





一:HashSet

- HashSet 继承于AbstractSet 该类提供了Set 接口的骨架实现,以最大限度地减少实现此接口所需的工作量。
- 实现Set接口,标志着内部元素是无序的,元素是不可以重复的。
- 实现Cloneable接口,标识着可以它可以被复制。
- 实现Serializable接口,标识着可被序列化。
HashSet内部是以HashMap的key来保存元素的

构造函数
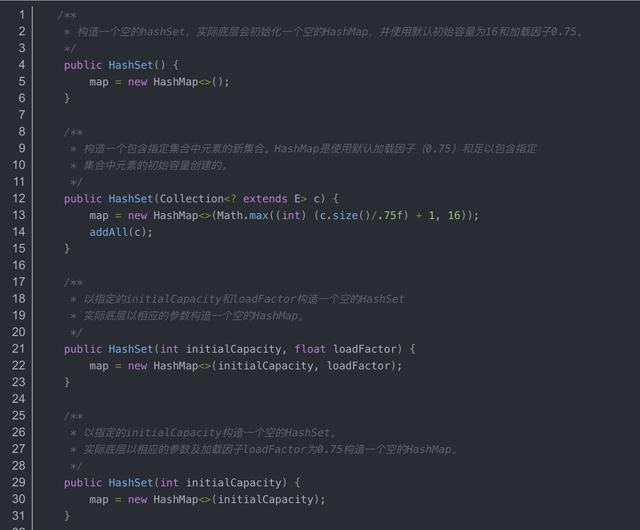

迭代器实现:返回key的集合的迭代器

/** * 返回此set中的元素的数量(set的容量)。 * 底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。 */ public int size() { return map.size(); } /** * 如果此set不包含任何元素,则返回true。 * 底层实际调用HashMap的isEmpty()判断该HashSet是否为空。 */ public boolean isEmpty() { return map.isEmpty(); } /** * 如果此set包含指定元素,则返回true。 * 底层实际调用HashMap的containsKey判断是否包含指定key。 */ public boolean contains(Object o) { return map.containsKey(o); } /** * 如果此set中尚未包含指定元素,则添加指定元素。 * 底层实际将将该元素作为key放入HashMap。 */ public boolean add(E e) { return map.put(e, PRESENT)==null; } /** * 如果指定元素存在于此set中,则将其移除。 * 底层实际调用HashMap的remove方法删除指定Entry。 */ public boolean remove(Object o) { return map.remove(o)==PRESENT; } /** * 从此set中移除所有元素。 * 底层实际调用HashMap的clear方法清空Entry中所有元素。 */ public void clear() { map.clear(); } /** * 返回此HashSet实例的浅表副本:并没有复制这些元素本身。 * 底层实际调用HashMap的clone()方法,获取HashMap的浅表副本,并设置到HashSet中。 */ @SuppressWarnings("unchecked") public Object clone() { try { HashSet newSet = (HashSet) super.clone(); newSet.map = (HashMap) map.clone(); return newSet; } catch (CloneNotSupportedException e) { throw new InternalError(e); } } /** * 自定义序列化实现 */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // Write out HashMap capacity and load factor s.writeInt(map.capacity()); s.writeFloat(map.loadFactor()); // Write out size s.writeInt(map.size()); // Write out all elements in the proper order. for (E e : map.keySet()) s.writeObject(e); } private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject(); // Read capacity and verify non-negative. int capacity = s.readInt(); if (capacity < 0) { throw new InvalidObjectException("Illegal capacity: " + capacity); } // Read load factor and verify positive and non NaN. float loadFactor = s.readFloat(); if (loadFactor <= 0 || Float.isNaN(loadFactor)) { throw new InvalidObjectException("Illegal load factor: " + loadFactor); } // Read size and verify non-negative. int size = s.readInt(); if (size < 0) { throw new InvalidObjectException("Illegal size: " + size); } capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f), HashMap.MAXIMUM_CAPACITY); SharedSecrets.getJavaOISAccess() .checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity)); // Create backing HashMap map = (((HashSet>)this) instanceof LinkedHashSet ? new LinkedHashMap(capacity, loadFactor) : new HashMap(capacity, loadFactor)); // Read in all elements in the proper order. for (int i=0; i spliterator() { return new HashMap.KeySpliterator(map, 0, -1, 0, 0); }- HashSet就是限制了功能的HashMap,所以了解HashMap的实现原理,这个HashSet自然就通
- 对于HashSet中保存的对象,主要要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性
- 虽说时Set是对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了(这个Set的put方法的返回值真有意思)
- HashSet没有提供get()方法,愿意是同HashMap一样,Set内部是无序的,只能通过迭代的方式获得
二:LinkedHashSet
LinkedHashSet是HashSet的一个“扩展版本”,HashSet并不管什么顺序,不同的是LinkedHashSet会维护“插入顺序”。HashSet内部使用HashMap对象来存储它的元素,而LinkedHashSet内部使用LinkedHashMap对象来存储和处理它的元素。
源码如下
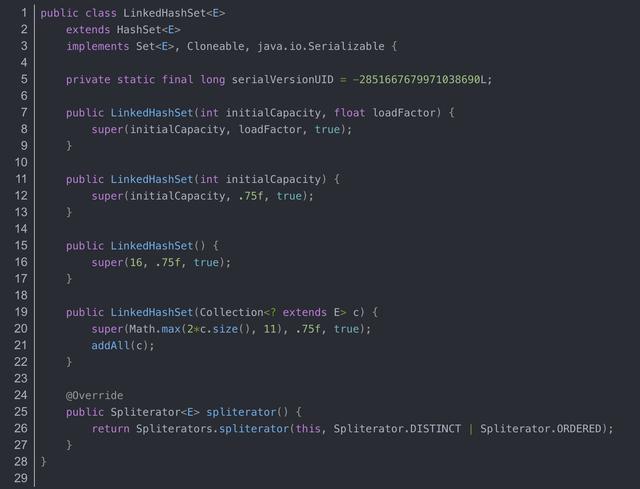
从源码中我们可以注意到,LinkedHashSet继承于HashSet,只包含4个构造函数,这4个构造函数调用的是同一个父类的构造函数。我们来看一下父类中的这个构造函数:

