







近两年音频生成是一个非常火热的研究课题,其目的主要在于如何将低维度、低帧率的输入特征转换成高采样率的语音信号。针对该任务,现有的技术,比如自回归网络和GAN,都处于瓶颈阶段,无法同时满足高音质和高实时率的要求。扩散概率模型的提出,为该问题提出了新的解决方向。
简述
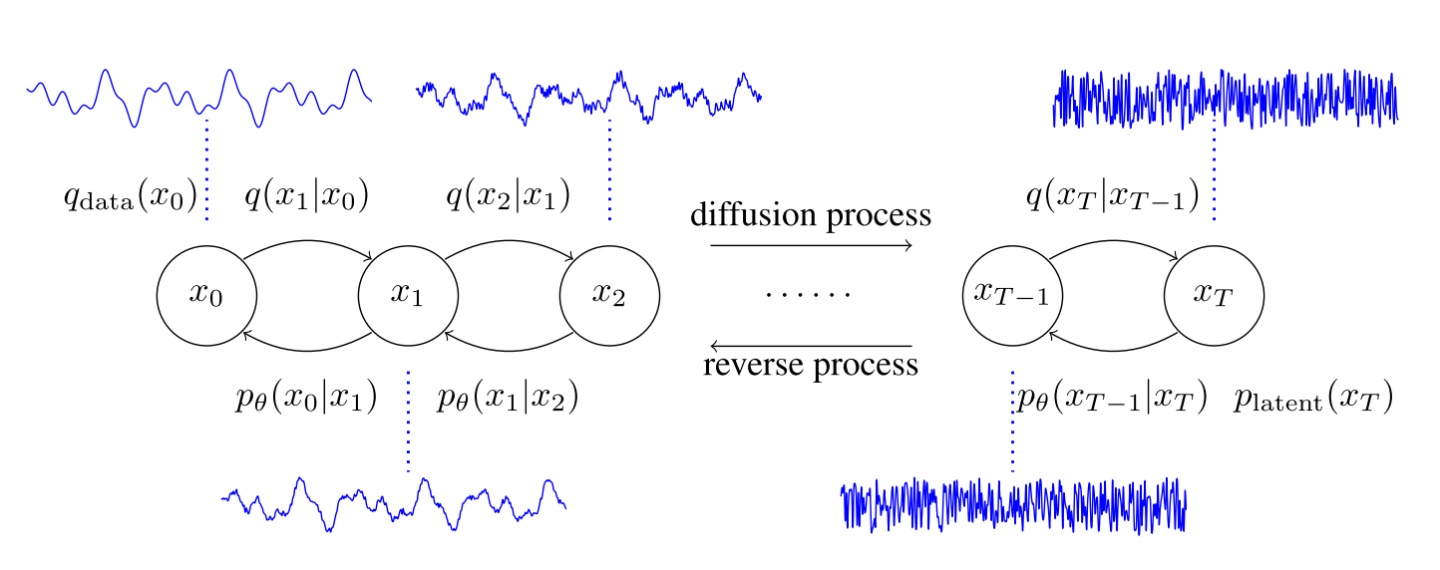
在条件音频生成任务中,比如神经声码器 (neural vocoder),端到端TTS,其大体框架都是将同样长度的高斯噪声通过一个生成模型映射到目标波形信号。扩散概率模型也是如此,但具体操作方法,包括训练和解码,都与其他方案不同。
扩散概率模型是一种基于马尔可夫链的概率模型,它将噪声和目标波形的映射关系分成了
扩散概率模型
首先定义
扩散过程的目的是通过一条马尔可夫链将
其中
反向过程则是希望进行基于正态分布的采样进行生成:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









