






本教程适用于对八爪鱼自定义模式有定操作基础,且学习过 XPath 基础教程,能看懂并书写简单的 XPath 路径。否则,您可能无法看懂该教程,建议先掌握基础操作。
&version=v7.0
在 Xpath 语法中元素定位主要有两种方式
第一种:通过绝对路径做定位(定位较为死板)
By.xpath ( "html/body/div/form/input" )
第二种:通过相对路径做定位,两个斜杠代表相对路径
By.xpath ( "//input//div" )
示例:
需求:采集整个城市列表和其所对应的省份。
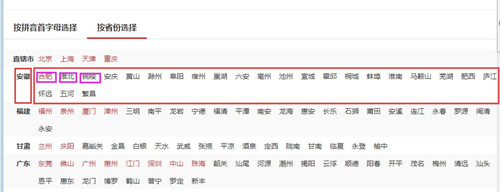
第一步:分析网页和需求
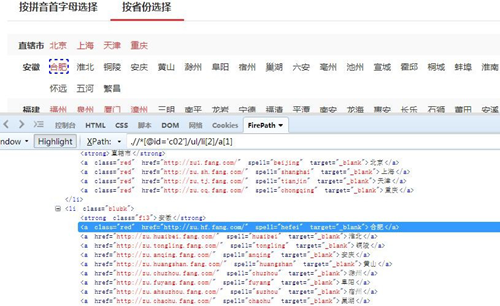
从源码中可发现城市和省份并不是同一类型的元素,省份所在位置对城市而言有个相对位置。此外如果将城市和省份一同建立循环,也不便获取到省份与城市一一对应的数据样式, 故此处我们以城市建立循环。
第二步:创建任务,编辑规则
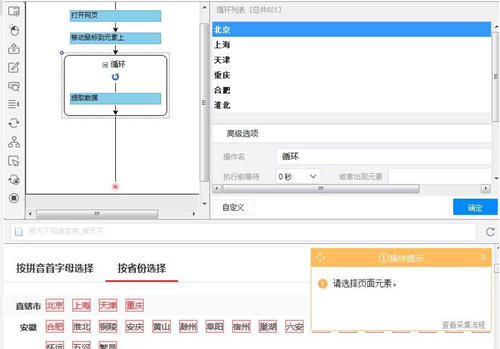
以城市创建循环后,直接进行提取。手动执行到其他城市时,发现虽然城市信息能够准确提
取到,但是省份信息出现错乱。这是由于省份的 Xpath 设置不对,未能正确产生联动,使之和城市相关联。
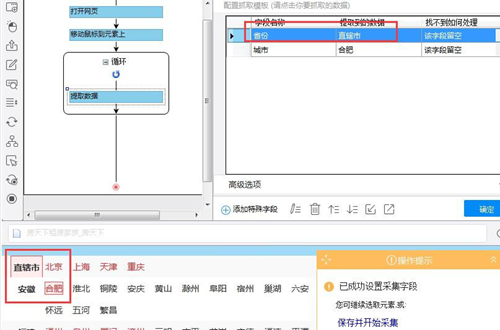
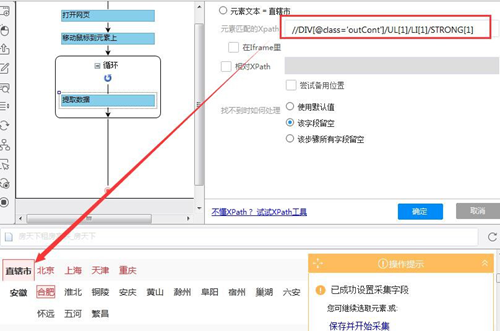
红框中为自动生成的 Xpath(//DIV[@class='outCont']/UL[1]/LI[1]/STRONG[1]),其每次固定定位到“直辖市”。根据需求省份要和城市相对应,所以在采集城市时,省份的 Xpath 要相对于城市而发生变化,形成联动而不是固定到某一个元素。
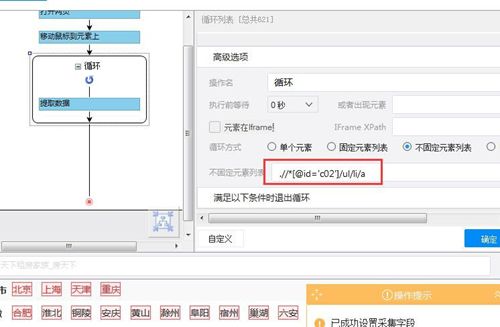
首先我们回到循环中找到循环列表的 Xpath(.//*[@id='c02']/ul/li/a),复制该 Xpath 到火狐浏览器中。
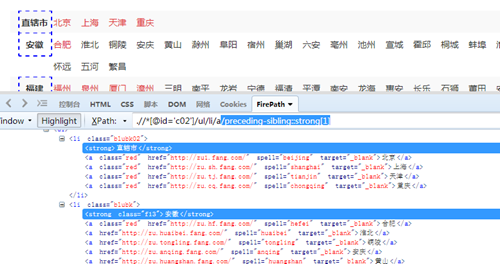
在火狐浏览器中写出“省份”相对于“城市”列表(.//*[@id='c02']/ul/li/a)所对应的 Xpath
(/preceding-sibling::strong[1])。(Ps:以循环列表的 Xpath 为前缀,写出要采集字段的 Xpath)
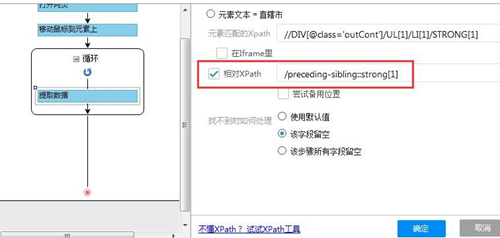
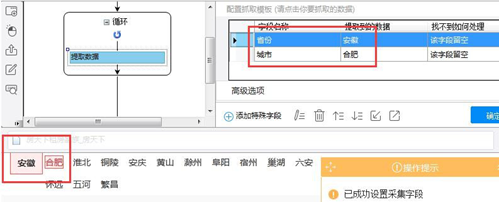
在“省份”的元素定位方式中勾选上“相对 Xpath”,然后在输入框中粘贴之前写下相对 Xpath
(/preceding-sibling::strong[1]),最后确定保存。
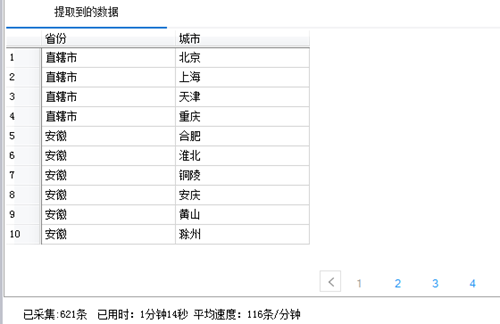
手动执行检查验证,已能联动,正确提取到相应数据。
本地采集结果















 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









