






第一步:引包(Maven)
org.quartz-scheduler
quartz
2.2.2
第二步:创建要被定执行的任务类
这一步也很简单,只需要创建一个实现了org.quartz.Job接口的类,并实现这个接口的唯一一个方法execute(JobExecutionContext arg0) throws JobExecutionException即可。如:
packagecom.fync.quartz;importjava.text.SimpleDateFormat;importjava.util.Date;importorg.quartz.Job;importorg.quartz.JobExecutionContext;importorg.quartz.JobExecutionException;/*** 创建要被定执行的任务类
*@authorlong
**/
public class MyJob implementsJob{public voidexecute(JobExecutionContext context)throwsJobExecutionException {
SimpleDateFormat sdf= new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
System.out.println(sdf.format(newDate()));
}
}
第三步:创建任务调度,并执行
packagecom.fync.quartz;importorg.quartz.JobBuilder;importorg.quartz.JobDetail;importorg.quartz.Scheduler;importorg.quartz.SchedulerException;importorg.quartz.SchedulerFactory;importorg.quartz.SimpleScheduleBuilder;importorg.quartz.Trigger;importorg.quartz.TriggerBuilder;importorg.quartz.impl.StdSchedulerFactory;/*** 创建任务调度,并执行
*@authorlong
**/
public classMainScheduler {//创建调度器
public static Scheduler getScheduler() throwsSchedulerException{
SchedulerFactory schedulerFactory= newStdSchedulerFactory();returnschedulerFactory.getScheduler();
}public static void schedulerJob() throwsSchedulerException{//创建任务
JobDetail jobDetail = JobBuilder.newJob(MyJob.class).withIdentity("job1", "group1").build();//创建触发器 每3秒钟执行一次
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group3")
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever())
.build();
Scheduler scheduler=getScheduler();//将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);//调度器开始调度任务
scheduler.start();
}public static void main(String[] args) throwsSchedulerException {
MainScheduler mainScheduler= newMainScheduler();
mainScheduler.schedulerJob();
}
}
MainScheduler.main()依次创建了scheduler(调度器)、job(任务)、trigger(触发器),其中,job指定了MyJob,trigger保存job的触发执行策略(每隔3s执行一次),scheduler将job和trigger绑定在一起,最后scheduler.start()启动调度,每隔3s触发执行JobImpl.execute(),
打印出当前时间。
除了SimpleScheduler之外,常用的还有CronTrigger.原理分析:
1、job(任务)
job由若干个class和interface实现。
Job接口
开发者想要job完成什么样的功能,必须且只能由开发者自己动手来编写实现,比如demo中的MyJob,这点无容置疑。但要想让自己的job被quartz识别,就必须按照quartz的规则来办事,这个规则就是job实现类必须实现Job接口,比如MyJob就实现了Job。
Job只有一个execute(JobExecutionContext),JobExecutionContext保存了job的上下文信息,比如绑定的是哪个trigger。job实现类必须重写execute(),执行job实际上就是运行execute()。
2、JobDetailImpl类 / JobDetail接口
JobDetailImpl类实现了JobDetail接口,用来描述一个job,定义了job所有属性及其get/set方法。了解job拥有哪些属性,就能知道quartz能提供什么样的能力,下面用表格列出job若干核心属性。
属性名说明
class
必须是job实现类(比如JobImpl),用来绑定一个具体job
name
job名称。如果未指定,会自动分配一个唯一名称。所有job都必须拥有一个唯一name,如果两个job的name重复,则只有最前面的job能被调度
group
job所属的组名
description
job描述
durability
