





multiprocessing作为Python中多进程的模块,对于充分利用cpu来处理计算敏感型任务可以很大的提高效率。
题外话:对于I/O敏感型的任务multithreading更加适合,具体可以参考相关文章。
multiprocessing对于新人来说还算友好,但是随着使用的深入,就会发现还是有很多独特的机制需要去理解。对于一些机制之前的文章也有所介绍,可以参考:
- python 多进程map方法应用
- Python 多进程之进程调用和执行顺序
我们这里首先列出multiprocessing中常用的函数和使用范式,然后再去解析后面的原理。
常用的函数
Process: 最基本的创建进程的函数,可以手动的创建一下进程。这里要注意的是函数的调用方式,比如args这个参数中,即使一个参数也要写成(x,)的形式,逗号不能省:
x,y,z,k = 1,2,0,0
def add(a,b,c):
c = a+b
k = [c]
return c
if __name__ == '__main__':
reader_p = Process(target=reader, args=(x,y,z))2. Pool:这个函数可以更简单方便的批量创建多进程任务,这个方法中常用的函数有apply_async, map, starmap,map_async等。_async 是同步异步的区别,而starmap是用在多参数的函数中的。这里给出一个最基本的例子,具体的用法各位可以很容易google查到。
x,y,z,k = 1,2,0,0
def add(a,b,c):
c = a+b
k = [c]
return c
add(x+i, y, z)
if __name__ == '__main__':
tries = 3
p = Pool(tries)
result = p.starmap(add, zip([x + i for i in range(tries)], [y] * tries, [z] * tries))深入理解multiprocessing
这部分大家可以参考一篇系列博客:
- Python multiprocessing库使用手记(引子)
- Python multiprocessing 使用手记[1] – 进程模型
- Python multiprocessing 使用手记[2] – 跨进程对象共享
- Python multiprocessing 使用手记[3] – 关于Queue
参数共享问题
虽然multiprocessing很好用,但是由于进程锁GIL的存在,使得在一些复杂任务中,对于参数的传递就不是很方便了。至于其中的原因,我们来慢慢解释。
首先,对于一个multiprocessing的程序来说,是有一个主进程(我们用M表示)来启动其他子进程(用S_i来表示)的。
那么同一套代码,相同的变量,是如何从主进程M分配到子进行S_i中的呢? 这就要提到程序入口和python的包导入机制。
正如上面程序中常见的语句if __name__ =='__main__': ,这段代码的含义是当该程序做为主程序M启动时,执行下面的代码。对于multiprocessing的程序来说,这段代码是必不可少的,因为它提供了主进程入口,并通过主程序来启动子程序。如果没有这段代码,python无法明确判断那个是主进程,这样就无法分配子进程。
了解了主进程的入口,那么我们就该聊一聊进程间变量的关系以及代码执行顺序的问题, 如下图:
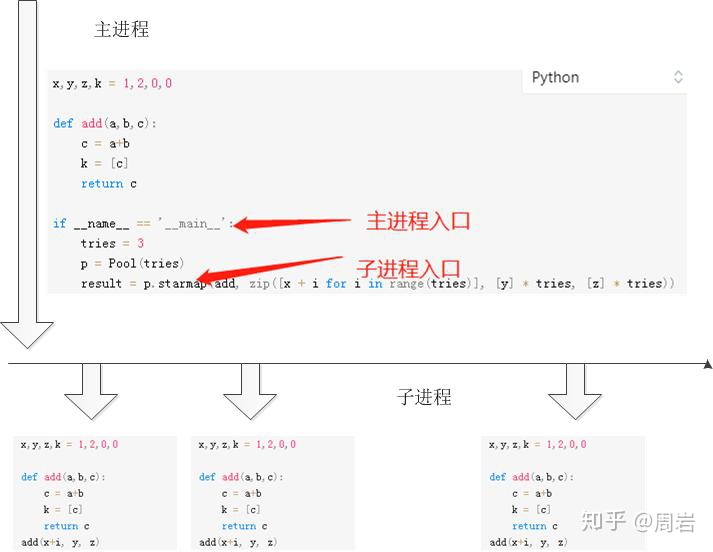
从图中可以看到子进程和主进程之间的区别,其中主进程和子进程分别初始化了if __name__ =='__main__':之前变量。
但是注意,这些变量和函数在没有改变的情况下,是具有相同的id的,当各自的进程中修改这些变量后,会在各自的进程中生成一个自己的id。这个机制是由python特性决定的,有点类似copy函数。 具体的实验可以参考我之前的这篇知乎:Python 多进程之进程调用和执行顺序。
言归正传,有了前面这层机制的铺垫,我们就来聊聊mutiprocessing中参数共享的问题。
通常来说,进程间参数共享要通过一个可以跨进程通信的变量,这里比较常用的应该属于Queue。 这个用法类似队列的先入先出,典型的应用就是生产者和消费者模型。
但是,Queue也不是所有的变量都可以共享。关键因素在于理解multiprocessing对于进程间变量的传递机制。
multiprocessing的变量在进程间传递,无论是通过map、apply等函数,还是通过Queue来共享,都是默认需要将对象序列化后进行传递(python一切皆对象)。这就有一个关键的问题,python的序列化方法多数基于pickle,而multiprocessing也不例外。
pickle并不是所以对象都可以序列化,它的限制为:

