







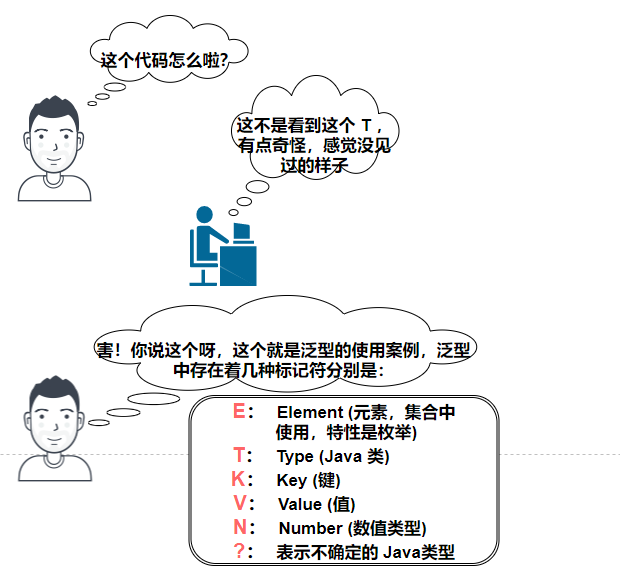
我们上面既然都说到了泛型,那么我们这篇文章就来重新复习一下泛型吧!
一、初识泛型
在没有泛型的出现之前,我们通常是使用类型为 Object 的元素对象。比如我们可以构建一个类型为 Object 的集合,该集合能够存储任意数据类型的对象,但是我们从集合中取出元素的时候我们需要明确的知道存储每个元素的数据类型,这样才能进行元素转换,不然会出现 ClassCastException 异常。
1. 什么是泛型
泛型是在 Java1.5 之后引入的一个新特性,它特性提供了编译时类型安全监测机制,该机制允许我们在编译时监测出非法的类型数据结构。
它的本质就是参数化类型,也就是所操作的数据类型被指定为一个参数。这种参数类型可以用在 类、接口和方法 中,分别被称为 泛型类、泛型接口和泛型方法
2. 使用好处类型安全
有了泛型的存在,只要编译时没有出现警告,那么运行时就不会出现 ClassCastException 异常。消除强制类型转换
从泛型集合中取出元素我们可以不用进行类型的转换可读性更高
可以直接看出集合中存放的是什么数据类型的元素
二、泛型的使用
1. 使用场景
1)泛型类
基本语法class 类名称 {
private 泛型标识 变量名;
.....
}
使用示例class Result{
private T data;
}
注:Java 1.7 之后可以进行类型推断,后面 <> 中的具体的数据类型可以省略不写:类名 对象名 = new 类名<>();如果我们使用的时候没有用到 <> 来制定数据类型,那么操作类型则是 Object
泛型内的类型参数只能是类 类型,而不能是基本数据类型,例如int,double,float...
当我们传入不同数据类型进行构造对象时,逻辑上可以看成是多个不同的数据类型,但实际上都是相同类型


