





- 本节将针对波士顿房价数据集的房间数量(RM)采用简单一元线性回归,目标是预测在最后一列(MEDV)给出的房价。波士顿房价数据集可从http://lib.stat.cmu.edu/datasets/boston处获取。
- 在实现一元线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归。在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要。这里是波士顿房价数据集的多重线性回归的代码,使用 13 个输入特征。
注意事项:代码实现注意:
- 占位符X可特地申明shape=[m, n],也可以不申明。一般都是不申明的,例如Y就没有申明,后面的feed_dict依旧可以赋值,不会报错
- 对于多元线性回归,即多项式,不用单独设置b,只设置w即可。w0=b,包含在w张量中,相对应的,需要向数据集X_train张量中额外在列初或列尾多加一列1(例如本例多加全为1的一列于第一列位置),因此可保证y=w0+w1*x1+w2*x2+....
X = tf.placeholder(tf.float32, name='X', shape=[m, n])
Y = tf.placeholder(tf.float32, name='Y')
w = tf.Variable(tf.random_normal([n, 1]))
X_train = np.reshape(np.c_[np.ones(m), X_train], [m, n + 1])一元线性回归
本小节直接从TensorFlowcontrib 数据集加载数据。使用随机梯度下降优化器优化单个训练样本的系数。
# 针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 1.在神经网络中,所有的输入都线性增加。为了使训练有效,输入应该被归一化,所以这里定义一个函数来归一化输入数据:
def normalize(X):
# 实际这里是标准化,不是maxminscale
mean = np.mean(X)
std = np.std(X)
X = (X - mean) / std
return X - mean
# 2.现在使用 TensorFlow contrib 数据集加载波士顿房价数据集,并将其分解为 X_train 和 Y_train。可以对数据进行归一化处理:
boston = tf.contrib.learn.datasets.load_dataset('boston')
# boston includes boston.data and boston.target
# np.shape(boston.data)=(506, 13) np.shape(boston.target)=(506,)
X_train, Y_train = boston.data[:, 5], boston.target
# X_train=normalize(X_train) #this step is optional here
n_samples = len(X_train)
# 3.为训练数据声明 TensorFlow 占位符:
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
# 4.创建 TensorFlow 的权重和偏置变量且初始值为零
b = tf.Variable(0.0)
w = tf.Variable(0.0)
# 5.定义用于预测的线性回归模型
Y_hat = X * w + b
