






泰坦尼克号是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉 。然而不幸的是,在它的处女航中,泰坦尼克号便遭厄运。
这次打算练练手,用刚学的机器学习预测kaggle上的预测泰坦尼克号生存率项目。
先用xmind对流程进行了整理,让每个步骤更清晰。
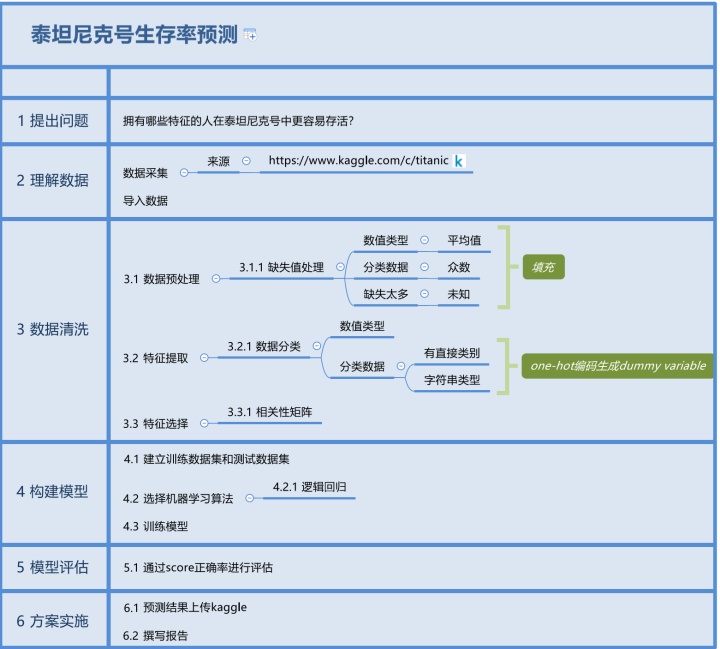
1.提出问题
拥有哪些特征的人在泰坦尼克号中更容易存活?
2.理解数据
- 数据采集
数据来源:
Titanic: Machine Learning from Disaster
- 准备步骤
导入数据
# 忽略警告提示
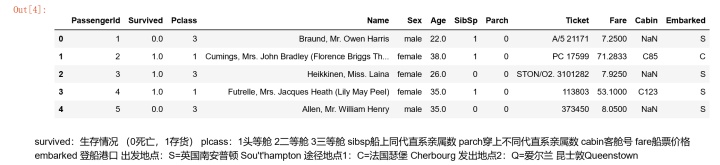
#查看数据类型列的描述统计信息
3.数据清洗
- 数据预处理
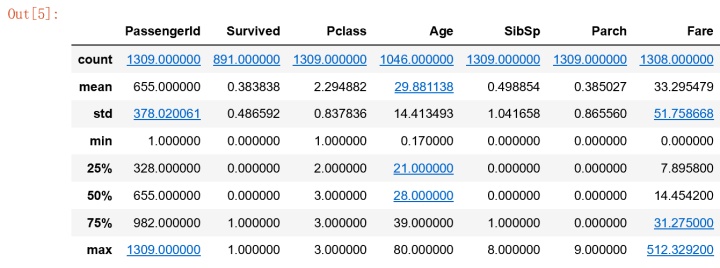
#查看每一列的数据类型,和数据总数

