






jieba库,它是Python中一个重要的第三方中文分词函数库。
1.jieba的下载
由于jieba是一个第三方函数库,所以需要另外下载。电脑搜索“cmd”打开“命令提示符”,然后输入“pip install jieba”,稍微等等就下载成功。
(注:可能有些pip版本低,不能下载jieba库,需要手动升级pip至19.0.3的版本,在安装jieba库)
当你再次输入“pip install jieba”,显示如图,jieba库就下载成功。
2.jieba库的3种分词模式
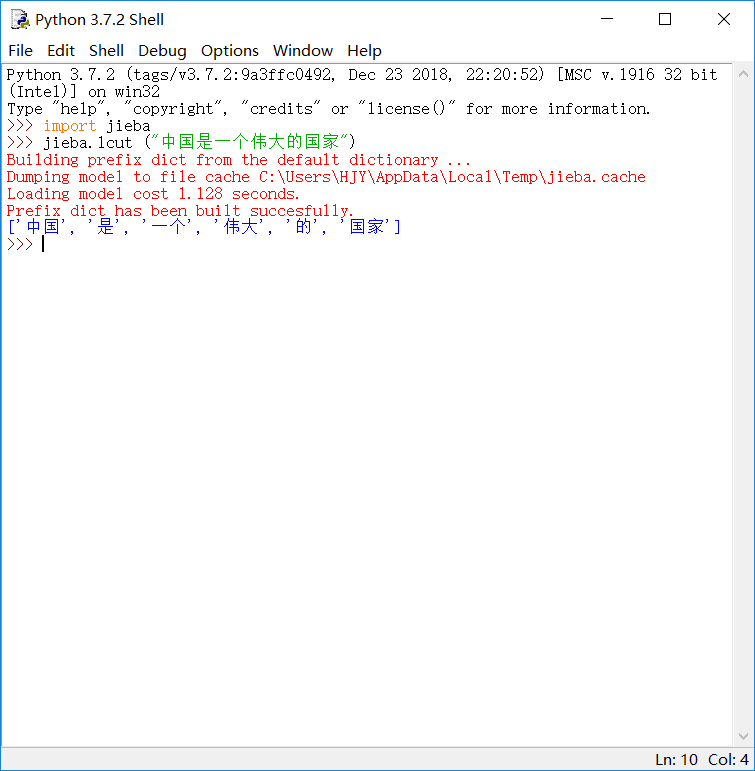
精确模式:将句子最精确地切开,适合文本分析。
例:
全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
例:(“国是”,黑人问号)

搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
例:(没什么不同,可能我还没发现它的用处)