对于复杂对象,如weakref这样的对象是不支持序列化的。
那么如何对包含复杂对象参数的问题进行并行化呢?我们就要用到上面的机制。
首先,我们要将包含复杂对象的参数进行尽可能的分离,分成可序列化的部分和不可序列化的部分。其中不可序列化的部分最好是在子进程运行过程中不会被改变的,这样就不会有额外的内存开销。
然后,将这部分不可序列的部分定义在程序的开头,这样就可以作为参数读入到各个子进程中。
其次,将可序列化的部分作为参数传递给map函数,然后在子进程中将这两部分参数结合,作为一个完整的参数运行程序。
接下来我们给出一个例子:
from multiprocessing import Manager, Pool
from brian2 import *
start_scope()
prefs.codegen.target = "numpy"
defaultclock.dt = 1 * ms
equ = '''
dv/dt = (I-v) / (20*ms) : 1 (unless refractory)
dg/dt = (-g)/(10*ms) : 1
dh/dt = (-h)/(9.5*ms) : 1
I = (g-h)*20 : 1
'''
on_pre ='''
h+=strength
g+=strength
'''
P = PoissonGroup(10, np.arange(10)*Hz + 50*Hz)
G = NeuronGroup(10, equ, threshold='v > 0.9', reset='v = 0', method='linear',refractory=1*ms )
S = Synapses(P, G, 'strength : 1',on_pre = on_pre, method='linear', delay = 1*ms, name='pathway_1')
S.connect(j='i')
S.strength = 1
net = Network(collect())
net.store('init')
def run_net(x, q):
state = q.get()
net._stored_state['temp'] = state[0]
net.restore('temp')
net.run(10 * ms)
print(state[1])
q.put([net._full_state(), state[1]])
return x
if __name__ == '__main__':
core = 4
pool = Pool(core)
q = Manager().Queue(core)
for i in range(core):
q.put([net._full_state(), i])
result = pool.starmap(run_net, [(x, q) for x in range(20)])
这个例子中,Brian2生成的net包含weakref对象,无法直接被作为参数传递。但是net的状态state是一组np.array对象,可以被pickle。因此这里在函数前面先生成net,再通过net自带的store和restore函数传入state来解决问题。
可以注意到,这里的state是通过queue来传递的,另外,multiprocessing中Queue和Manager().Queue不是一样的机制。Manager().Queue是通过代理模式进行对象的共享,而Queue是通过继承的方式,这种方式在windows里面无法使用。
以上这些问题都是在windows进行的测试,由于windows和linux底层对于multiprocessing的实现不同,所以表现也不相同。具体说来,Linux是通过fork方式来将主进程的变量直接copy一份过来用,而windows不能用fork方法,因此是直接在子进程重新运行一遍程序,相当于import。具体可以参考:python多进程,multiprocessing和fork_qm5132的博客-CSDN博客















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