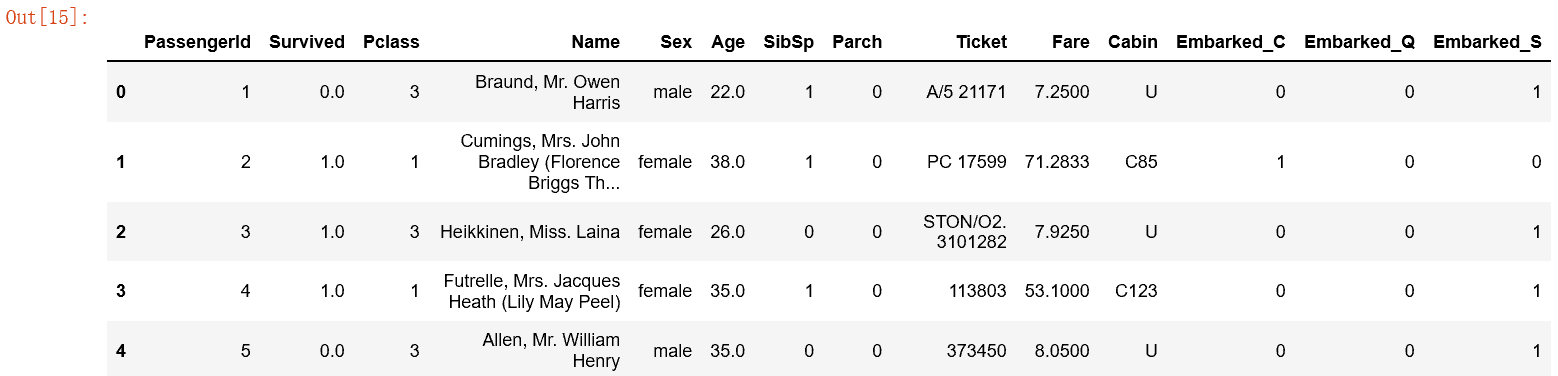
从上图中,我发现survived,Age ,Fare ,Cabin ,embarked都存在数据缺失的情况。数值int类型缺失处理:使用平均值进行填充:
#年龄age
字符串string 类型缺失值处理:
#登船港口embarked
full['Embarked'].head()
'''
#船舱号 cabin full['Cabin'].head()
#由于船舱号的缺失数据较多,缺失值填充为U,表示未知unknown
full['Cabin']=full['Cabin'].fillna('U')- 特征提取

特征提取分为:
1.数值类型:直接使用
2.时间序列类型:转成单独的年、月、日 (该项目中没有此类型)
3.分类数据类型:用数值代替类别,使用one-hot编码
one-hot编码(dummy variable虚拟变量):如果原始数据中有n种类别,则把一种特征拓展成n种特征,将对应的特征拓展为1,其他为0
#分类数据特征提取:性别

#分类数据特征提取:登船港口
full['Embarked'].head()
#存放提取后的特征
embarkedDf=pd.DataFrame()
#使用get_dummies进行one-hot编码,列名前缀是Embarked
embarkedDf=pd.get_dummies(full['Embarked'],prefix='Embarked')
embarkedDf.head()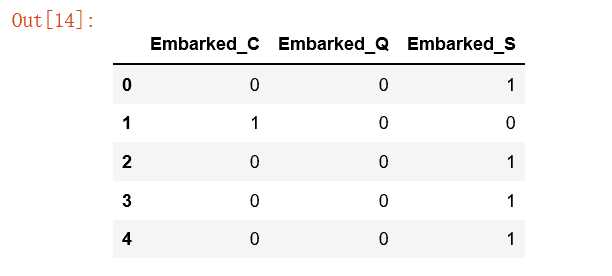
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
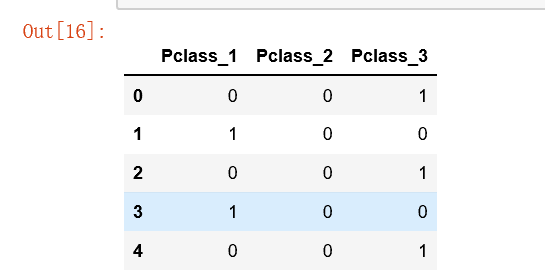
#分类数据特征提取:客舱等级
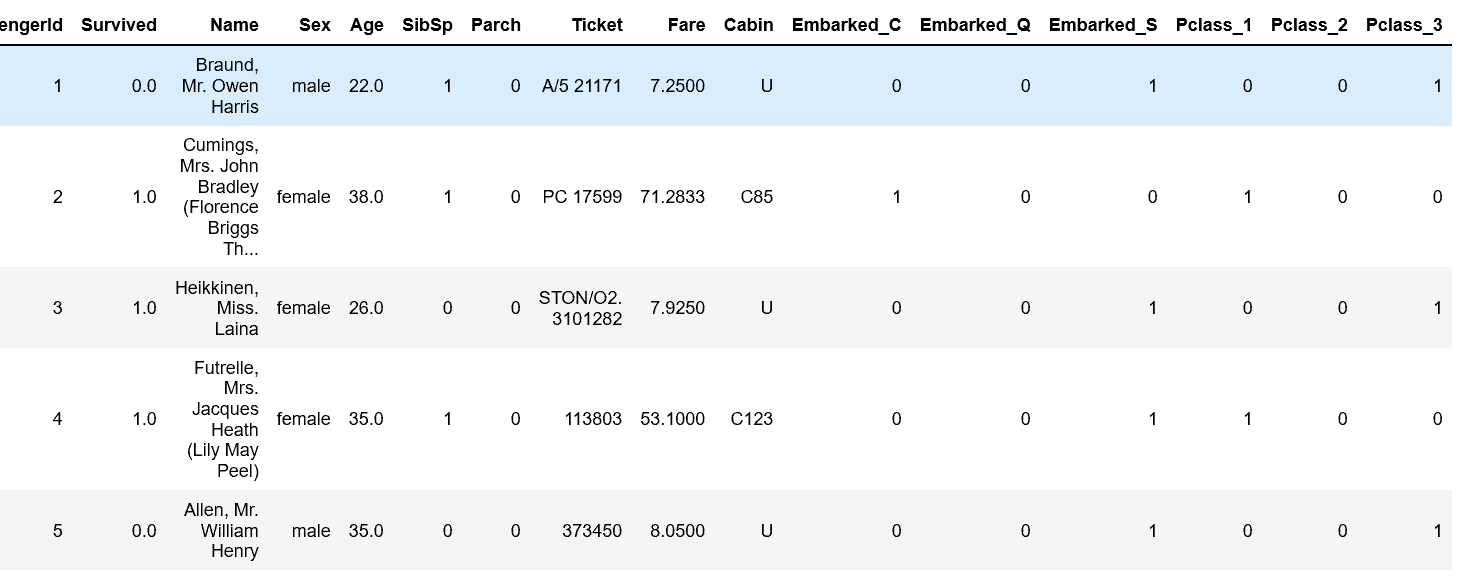
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
#分类数据特征提取:姓名

