





最近在做科研的时候需要对一组高维向量降维可视化。比较下,tensorboard的可视化效果最好,且提供了很方便的降维算法api,交互界面也相对友好。网上的教程tensorboard版本相对较早,并且用的数据是tensorflow官方提供的数据,导致在实现过程中踩了不少坑,最后查阅了github官方源码和一些资料后才成功实现。
文件目录
|--demo
|-log_visual #tensorboard work_dir
|-...
|-utils.py #可视化脚本文件环境
tensorflow==2.2.0
tensorboard==2.2.2数据准备
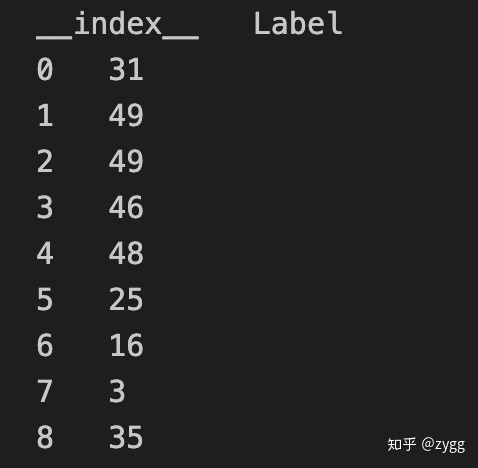
- 需要可视化的高维向量集合:list [N,dim]
- 每个向量的标签(optional):list [N,1]
- 每个向量对应的式例图片(optional):N*images代码
import os
import cv2
import sys
import csv
from random import sample
import numpy as np
import tensorflow as tf
# tensorboard之前的版本为from tensorflow.contrib.tensorboard.plugins import projector
from tensorboard.plugins import projector
# 导入加载数据模块
sys.path.append('/home/**/research/project/')
from datasets import AWA2Dataset
SPRITE_FILE = "spriteimage.jpg" #向量对应的拼接图片
META_FIEL = "metadata.tsv" #向量对应的标签文件
LOG_DIR = "log_visual" #tensorboard work_dir 这里尽量不要写绝对路径
SAMPLE_NUM = 900 #采样向量的个数
IMAGE_SIZE = 32 #图片size
SPIRATE_IMAGE_SIZE = 30 #拼接图片size生成标签文件和标签图片
def create_sprite_image_and_label():
"""
param: None
return: 需要可视化的高维向量集合, list, [SAMPLE_NUM, dim]
"""
# 加载数据
dataset = AWA2Dataset()
data = dataset.load_data(key='sigmoid')
_class = list(dataset.classes)
key_arr = list(data.keys())
# 采样一部分向量可视化
visual_arr = sample(key_arr, SAMPLE_NUM)
image_arr = []
for i in range(SAMPLE_NUM):
image_arr.append(data[visual_arr[i]])
# 生成标签文件 metadata.tsv
with open(os.path.join(LOG_DIR, META_FIEL), 'w') as f:
f.write('__index__' +'t' +'Label' +'n')
for i in range(SAMPLE_NUM):
name = visual_arr[i].split('_')[0]
label = _class.index(name)
# f.write(str(label) +'n')
f.write(str(i) +'t' +str(label) +'n')
# 生成拼接图片文件 spriteimage.jpg
spriteimage = np.ones((IMAGE_SIZE * SPIRATE_IMAGE_SIZE, IMAGE_SIZE * SPIRATE_IMAGE_SIZE,3))
for i in range(SPIRATE_IMAGE_SIZE):
for j in range(SPIRATE_IMAGE_SIZE):
this_filter = i * SPIRATE_IMAGE_SIZE + j
this_img = cv2.imread('/home/**/research/visualize/imgs/'+visual_arr[this_filter].split('_')[0]+'.jpg')