是否持久化。如果job设置为非持久,当没有活跃的trigger与之关联的时候,job会自动从scheduler中删除。也就是说,非持久job的生命期是由trigger的存在与否决定的
shouldRecover
是否可恢复。如果job设置为可恢复,一旦job执行时scheduler发生hard shutdown(比如进程崩溃或关机),当scheduler重启后,该job会被重新执行
jobDataMap
除了上面常规属性外,用户可以把任意kv数据存入jobDataMap,实现job属性的无限制扩展,执行job时可以使用这些属性数据。此属性的类型是JobDataMap,实现了Serializable接口,可做跨平台的序列化传输
3、JobBuilder类
JobDetail jobDetail = JobBuilder.newJob(MyJob.class).withIdentity("job1", "group1").build();
上面代码是demo一个片段,可以看出JobBuilder类的作用:接收job实现类MyJob,生成JobDetail实例,默认生成JobDetailImpl实例。
这里运用了建造者模式:JobImpl相当于Product;JobDetail相当于Builder,拥有job的各种属性及其get/set方法;JobBuilder相当于Director,可为一个job组装各种属性。
4、trigger(触发器)
trigger由若干个class和interface实现。
SimpleTriggerImpl类 / SimpleTrigger接口 / Trigger接口
SimpleTriggerImpl类实现了SimpleTrigger接口,SimpleTrigger接口继承了Trigger接口,它们表示触发器,用来保存触发job的策略,比如每隔几秒触发job。实际上,quartz有两大触发器:SimpleTrigger和CronTrigger,限于篇幅,本文仅介绍SimpleTrigger。
Trigger诸类保存了trigger所有属性,同job属性一样,了解trigger属性有助于我们了解quartz能提供什么样的能力,下面用表格列出trigger若干核心属性。
在quartz源码或注释中,经常使用fire(点火)这个动词来命名属性名,表示触发job。
属性名属性类型说明
name
所有trigger通用
trigger名称
group
所有trigger通用
trigger所属的组名
description
所有trigger通用
trigger描述
calendarName
所有trigger通用
日历名称,指定使用哪个Calendar类,经常用来从trigger的调度计划中排除某些时间段
misfireInstruction
所有trigger通用
错过job(未在指定时间执行的job)的处理策略,默认为MISFIRE_INSTRUCTION_SMART_POLICY。详见这篇blog[5]
priority
所有trigger通用
优先级,默认为5。当多个trigger同时触发job时,线程池可能不够用,此时根据优先级来决定谁先触发
jobDataMap
所有trigger通用
同job的jobDataMap。假如job和trigger的jobDataMap有同名key,通过getMergedJobDataMap()获取的jobDataMap,将以trigger的为准
startTime
所有trigger通用
触发开始时间,默认为当前时间。决定什么时间开始触发job
endTime
所有trigger通用
触发结束时间。决定什么时间停止触发job
nextFireTime
SimpleTrigger私有
下一次触发job的时间
previousFireTime
SimpleTrigger私有
上一次触发job的时间
repeatCount
SimpleTrigger私有
需触发的总次数
timesTriggered
SimpleTrigger私有
已经触发过的次数
repeatInterval
SimpleTrigger私有
触发间隔时间
5、TriggerBuilder类
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group3")
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever())
.build();
上面代码是demo一个片段,可以看出TriggerBuilder类的作用:生成Trigger实例,默认生成SimpleTriggerImpl实例。同JobBuilder一样,这里也运用了建造者模式。
6、scheduler(调度器)
scheduler主要由StdScheduler类、Scheduler接口、StdSchedulerFactory类、SchedulerFactory接口、QuartzScheduler类实现,它们的关系见下面UML图。
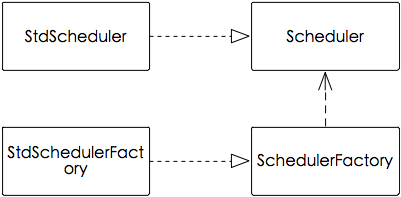
scheduler UML图
//创建调度器
SchedulerFactory schedulerFactory = newStdSchedulerFactory();
Scheduler scheduler=schedulerFactory.getScheduler();
......//将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);//调度器开始调度任务
scheduler.start();
上面代码是demo一个片段,可以看出这里运用了工厂模式,通过factory类(StdSchedulerFactory)生产出scheduler实例(StdScheduler)。scheduler是整个quartz的关键,为此,笔者把demo中用到的scheduler接口的源码加上中文注释做个讲解。
StdSchedulerFactory.getScheduler()源码
