






本文是根据穷码农的LeetCode刷题建议而进行专项练习时记录的心得。
在经过了财务比赛的洗礼后,我还是回归到了日复一日的刷题模式当中。考虑到可能会看我文章的读者在阅读中文时会更加轻松,从这篇文章开始LeetCode的题目将以中文形式显示。
今天的笔记包含基于改造二分法(Modified Binary Search)类型下的7个题目,它们在leetcode上的编号和题名分别是:
- 704 - 二分查找
- 74 - 搜索二维矩阵
- 33 - 搜索旋转排序数组
- 81 - 搜索旋转排序数组 II
- 153 - 寻找旋转排序数组中的最小值
- 162 - 寻找峰值
- 744 - 寻找比目标字母大的最小字母
下面将根据以上顺序分别记录代码和对应心得,使用的编译器为Pycharm (Python3)。
二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1提示:
你可以假设 nums 中的所有元素是不重复的。
n 将在 [1, 10000]之间。
nums 的每个元素都将在 [-9999, 9999]之间。
这一节既然是改进二分法,那么一定先得熟悉原本的二分法才行。题目要求很简单,直接套用原始的二分法就可以得出答案。需要注意的是,左右指针在循环比较时一定得是”小于等于“,否则会漏掉一些情况。标准的二分搜索法时间复杂度是O(log n)。
class Solution:
def search(self, nums: list, target: int) -> int:
# Solution: Original Binary Search. 标准的二分法。
# Special considerations
if len(nums) == 0:
return -1
# Parameters
left = 0
right = len(nums) - 1
# Binary Search。 Attention: must have '=' symbol when comparing
while left <= right:
mid = left + (right - left) // 2 # prevent out of index error
if target == nums[mid]:
return mid
elif target < nums[mid]:
right = mid - 1
elif target > nums[mid]:
left = mid + 1
return -1搜索二维矩阵
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
示例 1:
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 3
输出: true
示例 2:
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 13
输出: false这道题我采用了两种解法。一种是双层二分(二分嵌套),一种是单个二分(需要对数组的索引方式进行转换)。
双层二分的思路比较简单。先将matrix列表里的子列表当成”一个元素“,并利用每个子列表首尾元素与target进行对比,确定target被包含在哪个子列表之中;然后,再用标准二分法,求得target的最终位置。因为二分法是嵌套使用的,所以我认为它的时间复杂度是O(log (m*n))。
class Solution:
def searchMatrix(self, matrix: list, target: int) -> bool:
# solution: 双层二分法。
# pecial considerations
if len(matrix) == 0:
return False
if len(matrix[0]) == 0:
return False
# arameters (pointers)
leftM = 0
rightM = len(matrix) - 1
while leftM <= rightM:
midM = leftM + (rightM - leftM)//2
if matrix[midM][0] <= target <= matrix[midM][-1]:
# Normal binary search
left = 0
right = len(matrix[midM]) - 1
while left <= right:
mid = left + (right-left)//2
if matrix[midM][mid] == target:
return True
elif matrix[midM][mid] > target:
right = mid - 1
elif matrix[midM][mid] < target:
left = mid + 1
return False
elif matrix[midM][0] > target:
rightM = midM - 1
elif matrix[midM][-1] < target:
leftM = midM + 1
return False采用一次二分查找自然就是更先进的办法了。因为二维列表的元素有序并且每个子列表合在一起也遵循递增原则,所以可以将所有元素通过数学方法"串在一起",进而使用一个二分法便可求得答案。所谓数学方法,就是利用取模和取余定位每个元素的位置,便于统一比对matrix的元素与target的大小关系。
但需要特别关注的是,取模与取余的底均为每个子列表拥有的元素个数(column)。该算法的时间复杂度为O(log n)。
class Solution:
def searchMatrix(self, matrix: list, target: int) -> bool:
# Advanced solution: 单次二分。
# Special considerations
if len(matrix) == 0:
return False
if len(matrix[0]) == 0:
return False
row = len(matrix)
column = len(matrix[0])
left = 0
right = row * column - 1
while left <= right:
mid = left + (right-left)//2
# Get the position using math (attention: when converting 1-D array back to 2-D coordinate,
# the divider is the number of elements a sub-list has)
rowPosition = mid // column