# 6.定义损失函数:
loss = tf.square(Y_hat - Y, name='loss')
# 7.选择梯度下降优化器:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss)
# 8.声明初始化操作符
init_op = tf.global_variables_initializer()
#init_op = tf.initialize_all_variables()
total = []
# 9.现在,开始计算图,训练 100 次:
with tf.Session() as sess:
sess.run(init_op)
writer = tf.summary.FileWriter('Z:python_codeCBIANCHENG_relevant_codeGraphs', sess.graph)
for i in range(100):
total_loss = 0
for x, y in zip(X_train, Y_train):
_, l = sess.run([optimizer, loss], feed_dict={X: x, Y: y})
total_loss += l
total.append(total_loss / n_samples)
print('epoch{0}:loss{1}'.format(i, total_loss / n_samples))
writer.close()
b_value, w_value = sess.run([b, w])
# 10.查看解果
Y_pred = X_train * w_value + b_value
print('done')
plt.plot(X_train, Y_train, 'bo', label='real data')
plt.plot(X_train, Y_pred, 'r', label='predicted data')
plt.legend()
plt.show()
plt.plot(total)
plt.show()解读分析
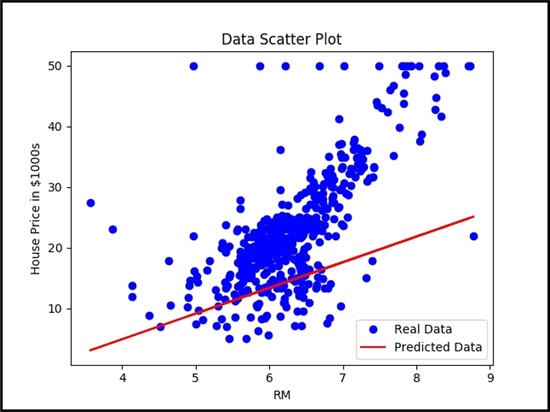
从下图中可以看到,简单线性回归器试图拟合给定数据集的线性线:
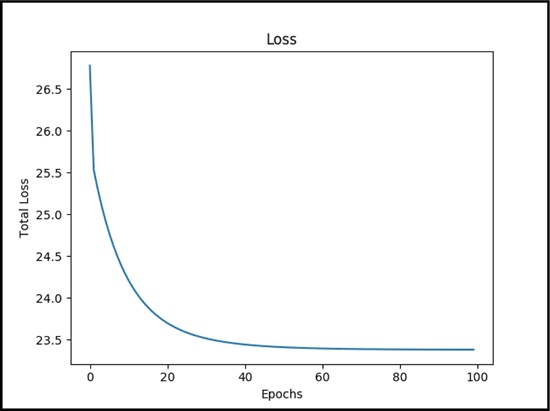
在下图中可以看到,随着模型不断学习数据,损失函数不断下降:
下图是简单线性回归器的 TensorBoard 图:
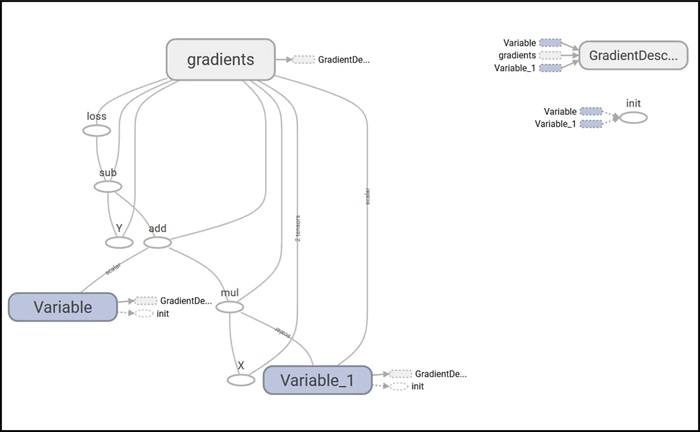
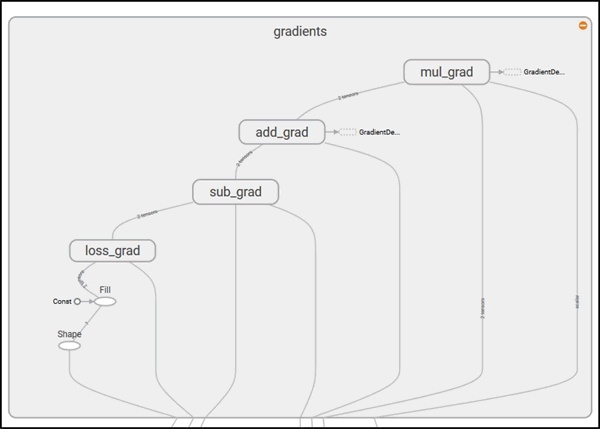
该图有两个名称范围节点 Variable 和 Variable_1,它们分别是表示偏置和权重的高级节点。以梯度命名的节点也是一个高级节点,展开节点,可以看到它需要 7 个输入并使用 GradientDescentOptimizer 计算梯度,对权重和偏置进行更新:
多元线性回归
代码实现注意:
- 占位符X可特地申明shape=[m, n],也可以不申明。一般都是不申明的,例如Y就没有申明,后面的feed_dict依旧可以赋值,不会报错
X = tf.placeholder(tf.float32, name='X', shape=[m, n])
Y = tf.placeholder(tf.float32, name='Y')- 对于多元线性回归,即多项式,不用单独设置b,只设置w即可。w0=b,包含在w张量中,相对应的,需要向数据集X_train张量中额外在列初或列尾多加一列1(例如本例多加全为1的一列于第一列位置),因此可保证y=w0+w1*x1+w2*x2+....