public Scheduler getScheduler() throwsSchedulerException {//读取quartz配置文件,未指定则顺序遍历各个path下的quartz.properties文件//解析出quartz配置内容和环境变量,存入PropertiesParser对象//PropertiesParser组合了Properties(继承Hashtable),定义了一系列对Properties的操作方法,比如getPropertyGroup()批量获取相同前缀的配置。配置内容和环境变量存放在Properties成员变量中
if (cfg == null) {
initialize();
}//获取调度器池,采用了单例模式//其实,调度器池的核心变量就是一个hashmap,每个元素key是scheduler名,value是scheduler实例//getInstance()用synchronized防止并发创建
SchedulerRepository schedRep =SchedulerRepository.getInstance();//从调度器池中取出当前配置所用的调度器
Scheduler sched =schedRep.lookup(getSchedulerName());
......//如果调度器池中没有当前配置的调度器,则实例化一个调度器,主要动作包括://1)初始化threadPool(线程池):开发者可以通过org.quartz.threadPool.class配置指定使用哪个线程池类,比如SimpleThreadPool。先class load线程池类,接着动态生成线程池实例bean,然后通过反射,
// 使用setXXX()方法将以org.quartz.threadPool开头的配置内容赋值给bean成员变量;//2)初始化jobStore(任务存储方式):开发者可以通过org.quartz.jobStore.class配置指定使用哪个任务存储类,比如RAMJobStore。先class load任务存储类,接着动态生成实例bean,然后通过反射,
// 使用setXXX()方法将以org.quartz.jobStore开头的配置内容赋值给bean成员变量;//3)初始化dataSource(数据源):开发者可以通过org.quartz.dataSource配置指定数据源详情,比如哪个数据库、账号、密码等。jobStore要指定为JDBCJobStore,dataSource才会有效;//4)初始化其他配置:包括SchedulerPlugins、JobListeners、TriggerListeners等;//5)初始化threadExecutor(线程执行器):默认为DefaultThreadExecutor;//6)创建工作线程:根据配置创建N个工作thread,执行start()启动thread,并将N个thread顺序add进threadPool实例的空闲线程列表availWorkers中;//7)创建调度器线程:创建QuartzSchedulerThread实例,并通过threadExecutor.execute(实例)启动调度器线程;//8)创建调度器:创建StdScheduler实例,将上面所有配置和引用组合进实例中,并将实例存入调度器池中
sched =instantiate();returnsched;
}
上面有个过程是初始化jobStore,表示使用哪种方式存储scheduler相关数据。quartz有两大jobStore:RAMJobStore和JDBCJobStore。RAMJobStore把数据存入内存,性能最高,配置也简单,但缺点是系统挂了难以恢复数据。JDBCJobStore保存数据到数据库,保证数据的可恢复性,但性能较差且配置复杂。
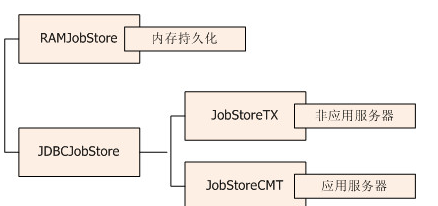
两种常见的任务存储方式
QuartzScheduler.scheduleJob(JobDetail, Trigger)源码
publicDate scheduleJob(JobDetail jobDetail,
Trigger trigger)throwsSchedulerException {//检查调度器是否开启,如果关闭则throw异常到上层
validateState();
......//获取trigger首次触发job的时间,以此时间为起点,每隔一段指定的时间触发job
Date ft =trig.computeFirstFireTime(cal);if (ft == null) {throw newSchedulerException("Based on configured schedule, the given trigger '" + trigger.getKey() + "' will never fire.");
}//把job和trigger注册进调度器的jobStore
resources.getJobStore().storeJobAndTrigger(jobDetail, trig);//通知job监听者
notifySchedulerListenersJobAdded(jobDetail);//通知调度器线程
notifySchedulerThread(trigger.getNextFireTime().getTime());//通知trigger监听者
notifySchedulerListenersSchduled(trigger);returnft;
}
QuartzScheduler.start()源码
public void start() throwsSchedulerException {
......//这句最关键,作用是使调度器线程跳出一个无限循环,开始轮询所有trigger触发job//原理详见“如何采用多线程进行任务调度”
schedThread.togglePause(false);
......
}















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