3.jieba应用
我选取了哈姆雷特(https://en.wikipedia.org/wiki/Hamlet#Act_I)的一小片段,txt形式存放在我的一个文件夹里,对它进行分词,输入代码:
def get_text():
txt = open("D://加油鸭~//hamlet.txt", "r",encoding='UTF-8').read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格
return txt
hamletTxt = get_text() # 打开并读取文件
words = hamletTxt.split() # 对字符串进行分割,获得单词列表
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1 # 分词计算
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word,count))
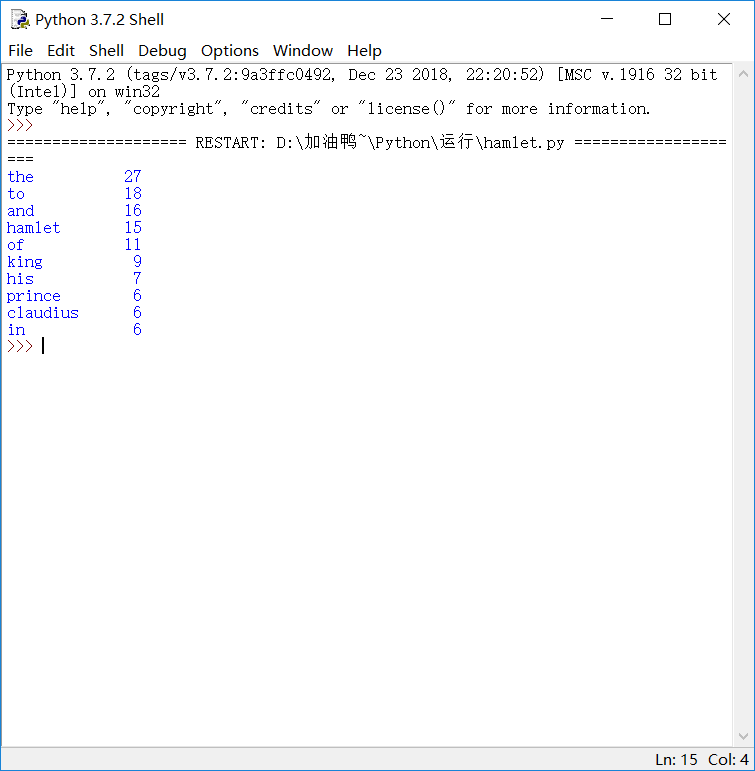
得到结果,如图:
最后,我们还可以做词云图,这个呢我下次再给大家分享吧,再见~
python之jieba库
jieba “结巴”中文分词:做最好的 Python 中文分词组件 "Jieba" (Chinese for "to stutter") Chinese tex ...
python 学习jieba库遇到的问题及解决方法
昨天在课堂上学习了jieba库,跟着老师写了同样的代码时却遇到了问题: jieba分词报错AttributeError: module 'jieba' has no attribute 'cut' 文 ...
python 利用jieba库词频统计
1 #统计里人物的出现次数 2 3 import jieba 4 text = open('threekingdoms.txt','r',encoding='utf-8').re ...
python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
本实例主要用到python的jieba库 首先当然是安装pip install jieba 这里比较关键的是如下几个步骤: 加载文本,分析文本 txt=open("C:\\Users\\Be ...
python第三方库------jieba库(中文分词)
jieba“结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 特点支持三种分词模式: 精确模式,试图将句子最精确地切开, ...
python jieba库的基本使用
第一步:先安装jieba库 输入命令:pip install jieba jieba库常用函数: jieba库分词的三种模式: 1.精准模式:把文本精准地分开,不存在冗余 2.全模式:把文中所有可能的 ...
python 读写txt文件并用jieba库进行中文分词
python用来批量处理一些数据的第一步吧. 对于我这样的的萌新.这是第一步. #encoding=utf-8 file='test.txt' fn=open(file,"r") ...
python入门之jieba库的使用
对于一段英文,如果希望提取其中的的单词,只需要使用字符串处理的split()方法即可,例如“China is a great country”. 然而对于中文文本,中文单词之间缺少分隔符,这是中文 ...
Python基础库之jieba库的使用(第三方中文词汇函数库)
各位学python的朋友,是否也曾遇到过这样的问题,举个例子如下: “I am proud of my motherland” 如果我们需要提取中间的单词要走如何做? 自然是调用string中的spl ...
随机推荐
在HTML页面获取当前系统时间
假设用一个名为text的字符串向量存放文本文件的数据,其中的元素或者是一句话或者是一个用于表示段分隔的空字符串。将text中第一段全改为大写形式
#include #include #include using namespace std; int main ...
python参考手册--第4、5、6、7章
1.zip zip(s,t):将序列组合为一个元组序列[(s[0],t[0]), (s[1],t[1]), (s[2],t[2]), (s[3],t[3]),...] >>> s = ...
Web应用与应用层协议
Web应用与应用层协议 本篇博文中的主要参考文献是<计算机网络高级教程>,分别是吴功宜老先生和吴英教授合著.这部教程是我研究生老师所推荐的网络必读科目,由于该教程讲解的基础知识详细,但内容 ...
AI-2048 注释
针对2048游戏,有人实现了一个AI程序,可以以较大概率(高于90%)赢得游戏,并且作者在 stackoverflow上简要介绍了AI的算法框架和实现思路. 有博客介绍了其中涉及的算法,讲的很好 其中 ...
springboot+VUE(二)
入element-ui cnpm install element-ui -S 执行后,会下载element-ui的包到本地,同时会将配置加入到package.json的依赖块中. 通过命令行可以将最新 ...
vue+canvas踩坑之旅
let img=new Image(); if(img.complete) { console.log('dd'); } img.src="http://localhost:8888/sta ...
Orangegreenworks封装rpgmakermv
You’ll get a zip file with a folder called “lib” and a file called greenworks.js. Put both of them o ...
JS(JQEERY) 获取JSON对象中的KEY VALUE
var json= { "Type": "Coding", "Height":100 }; for (var key in json) { ...
封装网络请求并在wxml调用
https://blog.csdn.net/qq_35713752/article/details/78109084 // url:网络请求的url method:网络请求方式 data:请求参数 m ...














 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