#定义函数:从姓名中获取头衔,根据名字和头衔后面的标点符号进行分割
def getTitle(name):
str1=name.split(',')[1] #Mr.Owen Harris
str2=str1.split('.')[0] #Mr
#strip()方法用于移除字符串头尾指定的字符(默认为空格)
str3=str2.strip()
return str3
#存放提取后的特征
titleDf=pd.DataFrame()
#map函数:对series每个数据应用自定义的函数计算
titleDf['Title']=full['Name'].map(getTitle)
titleDf.head()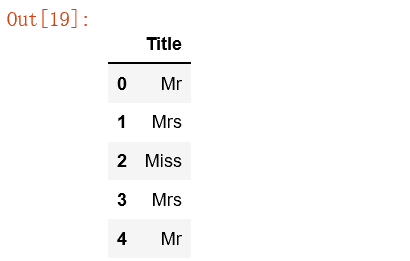
#姓名中头衔字符串与定义头衔类别的映射关系
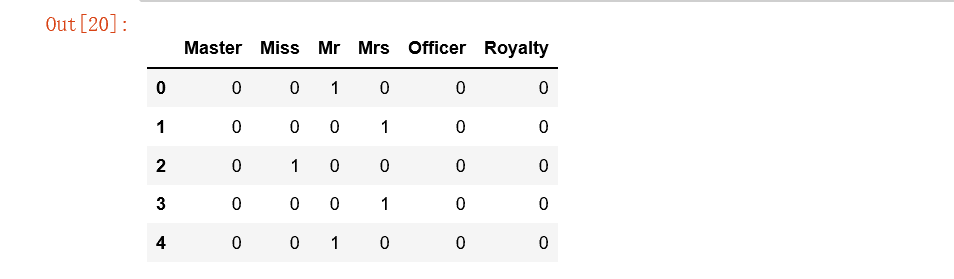
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
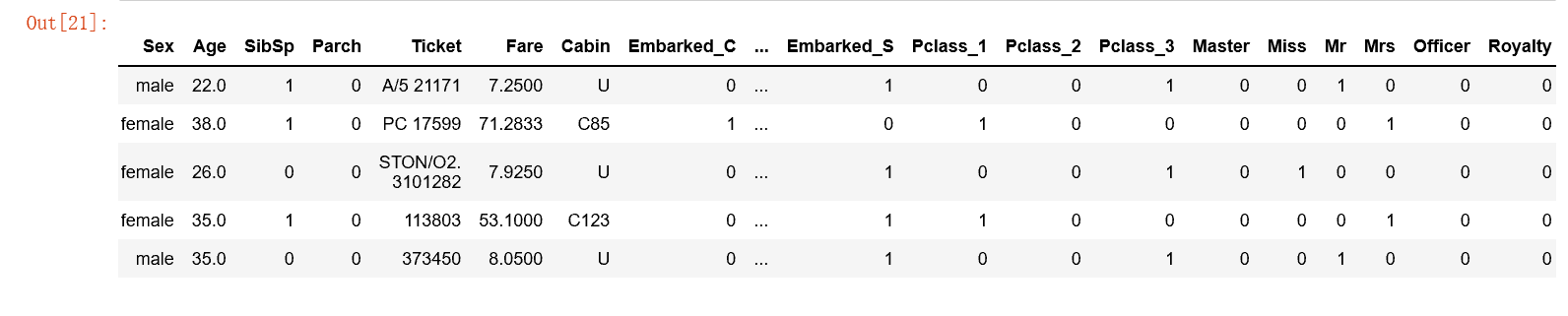
#分类数据提取:客舱号