这个构造函数需要初始容量,负载因子和一个boolean类型的哑值(没有什么用处的参数,作为标记,译者注)等参数。这个哑参数只是用来区别这个构造函数与HashSet的其他拥有初始容量和负载因子参数的构造函数。
这个构造函数内部初始化了一个LinkedHashMap对象,这个对象恰好被LinkedHashSet用来存储它的元素。
LinkedHashSet并没有自己的方法,所有的方法都继承自它的父类HashSet,因此,对LinkedHashSet的所有操作方式就好像对HashSet操作一样。
唯一的不同是内部使用不同的对象去存储元素。在HashSet中,插入的元素是被当做HashMap的键来保存的,而在LinkedHashSet中被看作是LinkedHashMap的键。
三:TreeSet
我们知道TreeMap是一个有序的二叉树,那么同理TreeSet同样也是一个有序的,它的作用是提供有序的Set集合。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
通过源码我们知道TreeSet基础AbstractSet,实现NavigableSet、Cloneable、Serializable接口。
其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。
NavigableSet是扩展的 SortedSet,具有了为给定搜索目标报告最接近匹配项的导航方法,这就意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。Cloneable支持克隆,Serializable支持序列化。
public class TreeSet extends AbstractSet implements NavigableSet, Cloneable, java.io.Serializable{ //使用NavigableMap来保存TreeSet元素 private transient NavigableMap m; // 与NavigableMap中的对象关联的虚拟值 private static final Object PRESENT = new Object(); /** * 构造由指定的NavigableMap的集合。 */ TreeSet(NavigableMap m) { this.m = m; } /** * 构造一个新的空TreeSet,根据元素的自然排序进行排序。 插入到集合中的所有元素都必须实现Comparable接口。 * 此外,所有这些元素必须可以相互比较 如果用户尝试向违反此约束的集合添加元素,那么add调用将抛出一个 * ClassClassException。 */ public TreeSet() { this(new TreeMap()); } /** * 构造一个新的空TreeSet,根据指定的比较器进行排序。 插入到集合中的所有元素必须与指定的比较器可相互比较 * 如果用户尝试向违反此约束的集合添加元素,那么add调用将抛出ClassCastException。 */ public TreeSet(Comparator super E> comparator) { this(new TreeMap<>(comparator)); } /** *构造一个新的TreeSet,其中包含指定集合中的元素,并根据元素的 自然排序 进行排序。 *插入到集合中的所有元素都必须实现 Comparable接口。 此外,所有这些元素必须可以相互比较 */ public TreeSet(Collection extends E> c) { this(); addAll(c); } /** * 构造一个包含相同元素并使用与指定的排序集相同顺序的TreeSet。 */ public TreeSet(SortedSet s) { this(s.comparator()); addAll(s); } /** * 以升序返回此集合中元素的迭代器。 */ public Iterator iterator() { return m.navigableKeySet().iterator(); } /** * 以降序返回此集合中元素的迭代器。 */ public Iterator descendingIterator() { return m.descendingKeySet().iterator(); } /** * @since 1.6 */ public NavigableSet descendingSet() { return new TreeSet<>(m.descendingMap()); } /** * 返回此集合中元素的数量(基数)。返回此集合中元素的数量。 */ public int size() { return m.size(); } /** * 返回TreeSet是否为空 */ public boolean isEmpty() { return m.isEmpty(); } /** * 返回TreeSet是否包含对象(o) */ public boolean contains(Object o) { return m.containsKey(o); } /** * 添加e到TreeSet中 */ public boolean add(E e) { return m.put(e, PRESENT)==null; } /** * 删除TreeSet中的对象o */ public boolean remove(Object o) { return m.remove(o)==PRESENT; } /** * 清空TreeSet */ public void clear() { m.clear(); } /** * 将集合c中的全部元素添加到TreeSet中 */ public boolean addAll(Collection extends E> c) { // Use linear-time version if applicable if (m.size()==0 && c.size() > 0 && c instanceof SortedSet && m instanceof TreeMap) { SortedSet extends E> set = (SortedSet extends E>) c; TreeMap map = (TreeMap) m; Comparator> cc = set.comparator(); Comparator super E> mc = map.comparator(); if (cc==mc || (cc != null && cc.equals(mc))) { map.addAllForTreeSet(set, PRESENT); return true; } } return super.addAll(c); } /** * 返回子Set,实际上是通过TreeMap的subMap()实现的。 */ public NavigableSet subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) { return new TreeSet<>(m.subMap(fromElement, fromInclusive, toElement, toInclusive)); } /** * 返回Set的头部,范围是:从头部到toElement。 * inclusive是是否包含toElement的标志 */ public NavigableSet headSet(E toElement, boolean inclusive) { return new TreeSet<>(m.headMap(toElement, inclusive)); } /** * 返回Set的尾部,范围是:从fromElement到结尾。 * inclusive是是否包含fromElement的标志 */ public NavigableSet tailSet(E fromElement, boolean inclusive) { return new TreeSet<>(m.tailMap(fromElement, inclusive)); } /** * 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。 */ public SortedSet subSet(E fromElement, E toElement) { return subSet(fromElement, true, toElement, false); } /** * 返回Set的头部,范围是:从头部到toElement(不包括)。 */ public SortedSet headSet(E toElement) { return headSet(toElement, false); } /** * 返回Set的尾部,范围是:从fromElement到结尾(不包括)。 */ public SortedSet tailSet(E fromElement) { return tailSet(fromElement, true); } //返回Set的比较器 public Comparator super E> comparator() { return m.comparator(); } /** * 返回Set的第一个元素 */ public E first() { return m.firstKey(); } /** * 返回Set的最后一个元素 */ public E last() { return m.lastKey(); } // NavigableSet API methods /** * 返回Set中小于e的最大元素 */ public E lower(E e) { return m.lowerKey(e); } /** *返回Set中小于/等于e的最大元素 */ public E floor(E e) { return m.floorKey(e); } /** *返回Set中大于/等于e的最小元素 */ public E ceiling(E e) { return m.ceilingKey(e); } /** * 返回Set中大于e的最小元素 */ public E higher(E e) { return m.higherKey(e); } /** * 获取第一个元素,并将该元素从TreeMap中删除。 */ public E pollFirst() { Map.Entry e = m.pollFirstEntry(); return (e == null) ? null : e.getKey(); } /** * 获取最后一个元素,并将该元素从TreeMap中删除。 */ public E pollLast() { Map.Entry e = m.pollLastEntry(); return (e == null) ? null : e.getKey(); } /** *克隆一个TreeSet,并返回Object对象 */ @SuppressWarnings("unchecked") public Object clone() { TreeSet clone; try { clone = (TreeSet) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(e); } clone.m = new TreeMap<>(m); return clone; } /** * java.io.Serializable的写入函数 *将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中 */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden stuff s.defaultWriteObject(); // Write out Comparator s.writeObject(m.comparator()); // Write out size s.writeInt(m.size()); // Write out all elements in the proper order. for (E e : m.keySet()) s.writeObject(e); } /** * java.io.Serializable的读取函数:根据写入方式读出 * 先将TreeSet的“比较器、容量、所有的元素值”依次读出 */ private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden stuff s.defaultReadObject(); // Read in Comparator @SuppressWarnings("unchecked") Comparator super E> c = (Comparator super E>) s.readObject(); // Create backing TreeMap TreeMap tm = new TreeMap<>(c); m = tm; // Read in size int size = s.readInt(); tm.readTreeSet(size, s, PRESENT); } public Spliterator spliterator() { return TreeMap.keySpliteratorFor(m); } private static final long serialVersionUID = -2479143000061671589L;}TreeSet实际上是TreeMap实现的。当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









