





通过对文本序列的学习,word2vec将每个词表示为一个低维稠密的向量(Embedding),且该向量能够包含词本身的语义,体现词之间的关系。
最简单常见的词向量表示是one-hot形式,该形式的词向量维度为整个词汇表的大小,但是由于词汇表一般都很大,导致向量非常稀疏,不仅占用资源,对于神经网络之类的某些算法模型直接使用也不友好,除此之外,该形式的向量也无法包含词本身的语义信息。而Embedding可以很好的解决上述问题。
在word2vec出现之前,也有DNN的方式可以计算词向量,一般为三层网络结构:输入层、隐藏层、输出层,主要分CBOW(Continuous Bag-of-Words)和Skip-Gram两种模型。
CBOW以某一特征词w(t)的上下文词的one-hot向量作为输入,该特征中心词w(t)为输出,隐藏层的神经元数量是一个超参,其决定着embedding得到的维度大小。学习到各层之间的映射关系之后,可以根据映射矩阵将one-hot表示的词映射到embedding空间中。Skip-Gram与CBOW相反,将中心词作为输入,上下文词作为输出,输出层softmax中取Top N(此处N为上下文词个数)。
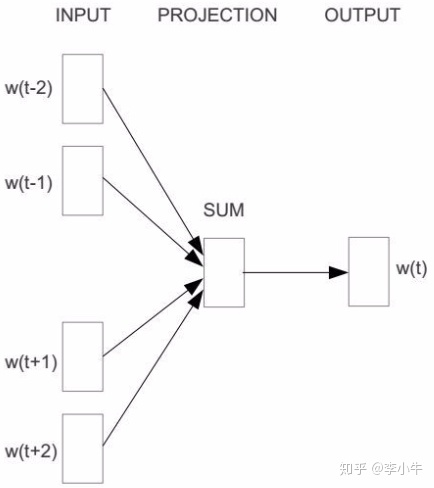