以上便是泛型类的简单用法,我们想要使用哪种类型,就在创建的时候指定类型,使用的时候,该类就会自动转换成用户想要使用的类型。
那么如果我们定义了一个泛型类,构造对象的时候却没有声明数据类型,那么默认为 Object 类型,取出数据的时候则需要进行类型转换:Result objectRes = new Result("testObejct");
String str = (String) objectRes.getData();
System.out.println(str);
规则:子类也是泛型类,那么子类和父类的泛型类型要一致public class ResultChild extends Result{}子类不是泛型类,那么父类要指定数据类型public class ResultChild extends Result{}
2)泛型接口
基本语法public 接口名称 {
泛型标识 方法名();
...
}
使用示例public interface ResultInterface{
T getData();
}
泛型接口与泛型类一样,有以下规则:实现类不是泛型类,接口要明确数据类型
实现类也是泛型类,实现类和接口的泛型类型要一致
3)泛型方法
在 Java 中,泛型类和泛型接口的定义相对比较简单,但是 泛型方法 就比较复杂。泛型类,是在实例化类的时候指明泛型的具体类型
泛型方法,是在调用方法的时候指明泛型的具体类型
基本语法修饰符 返回值类型 方法名(形参列表){}修饰符与返回值类型之间的 用于声明此方法为泛型方法
只有声明了 的方法才是泛型方法,就算返回值类型中的泛型类使用泛型的成员方法也并不是泛型方法
表明该方法将使用泛型类型 T,此时才可以在方法中使用泛型类型 T
使用示例private Result getResult(T data){
return new Result(data);
}
泛型方法与可变参数:private void printData(T... data){
for (T t : data) {
System.out.println(t);
}
}
注:泛型方法能使方法独立于类而产生变化
如果 静态(static) 方法 要使用泛型能力,就必须使其成为泛型方法
2. 类型通配符
1)什么是类型通配符类型通配符一般使用 " ? " 代替具体的实参类型
类型通配符是 实参类型 ,而不是 形参类型
类型通配符又分为 类型通配符的上限 和 类型通配符的下限
2)基本语法
类型通配符的上限:类/接口 extends 实参类型>
注:要求该泛型的类型,只能是实参类型,或实参类型的 子类 类型
类型通配符的下限:类/接口 super 实参类型>
注:要求该泛型的类型,只能是实参类型,或实参类型的 父类 类型
2)使用示例
类型通配符的上限:
如果我们要打印一个 List 的值,我们可能会这么做:private void printData(List list){
for (int i = 0; i
System.out.println(list.get(i));
}
}
看上去没啥问题,但是又觉得怪怪的。因为这就跟黑匣子一样,我根本不知道这个 List 里面装的是什么类型的参数。那我们就在传参的时候定义一下类型:private void printData(List list){
for (Object o : list) {
System.out.println(o);
}
}
但是这样定义又太广泛了,Object 是所有类型的父类,如果说我想这个方法只能操作数字类型的元素,那我就能用上 类型通配符的上限 来解决这个问题了:private void printData(List extends Number> numList){
for (Number number : numList) {
System.out.println(number);
}
}
但我们需要使用这个方法时候我们就很直观的可以看出来,这个方法传的实参只能是 Number 的子类。printData(Arrays.asList(1, 2, 3));
printData(Arrays.asList(1L, 2L, 3L));
类型通配符的下限:
上面我们了解到 类型通配符上限的使用 ,那么 类型通配符上限 是如何使用的?
类型通配符上限 在我们平时开发中使用的频率也相对较少。编译器只知道集合元素是下限的父类型,但具体是哪一种父类型是不确定的。因此,从集合中取元素只能被当成Object类型处理(编译器无法确定取出的到底是哪个父类的对象)。
我们可以自定义一个复制集合的函数:首先定义两个类:public class Animal{
}
public class Pig extends Animal{
}定义一个复制函数:private static Collection super T> copy(Collection super T> parent, Collection child) {
for (T t : child) {
parent.add(t);
}
return parent;
}使用:List animals = new ArrayList<>();
List pigs = new ArrayList<>();
pigs.add(new Pig());
pigs.add(new Pig());
copy(animals,pigs);
System.out.println(animals);
3. 类型擦除
因为泛型信息只存在于代码编译阶段,所以在进入 JVM 之前,会把与泛型相关的信息擦除,这就称为 类型擦除
1)无限制类型擦除
类型擦除前:public class Result{
private T data;
}
类型擦除后:public class Result{
private Object data;
}
2)有限制类型擦除
类型擦除前:public class Result{
private T data;
}
类型擦除后:public class Result{
private Number data;
}
3)擦除方法中类型定义的参数
类型擦除前:private T getValue(T value){
return value;
}
类型擦除后:private Number getValue(Number value){
return value;
}















 4512
4512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