colPosition = mid % column
if matrix[rowPosition][colPosition] == target:
return True
elif matrix[rowPosition][colPosition] < target:
left = mid + 1
else:
right = mid - 1
return False搜索旋转排序数组
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。
示例 1:
输入: nums = [4,5,6,7,0,1,2], target = 0
输出: 4
示例 2:
输入: nums = [4,5,6,7,0,1,2], target = 3
输出: -1到了这里,”改进”二分法才算是出现了。因为题目给出的输入列表均为经过旋转后的列表,无法直接通过原生二分法进行查找(整体无序),所以需要将二分法改进。
想要使用二分法,前提条件是列表有序(特殊条件除外)。因为旋转后的列表某一部分仍旧有序,所以我们可以通过“中间值”定位到有序的那部分,并使用二分法求得target的位置。这里的“中间值”,我们也是借用了二分法中能排除一半元素的思想,减少挨个比对所增加的时间复杂度。
具体思路是这样的:一开始,用二分法的思路求得起始的左右指针与该旋转列表的“中间值”,然后判断第一个元素与”中间值“的大小,以确定该子列表是否是递增的。如满足,则判断第一个元素是否小于等于目标值,同时”中间值“是否大于等于目标值,从而进一步判断目标值是否属于该区间;若不满足递增,则说明后半段子列表是递增的,此时就判断目标值是否处于”中间值“与结尾值之间(与上述方法相同)。
在判断完目标值是否属于特定的区间后,移动相应指针以缩减范围,并判断此时的起始值&结尾值是否等于目标值。若不等于,继续循环下去,直到左右指针错位为止。
因为题目要求时间复杂度为O(log n), 所以最终的时间复杂度也是O(log n)。
class Solution:
def search(self, nums: list, target: int) -> int:
# solution: (改进)二分查找。
# Special consideration(s)
if len(nums) == 0:
return -1
# Parameters
left = 0
right = len(nums)-1
while left <= right:
# Get the middle index
mid = left + (right - left) // 2 # will not cause index error
# When right - left <= 1 or encounter duplicated numbers
if nums[left] == nums[mid]:
left += 1
# If 'left' changes, 'mid' should be changed accordingly
continue
if nums[mid] == target:
return mid
# (important) One more step: decide whether the sublist is in order
if nums[left] < nums[mid]:
# binary test (attention: must write the complete range: the target may not be in the range)
if nums[left] <= target <= nums[mid]:
right = mid
else:
left = mid # filter irrelevant sections
else:
# attention: must write the complete range: the list may not in ascending order
if nums[mid] <= target <= nums[right]:
left = mid
else:
right = mid
# test the left number and right number
if nums[left] == target:
return left
if nums[right] == target:
return right
return -1搜索旋转排序数组 II
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
示例 1:
输入: nums = [2,5,6,0,0,1,2], target = 0
输出: true
示例 2:
输入: nums = [2,5,6,0,0,1,2], target = 3
输出: false进阶:
这是 搜索旋转排序数组 的延伸题目,本题中的 nums 可能包含重复元素。
这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
这道题和打一题极为类似。核心思路都是根据中间值、递增判断来找到目标值是否存在于列表里。但有一个需要注意,因为此次引入了重复值,所以在每次判断列表前半段是否是递增顺序前,必须先判断左指针的值是否与中间值相等(重复元素/快到头了)。如果相等则将左指针加1,并直接跳入下一循环。"直接跳入下一循环"是必须的,因为随着左指针的移动,中间值的指针mid也会相应变化,不能再用原来的值继续计算了。
class Solution:
def search(self, nums: list, target: int) -> bool:
# solution: (similar to the previous one) modified binary search. (判断
# 是否有序前需要多一层判断,毕竟有重复数字的可能)
# Parameters
left = 0
right = len(nums) - 1
# Special considerations
if len(nums) == 0:
return False
while left <= right:
mid = left + (right - left)//2
if target == nums[mid]:
return True
# If the left element is equal to the mid, move to the next one and
# compare again. Otherwise, the target may miss its section.
if nums[left] == nums[mid]:
left += 1
# if 'left' changes, 'mid' should be changed accordingly
continue
# !!! 先判断是否有序 !!!
if nums[left] < nums[mid]:
# whether it is in ascending order
if nums[left] <= target <= nums[mid]:
right = mid
else:
left = mid
else:
if nums[mid] <= target <= nums[right]:
left = mid
else:
right = mid
if nums[left] == target or nums[right] == target:
return True
return False关于LeetCode中的进阶问题,也就是时间复杂度是否变化的问题。我认为在极端情况下,也就是列表全为重复数字时,二分法的复杂度也变成了O(n)。所以出现了重复数字,我认为是会对时间复杂度产生一定影响的,这个时候它是否会大于O(log n)取决于有多少重复数字。
寻找旋转排序数组中的最小值
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
示例 1:
输入: [3,4,5,1,2]
输出: 1
示例 2:
输入: [4,5,6,7,0,1,2]
输出: 0本题的主要思路和之前的差异不大,就是目标值需要自己定义。不过,这个目标值的定义其实还需要一定量的分析才能得出。
首先,我们需要通过旋转后中间值与起始(左侧值)&结尾值(右侧值)的关系来判断我们需要如何定义"目标值"。经过思考,可以得到以下三种情况(第四种被排除):
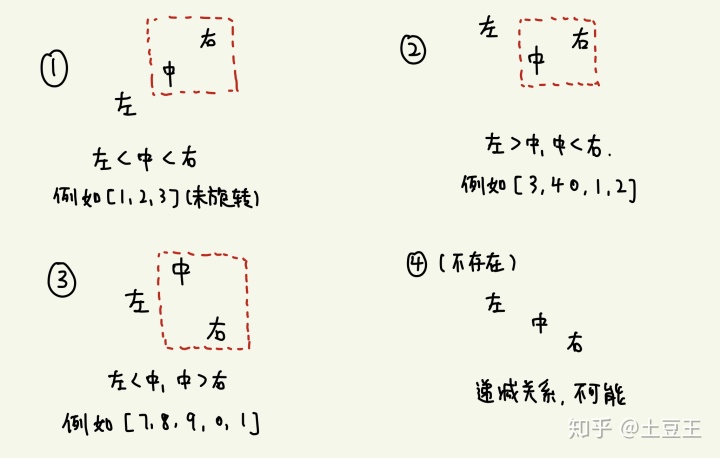
在这三种情况里,通过观察我们可以知道,起始值(也就是中间值左侧值)无法用于判断最小值位于哪个区间。因为情况1与情况3都是左侧值小于中间值,但最小值所在区间不同。因此,将右侧值与中间值进行反复比较,我们就能很好地判断出中间值位于哪个区间,并相应移动左侧或右侧指针来缩小区间范围(若中>右,说明最小值在右侧,移动左指针;若中<右则相反),最终求得最小值。
由于移动的过程中,左指针无论移至何处,都遵循"left <= mid < right" 这一特性,所以在进行while循环时,只需保证left < right 即可。最后跳出循环时,一定是"left = right"的情况。因为上一轮循环里要么end大于mid使得left右移了一位,要么right等于mid时左移了一位,导致了两者相等(区间只剩两个元素了),此时跳出循环直接输出left对应的值即为最小值。该算法的时间复杂度仍为O(log n)。
class Solution:
def findMin(self, nums: list) -> int:
# solution:利用二分法的中间值与右侧值对比。
# parameters
start = 0
end = len(nums) - 1
# special considerations
if len(nums) == 0:
return None
while start < end:
mid = start + (end-start)//2
if nums[mid] > nums[end]:
start = mid + 1
else:
end = mid
return nums[start]寻找峰值
峰值元素是指其值大于左右相邻值的元素。
给定一个输入数组 nums,其中 nums[i] ≠ nums[i+1],找到峰值元素并返回其索引。
数组可能包含多个峰值,在这种情况下,返回任何一个峰值所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞。
示例 1:
输入: nums = [1,2,3,1]
输出: 2
解释: 3 是峰值元素,你的函数应该返回其索引 2。
示例 2:
输入: nums = [1,2,1,3,5,6,4]
输出: 1 或 5
解释: 你的函数可以返回索引 1,其峰值元素为 2;或者返回索引 5, 其峰值元素为 6。说明:
你的解法应该是 O(log n) 时间复杂度的。
这道题本来看不出是要用二分法,毕竟列表无序。但要求时间复杂度为O(log n)时,第一眼便能联想到二分了。可列表本身是无序的呀,也不是经过旋转得到的呀。这个时候,题目又给出了两个附加条件:nums[i] != nums[i+1] 和 nums[−1]=nums[n]=−∞。第一点好理解,就是相邻元素不相等;但第二点我就有点困惑了。我一开始硬是没有理解它的含义,所以不知道如何用二分法解决这个问题。
在查看了解析后,我发现这句话的意思是"列表-1和无穷大(也就是边界)都是负无穷"。隐含之意就是元素不管怎么变化,都会在边界跌下去。也就是说,无论怎么分割列表,子列表都存在峰值。因此,列表虽然无序,但却能够借助这个特殊条件,使用二分法不断排除一半的元素,以较低的时间复度确认峰值的位置。
整体思路:首先利用二分法确定中间值,并比较中间值与中间值后一位的值的大小。如果后一位更大,那说明峰值在右侧,就得移动left的位置;如果中间值更大,则说明峰值在左侧,需要移动right的位置。当循环结束时,便是left=right的时候,此时只需输出left或者right即可。
class Solution:
def findPeakElement(self, nums: list) -> int:
# solution: 二分法(特殊条件)。
# Special considerations
if len(nums) == 0:
return
# Parameters
left = 0
right = len(nums) - 1
while left < right:
mid = left + (right - left) // 2
# Confirm the interval that the peak element belongs to
if nums[mid] > nums[mid + 1]:
right = mid
elif nums[mid] < nums[mid + 1]:
left = mid + 1
return left寻找比目标字母大的最小字母
给你一个排序后的字符列表 letters ,列表中只包含小写英文字母。另给出一个目标字母 target,请你寻找在这一有序列表里比目标字母大的最小字母。
