





本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:沈唁

Python爬虫中Xpath的用法,相信每一个写爬虫、或者是做网页分析的人,都会因为在定位、获取XPath路径上花费大量的时间,在没有这些辅助工具的日子里,我们只能通过搜索HTML源代码,定位一些id,class属性去找到对应的位置,非常的麻烦,今天推荐一款插件Chrome中的一种爬虫网页解析工具:XPath Helper,使用了一下感觉很方便,所以希望能够帮助更多的Python爬虫爱好者和开发者
插件简介
XPath Helper插件是一款免费的Chrome爬虫网页解析工具,可以帮助用户解决在获取XPath路径时无法正常定位等问题
安装了XPath Helper后就能轻松获取HTML元素的XPath,该插件主要能帮助我们在各类网站上查看的页面元素来提取查询其代码,同时我们还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中,也很方便的帮助我们判断我们的XPath语句是否书写正确
安装插件
1、如果你能够打开Chrome的网上应用店,直接搜索XPath Helper就能找到这个插件,直接点击“添加至chrome”即可
2、你没工具去打开Chrome的网上应用店的话,我将这个插件上传到了百度云网盘,你可以直接下载,将其直接拖拽到浏览器的“扩展程序”页面(设置-扩展程序)即 chrome://extensions 页面
3、或者你直接在Github上进行下载,使用开发者模式进行打包,然后进行安装即可
使用插件
1、打开某个网站,我这以本站首页为例,获取腾讯云的这篇文章的标题,打开审查元素,找到拷贝目标元素的XPath获取目标元素的XPath
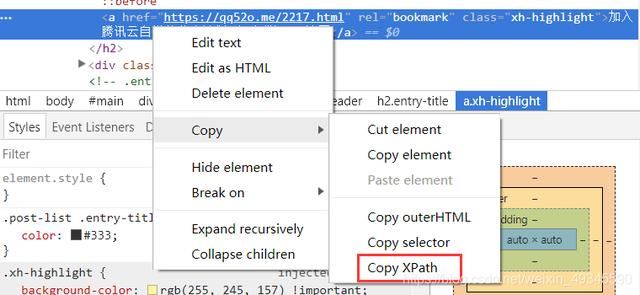
2、直接使用快捷键Ctrl+Shift+X,唤出来XPath辅助控制台,将这段XPath粘贴到左边的Query文本框,右边Result文本框就会输入获取的值,括号内是对应匹配到的次数,同时对应的值会显示米黄色
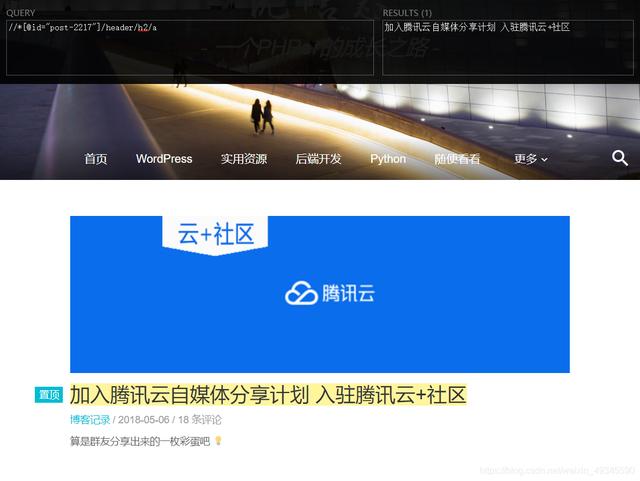
3、至此,你就可以在Query框中输入相应的XPath进行调试,提取到的结果都会被显示在旁边的Result文本框中
注意事项
虽然XPath Helper插件使用非常方便,但它也不是万能的,有两个问题:
1、XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护,我们可以使用//来处理
2、当提取多条的列表数据时,XPath Helper是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,我们还是需要修改一些类似于*的标记来匹配任何元素节点等















 2661
2661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