传统的DNN求解CBOW和Skip-Gram模型时,需要对所有词汇表中的词做softmax,计算量巨大,word2vec提出了两种改进方式,以解决传统DNN求解时的计算量难题。
Hierarchical Softmax
对传统DNN求解词向量有两个改进:首先,输入层到隐藏层的映射简化为对所有输入词向量求平均(此处的词向量为随机初始化得到的embedding空间向量);其次,隐藏层到输出层softmax的映射替换为赫夫曼树。
赫夫曼树按照样本的词频构建,每个叶子节点代表一个词,其根节点相当于输入的embedding空间词向量,内部节点相当于传统DNN模型中隐藏层的神经元,叶子节点相当于传统DNN模型中softmax输出层的神经元。通过构建赫夫曼树,将对所有词汇的softmax计算转化为沿着赫夫曼树从根节点往叶子节点一步步进行二元逻辑回归求解,将求解计算量从V(词汇表大小)降到
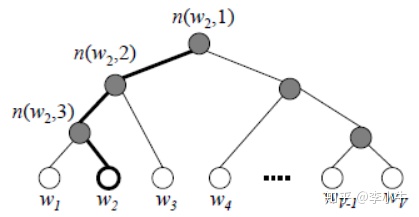
赫夫曼树中,规定沿着左子树走是负类(编码为1),沿着右子树走是正类(编码为0),判别正类和负类的方法是使用sigmoid求其相应概率:
其中,
以上述huffman树图为例,如果w2是一个训练样本的输出,那么,我们期望最大化下面的似然函数:
对于所有样本,期望最大化所有样本的似然函数乘积。
设,输出入的词为w,其从输入层词向量求平均后的赫夫曼树根节点词向量为
其中,
那么,对于一个目标输出词w,其最大似然为:
其中,
在word2vec中,使用随机梯度上升法更新参数,使用的损失为对数似然:
那么,模型中内部节点的模型参数
- 基于Hierarchical Softmax的CBOW模型
input:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长![]()
output:赫夫曼树内部节点模型参数,所有的词向量
![]()
1. 基于语料训练样本建立赫夫曼树
2. 随机初始化所有模型参数、所有的词向量
![]()
3. 进行梯度上升迭代过程,对于训练集中的每个样本(context(w), w)做如下处理:
a)e=0,计算![]()
b)for j=2 to,计算:
![]()
![]()
![]()
![]()
c)对于context(w)中的每个词向量(共2c个),进行更新:
![]()
d)如果梯度收敛,则结束迭代,否则回到步骤3继续迭代
- 基于Hierarchical Softmax的Skip-Gram模型
input:基于Skip-Gram的语料训练样本,词向量的维度大小M,Skip-Gram的上下文大小2c,步长![]()
output:赫夫曼树内部节点模型参数,所有的词向量
![]()
1. 基于语料训练样本构建赫夫曼树
2. 随机初始化所有的模型参数、所有的词向量
![]()
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(w, context(w))做如下处理:
a)for i=1 to 2c:
i)e = 0
ii)for j=2 to,计算:
![]()
![]()
![]()
![]()
iii)![]()
b)如果梯度收敛,则结束迭代,算法结束;否则,回到步骤a)继续迭代
* 通过梯度上升法更新
Negtive Sampling
Hierarchical Softmax的缺点在于:如果中心词是一个很生僻的词,会在赫夫曼树中向下走很久。word2vec的另一种求解方式Negtive Sampling没有这样的问题。
Negtive Sampling,通过负采样一些负例加入训练,减少了每个样本训练中需要更新的参数个数,从而起到了降低训练复杂度的作用。具体方法为:设一个训练样本的中心词是
设,正例期望满足:
负例期望满足:
期望可以最大化下式:
此时模型的似然函数为:
相应的对数似然为:
用随机梯度上升算法优化,此时对应的参数、向量梯度为:
- 基于Negtive Sampling的CBOW模型
Input:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长,负采样个数neg
output:词汇表每个词对应的模型参数,所有的词向量
![]()
1. 随机初始化所有的模型参数、所有的词向量
![]()
2. 对于每个训练样本,负采样出neg个负例中心词
![]()
3. 进行梯度上升过程,对于训练集中每个样本做如下处理:
a)e=0,计算![]()
b)for i=0 to neg,计算:![]()
![]()
![]()
![]()
c)对于中的每个词向量
(共2c个)进行更新:
![]()
d)如果梯度收敛,则结束梯度迭代;否则,回到步骤3继续迭代
- 基于Negtive Sampling的Skip-Gram模型
input:基于Skip-Gram的语料训练样本,词向量的维度大小M,Skip-Gram的上下文大小2c,步长,负采样的个数neg
output:词汇表每个词对应的模型参数、所有的词向量
![]()
1. 随机初始化所有的模型参数、所有的词向量
![]()
2. 对于每个训练样本,负采样出neg个负例中心词
![]()
3. 进行梯度上升迭代,对训练集中每个样本做如下处理:
a)for i=1 to 2c:
i)e=0
ii)for j=0 to neg,计算:![]()
![]()
![]()
![]()
iii)词向量更新:![]()
b)如果梯度收敛,则结束梯度迭代,算法结束;否则,回到步骤a)继续迭代
算法对比
- Skip-Gram vs CBOW:
1)时间复杂度:Skip-Gram训练一轮的时间复杂度是:O(2c*V);CBOW训练一轮的时间复杂度是:O(V)。
2)词向量更新:Skip-Gram训练中,一个训练样本对上下文2c个词向量的更新梯度是不同的;CBOW训练中,一个训练样本对上下文2c个词向量的更新梯度是相同的。Skip-Gram中词向量的更新更加精细(或者说更加个性化),对生僻词的训练效果会更好。
- Hierarchical Softmax vs Negtive Sampling:
实验结果看来,Hierarchical Softmax对生僻词的效果更好。(来源:https://code.google.com/archive/p/word2vec/)
源码实现中的小trick
1)Negtive Sampling负采样:
将一段长度为1的线段分成V份(词汇表大小为V),每份对应词表中一个词,每个词对应线段的长度不同:
采样前,将这段长度为1的线段分成M等份(这里M>>V),在采样的时候,只需要从M个位置中采样出neg个位置,此时采样到的每个位置对应到的线段所属词就是负例词了。
由上述公式给定词对应的长度,对比用词频占比给定词对应长度来说,高频词的长度优势相对低频词长度的优势会降低一些,起到了一定的提高低频词被采样概率的作用。
2)下采样:
获取训练样本时,用sub_sampling随机舍弃一些词(即,当做句子中从一开始就不存在这个被舍弃的词),高频词被舍弃的概率更高。这样可以提高低频词的训练效果,且提高训练速度。
具体做法:对word生成一个数值ran(与词频相关,词频越大ran越小),再生成一个随机数,如果ran小于这个随机数,就丢弃当前word。
3)多线程训练:
将文本切分,每个线程训练一部分文本。参数更新过程中似乎没有做信息同步,参数是一个全局共享的大数组,更新了就往里写,一般词表很大而线程不会太多,冲突概率比较低。
参考资料:
word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(三) 基于Negative Sampling的模型
注释版源码














 1588
1588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