定义匿名函数:对两个数相加
#语法: lambda 参数1,参数2:函数体或者表达式
sum= lambda a,b:a+b
#调用sum函数
print("相加后的值为:",sum(10,20))
#存放客舱号信息
cabinDf=pd.DataFrame()
'''
客舱号的类别值是首字母,如C85类别映射为首字母C,通过匿名函数找到每一个的船舱首字母
'''
full['Cabin']=full['Cabin'].map(lambda c:c[0])
#使用get-dummies进行one-hot编码,列名前缀是Cabin
cabinDf=pd.get_dummies(full['Cabin'],prefix='Cabin')
cabinDf.head()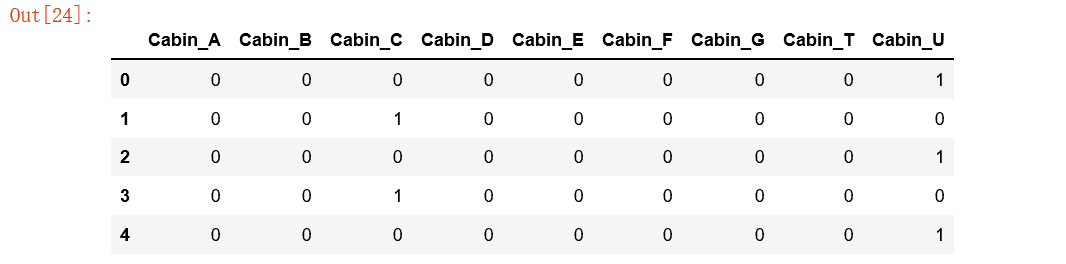
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full
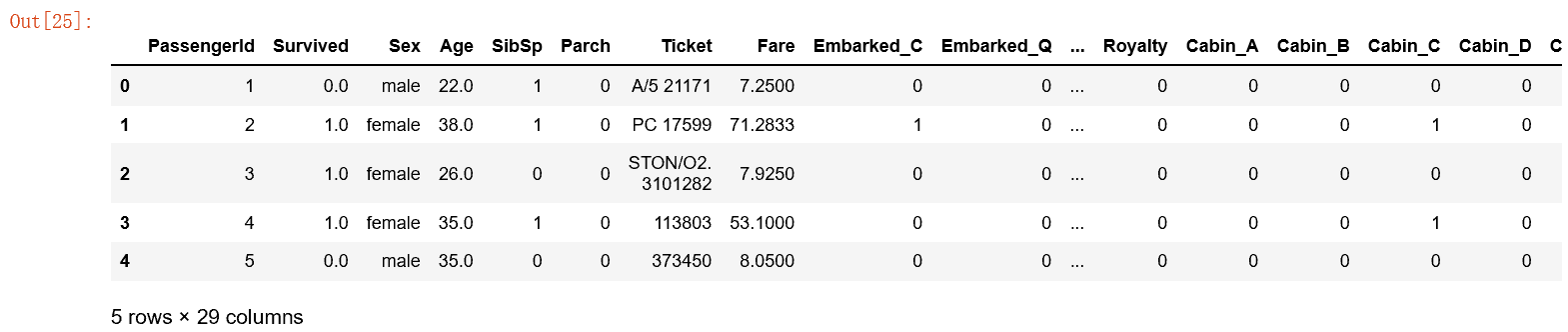
#分类数据特征提取:家庭类别
#添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full

