






 广义线性模型应用举例之泊松回归及R计算
广义线性模型应用举例之泊松回归及R计算
 在前文“广义线性模型 ”中,提到广义线性模型(GLM)可概括为服务于一组来自指数分布族的响应变量的模型框架,正态分布、指数分布、伽马分布、卡方分布、贝塔分布、伯努利分布、二项分布、负二项分布、多项分布、泊松分布、集合分布等都属于指数分布族,并通过极大似然估计获得模型参数。 本篇继续简介广义线性模型的常见子类,泊松回归( poisson regression )。泊松回归假设响应变量服从泊松分布、方差和均值相等,并且假设各组自变量独立(多元回归情形)。当期望通过给定的自变量预测或解释计数型结果变量时,泊松回归是一个非常有用的工具。
在前文“广义线性模型 ”中,提到广义线性模型(GLM)可概括为服务于一组来自指数分布族的响应变量的模型框架,正态分布、指数分布、伽马分布、卡方分布、贝塔分布、伯努利分布、二项分布、负二项分布、多项分布、泊松分布、集合分布等都属于指数分布族,并通过极大似然估计获得模型参数。 本篇继续简介广义线性模型的常见子类,泊松回归( poisson regression )。泊松回归假设响应变量服从泊松分布、方差和均值相等,并且假设各组自变量独立(多元回归情形)。当期望通过给定的自变量预测或解释计数型结果变量时,泊松回归是一个非常有用的工具。
生物学数据中很多都是计数型数值,通常具有这些特点:(1)数值是离散的,并且只能是非负整数;(2)数值分布倾向于在特定较小范围内聚集,并具有正偏态的分布特征;(3)通常会出现很多零值;(4)方差随均值而增加。
某些计数型变量可以通过正态分布进行近似,并可以使用一般线性回归进行合理建模。但更普遍做法是使用广义线性模型,如泊松回归或负二项回归,它们都是应用于计数型(非负整数)响应变量的回归模型。泊松或负二项分布都是离散的概率分布,具有两个重要的属性:(1)数值仅包含非负整数;(2)方差是均值的函数。在早期,计数数型变量常通过数据变换或通过非参数假设检验进行分析,现如今更普遍使用广义线性模型方法的主要原因是可以获得可解释的参数估计。
关于负二项回归在前文“负二项回归”中已作过简介。下文则主要以一个简单示例,展示泊松回归在R语言中的计算过程,及对结果的解读。
R语言执行泊松回归的简单示例
节选了马里兰州河流生物资源调查(https://dnr.maryland.gov/streams/Pages/mbss.aspx)的部分数据,一个生物学目的是探索可能影响鱼类物种丰度的环境因素,并对物种丰度变化的原因作出解释。
下文的测试数据,R代码等的百度盘链接(提取码,60w9):
https://pan.baidu.com/s/1Js7kO5R3uL_u6-67mkv3_A
若百度盘失效,也可在GitHub的备份中获取:
https://github.com/lyao222lll/sheng-xin-xiao-bai-yu
示例数据概要
就节选的部分数据为例,记录了所调查的马里兰州河流中每75米长的区段水域内,鱼类物种Rhinichthys cataractae的丰度,并测量了每段水域中相应的环境特征。
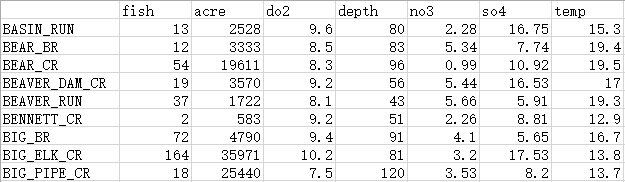
其中第一列代表了调查河流区段的位置信息,其余各列依次为:
fish,水域中R. cataractae的个体数量,代表了物种丰度,一组计数型变量;
acre,水域流域面积(英亩,acre);
do2,水域溶解氧含量(毫克/升,mg/L);
depth,水域最大深度(厘米,cm);
no3,水域硝酸盐浓度(毫克/升,mg/L);
so4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