w = tf.Variable(tf.random_normal([n, 1]))
X_train = np.reshape(np.c_[np.ones(m), X_train], [m, n + 1])完整代码
# 在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归。
# 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要。这里是波士顿房价数据集的多重线性回归的代码,使用 13 个输入特征
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 因为各特征的数据范围不同,需要归一化特征数据
def normalize(X):
mean = np.mean(X)
std = np.std(X)
X = (X - mean) / std
return X
# 添加一个额外的固定输入值将权重和偏置结合起来。为此定义函数 append_bias_reshape()。
def append_bias_reshape(features, labels):
m = features.shape[0] # features 的行数
n = features.shape[1] # features 的列数
# 其实都不用reshape,np.c_函数返回了[m, n+1]的数组,再使用reshape只是为了确保
x = np.reshape(np.c_[np.ones(m), features], [m, n + 1])
y = np.reshape(labels, [m, 1])
return x, y
# 使用 TensorFlow contrib 数据集加载波士顿房价数据集,并将其划分为 X_train 和 Y_train。
# 注意到 X_train 包含所需要的特征。可以选择在这里对数据进行归一化处理,也可以添加偏置并对网络数据重构:
boston = tf.contrib.learn.datasets.load_dataset('boston')
X_train, Y_train = boston.data, boston.target
X_train = normalize(X_train)
X_train, Y_train = append_bias_reshape(X_train, Y_train)
m = len(X_train) # 即X_train的行数
# 注意append_bias_reshape函数中n=13, 这里n=14,因而后面占位符X和变量w都是合理的
n = 13 + 1
# 为训练数据声明 TensorFlow 占位符。观测占位符 X 的形状变化
# X其实也不用特地申明shape=[m, n]。例如Y就没有申明,后面的feed_dict依旧可以赋值,不会报错
X = tf.placeholder(tf.float32, name='X', shape=[m, n])
Y = tf.placeholder(tf.float32, name='Y')
# 为权重和偏置创建 TensorFlow 变量。通过随机数初始化权重:
# 多元线性回归,即多项式,不用单独设置b。w0=b,包含在w中,而X_train中第一列全为1,因此可保证y=w0+w1*x1+w2*x2+....
w = tf.Variable(tf.random_normal([n, 1]))
Y_hat = tf.matmul(X, w)
loss = tf.reduce_mean(tf.square(Y - Y_hat), name='loss')
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss)
init_op = tf.global_variables_initializer()
total = []
# 执行环节
with tf.Session() as sess:
sess.run(init_op)
writer = tf.summary.FileWriter('graphs', sess.graph)
for i in range(100):
_, l = sess.run([optimizer, loss], feed_dict={X: X_train, Y: Y_train})
total.append(l)
print('Epoch{0}:Loss{1}'.format(i, l))
writer.close()
w_value = sess.run([w])
plt.figure()
plt.plot(total)
plt.show()
# 使用模型预测房价
N = 500
X_new = X_train[N, :]
Y_pred = (np.matmul(X_new, w_value)).round(1)
print('predicted value: ${0} actual value: ${1}'.format(Y_pred[0] * 1000, Y_train[N] * 1000), 'done')我们发现损失随着训练过程的进行而减少:
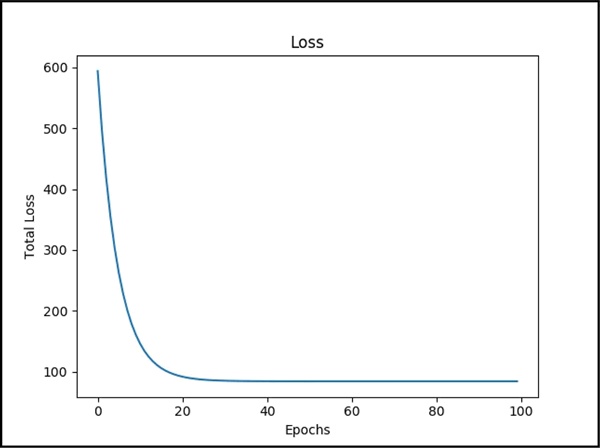
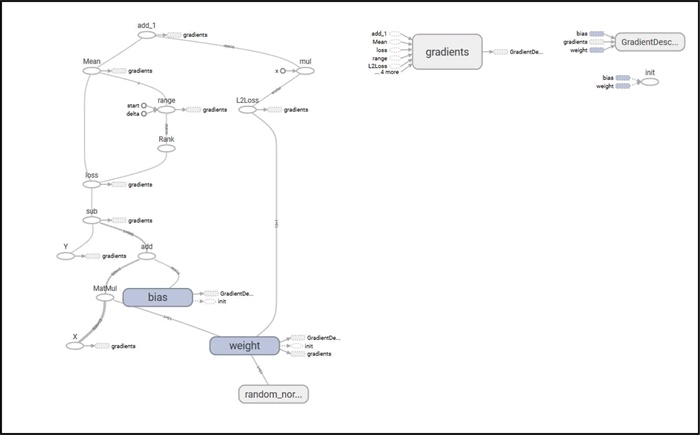
本节使用了 13 个特征来训练模型。简单线性回归和多元线性回归的主要不同在于权重,且系数的数量始终等于输入特征的数量。下图为所构建的多元线性回归模型的 TensorBoard 图:















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