在比较时,字母是依序循环出现的。举个例子:
如果目标字母 target = 'z' 并且字符列表为 letters = ['a', 'b'],则答案返回 'a'
示例:
输入:
letters = ["c", "f", "j"]
target = "a"
输出: "c"
输入:
letters = ["c", "f", "j"]
target = "c"
输出: "f"
输入:
letters = ["c", "f", "j"]
target = "d"
输出: "f"
输入:
letters = ["c", "f", "j"]
target = "g"
输出: "j"
输入:
letters = ["c", "f", "j"]
target = "j"
输出: "c"
输入:
letters = ["c", "f", "j"]
target = "k"
输出: "c"提示:
letters长度范围在[2, 10000]区间内。
letters 仅由小写字母组成,最少包含两个不同的字母。
目标字母target 是一个小写字母。
这道题的难度是Easy,按理来说十分简单,利用二分法比对target,并用一个变量记录当前的最大值,在每次遍历时更新。最后如果字母没有确定,进行一下特殊处理即可。但是,在题解里有一个大佬指出了测试用例的不完整性:

我试着运行了之前的代码,发现确实不对劲,输出的结果为z。最后发现这道题如果补充了足够的测试用例,其实和”搜索旋转排序数组 II“十分相似。考虑到还可能有重复值,所以有些地方还得进行特殊处理下。
整体思路与”搜索旋转排序数组 II“相似,可参考上面的笔记。
class Solution:
def nextGreatestLetter(self, letters: list, target: str) -> str:
# solution: 普通二分法。用一个变量记录当前的最大值,并在每次遍历时更新。
# Parameters
left = 0
right = len(letters) - 1
maxLetter = ''
# check whether the letters are rotated
if letters[left] < letters[right]:
while left < right: # there is no equal symbol
mid = left + (right - left) // 2
if target < letters[mid]:
maxLetter = letters[mid]
right = mid
else:
left = mid + 1
# when the loop is over, left = right (process equal condition)
if maxLetter == '': # left = len(letters) - 1
if target >= letters[left]:
maxLetter = letters[0]
else:
maxLetter = letters[-1]
else:
# If the letters are rotated, try to identify the letter's location, the same as "Search in
# Rotated Sorted Array II".
while left <= right:
mid = left + (right-left) // 2
# left + 1 = right or left = right
if letters[left] == letters[mid]:
if right - left <= 1:
if letters[left] <= target < letters[right]:
maxLetter = letters[right]
elif target >= letters[right]:
maxLetter = letters[0]
break
else:
# Filter duplicated letters, same as same as "Search in Rotated Sorted Array II".
left += 1
continue
if letters[0] < letters[mid]:
if letters[0] <= target <= letters[mid]:
right = mid
else:
left = mid + 1
else:
if letters[mid] <= target <= letters[right]:
left = mid
else:
right = mid - 1
# when loop is over, left = right. Usually "maxLetter = ''" is because the right side is smaller
# than the target
if maxLetter == '':
if target < letters[left]:
maxLetter = letters[left]
else:
maxLetter = letters[left+1]
return maxLetter算法的时间复杂度仍旧为O(log n)。不过,虽然自己改进后的代码能够跑通目前LeetCode上的用例,但不清楚如果添加结构更复杂,数量更多的测试用例时,是否还能轻松通过。
总结
在这一章节的练习下,我重新回顾了二分法的使用并提高了运用它的熟练程度。正常状况下,想使用二分法必须遵从数组是有序的前提,但经过了这个专项训练,我发现有些时候也不一定非得数组完全有序才能使用二分法。我们需要多加观察题目给出的条件和输入数据本身存在的规律,来灵活运用二分法的特性,高效排除掉一些无关元素。
另外,在二分法进行了改进后,比较两指针大小以及target与中间值的大小时,是否取上等号也得视情况仔细斟酌,而不是无脑照搬原生二分法的写法。很多时候,正是因为等号的问题,导致了解答始终无法通过测试。因此,想要更快更加灵活地运用改造后的二分法,达到炉火纯青的境界,还需要多加练习,积累经验才行。
如果笔记存在一些问题,发现后我会尽快纠正。
*注:本文的所有题目均来源于leetcode














 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









