超平面交割。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5,如下图所示:
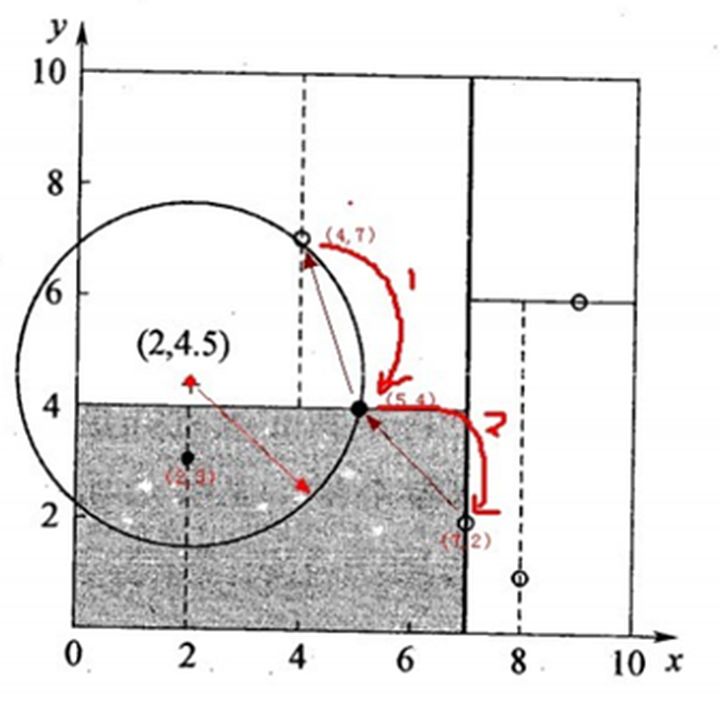
KNN算法之树球实现
KD树在一定程度上可以提高KNN搜索效率,但是在处理不均匀分布数据集(矩形或者类矩形)时并不合适,为了优化矩形体导致的搜索效率问题,有学者提出了球树结构。接下来我们来介绍一下球树。
球树的建立:
球树也就是说每个分割块不是KD树中的超矩形体,而是超球体。
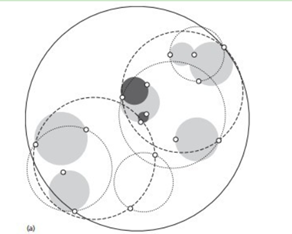
具体的建树流程:
1. 先构建一个超球体,这个超球体是可以包含所有样本的最小球体。
2. 从球中选择一个离球的中心最远的点,然后选择第二个点离第一个点最远,把球中素有的点分配到离这两个聚类中心最近的一个点上,然后计算每个聚类的中心,以及聚类能够包含它所有数据点所需的最小半径。这样就得到了两个子超球体,和KD树中的左右子树相对应。
3. 递归执行步骤2,最终得到了一个球体
观察上面的步骤,其实不难发现,KD树和球树类似,主要区别是球树得到的节点样本组成的最小超球体,而KD树得到的是节点样本组成的超矩形体,这个超球体要与对应的KD树的超矩形体小,这样我们在做最近邻搜索的时候就可以避免一些无谓的搜索。
球树搜索最近邻
使用球树找出给定目标的点的最近邻方法先是自上而下贯穿整棵树找出包含目标点所在的叶子,并在这个树里面找出与目标点最邻近的点,这将确定目标点与距离它最近的临近点的一个上限值,然后再检查兄弟结点,如果目标点到兄弟结点中心的距离超过兄弟结点的半径与当前的上限值之和,那么该点就是最临近的一个点,否则的话进一步检查兄弟结点之下的子树。检查完兄弟节点后,我们向父节点回溯,继续搜索最小邻近值。当回溯到根节点时,此时的最小邻近值就是最终的搜索结果。
KNN算法小结
KNN算法的讲解到这里就已经完结了,KNN算法由于在维度很高的时候也有很好的分类效率,因此运用得很广泛,下面我们总结一下KNN的优缺点:
优点:1.简单易于理解,可以处理分类问题,也适合处理多分类问题。
2.还可以用作预测处理,也就是处理回归问题
缺点:1.当特征很多的时候,计算起来非常复杂。
2.对训练数据依赖度大,如果在训练数据集中有一两个数据预测错误,很可能导致预测的数据不准确。















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