spriteimage[i * IMAGE_SIZE:(i + 1) * IMAGE_SIZE, j * IMAGE_SIZE:(j + 1) * IMAGE_SIZE] = this_img
cv2.imwrite(os.path.join(LOG_DIR, SPRITE_FILE),spriteimage)
return image_arr
生成配置文件,网上教程是基于较早版本的tensorboard,新版本相对更简化
def visualisation(vectors):
"""
param: 需要可视化的高维向量集合, list, [SAMPLE_NUM, dim]
return: None
"""
# PROJECTOR可视化的都是TensorFlow中的变量类型。
y = tf.Variable(vectors)
checkpoint = tf.train.Checkpoint(embedding=y)
checkpoint.save(os.path.join(LOG_DIR, "embedding.ckpt"))
# 通过project.ProjectorConfig类来帮助生成日志文件
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果
embedding = config.embeddings.add()
# 指定这个embedding结果所对应的Tensorflow变量名称
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
# 指定embedding结果所对应的数据标签文件,改设置可选, 如果没有提供,可视化结果
# 每个点颜色都是一样的
embedding.metadata_path = META_FIEL
# 指定sprite 图像。这个也是可选的,如果没有提供sprite 图像,那么可视化的结果
# 每一个点就是一个小困点,而不是具体的图片。
embedding.sprite.image_path = SPRITE_FILE
# 这将用于从sprite图像中截取正确的原始图片。
embedding.sprite.single_image_dim.extend([IMAGE_SIZE, IMAGE_SIZE])
# 将PROJECTOR所需要的内容写入日志文件。
projector.visualize_embeddings(LOG_DIR, config)
if __name__=="__main__":
vectors = create_sprite_image_and_label()
visualisation(vectors)最后的文件目录:
|--demo
|-log_visual #tensorboard work_dir
|-checkpoint
|-embedding.ckpt-1.data-00000-of-00001
|-embedding.ckpt-1.index
|-metadata.tsv
|-projector_config.pbtxt
|-spriteimage.jpg
|-utils.py #可视化脚本文件注意metadata.tsv和spriteimage.jpg的文件位置,这样能确保不会出现奇怪的错误。
在demo目录下
$ tensorboad --logdir=./log_visual
浏览器访问:localhost:端口 例如:localhost:6006
如果你的代码部署在远程服务器上,需要在本地浏览器可视化,可以做个简单的端口映射
$ ssh -L 16006:127.0.0.1:6006 user@ip
6006为服务器端口 16006为本地访问端口
在远程shell下运行命令
本地浏览器 localhost:16006 访问可视化结果
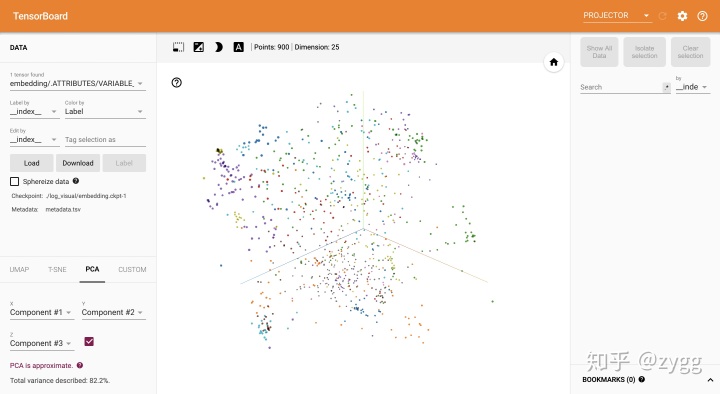
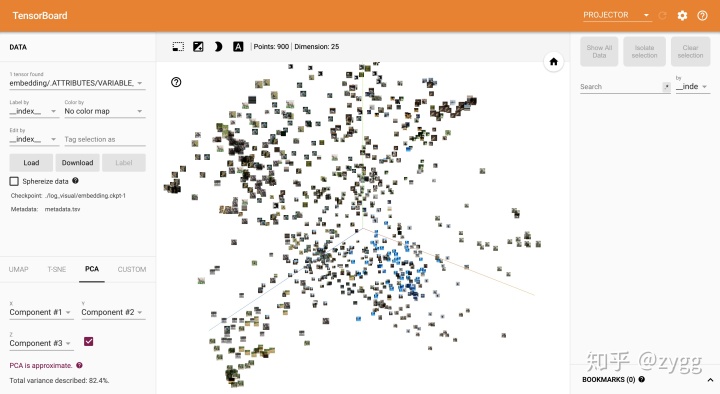
个人觉得圆点+颜色最直观,左边还可以选择不同降维算法来进行可视化。
p.s. 欢迎批评指正,顺便祝各位大佬科研顺利!















 6060
6060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