- 特征选择
#到现在已经有了这么多个特征了
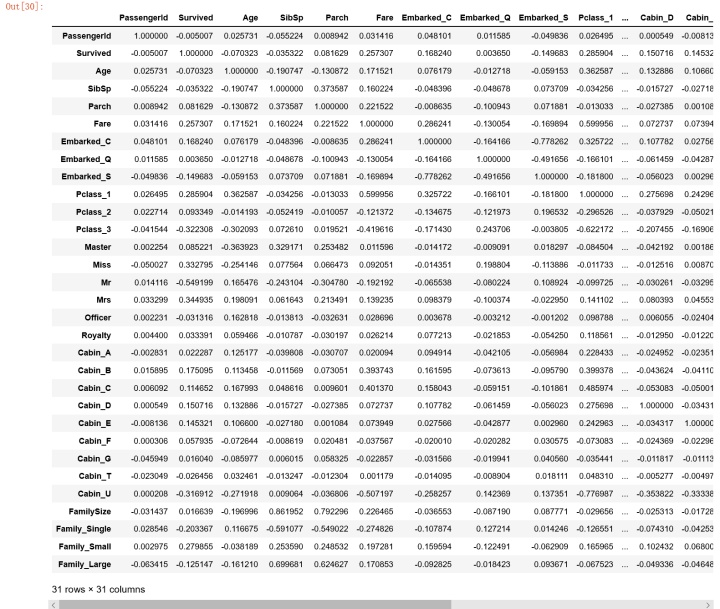
'''
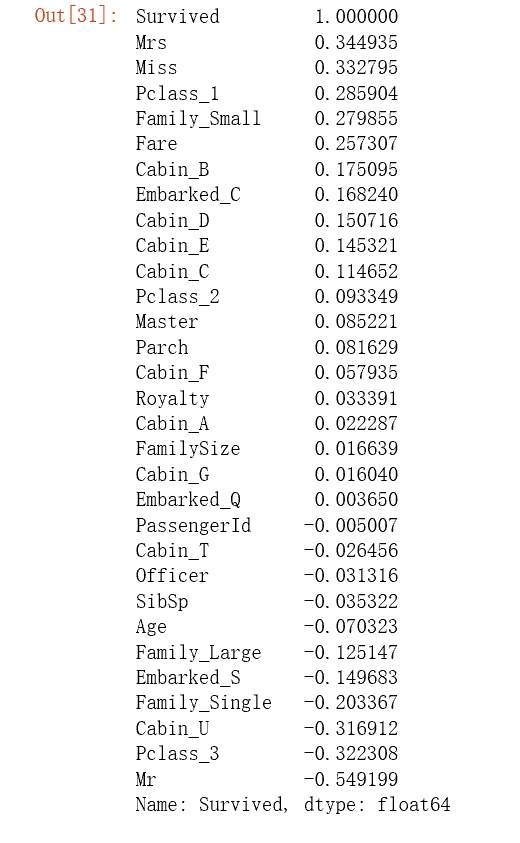
根据各个特征与生成情况(Survived)的相关系数大小,选择了这几个特征作为模型的输入: 头衔(前面所在的数据集titleDf)、客舱等级(pclassDf)、家庭大小(familyDf)、船票价格(Fare)、船舱号(cabinDf)、登船港口(embarkedDf)、性别(Sex)
#特征选择
4.构建模型
'''
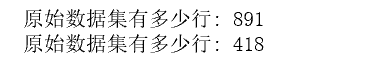
'''
从原始数据集(source)中拆分出训练数据集(用于模型训练train),测试数据集(用于模型评估test)
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
'''
from sklearn.model_selection import train_test_split
#建立模型用的训练数据集和测试数据集
train_X, test_X, train_y, test_y = train_test_split(source_X ,
source_y,
train_size=.8)
#输出数据集大小
print ('原始数据集特征:',source_X.shape,
'训练数据集特征:',train_X.shape ,
'测试数据集特征:',test_X.shape)
print ('原始数据集标签:',source_y.shape,
'训练数据集标签:',train_y.shape ,
'测试数据集标签:',test_y.shape)
- 选择机器学习算法
这次从多种机器学习算法中选择使用逻辑回归模型。
#随机森林Random Forests Model
- 训练模型
#第一步:导入算法
5.评估模型

6.方案实施
使用预测数据集到底预测结果,并保存到csv文件中,上传到Kaggle中,并查看排名。
#使用机器学习模型,对预测数据集中的生存情况进行预测

最终预测结果的排名为6569名。















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









