






我 18 年在 PyCon 做过一次类似的分享 ,目的是如何写出优雅的代码。希望能部分回答这个问题,也希望与大家多多讨论。《聊聊编程原则》zhuanlan.zhihu.com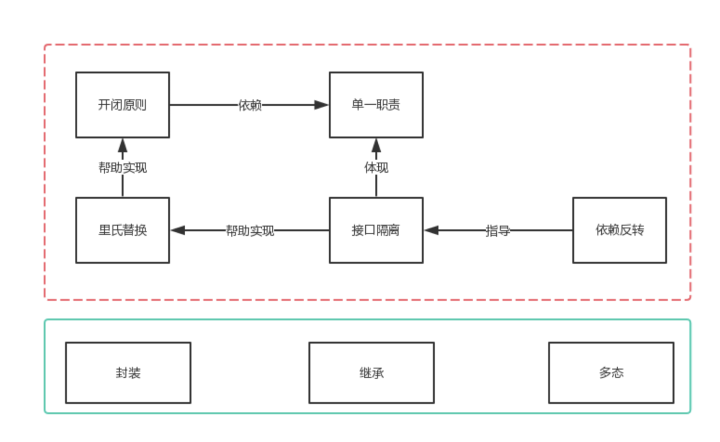
要成为合格的架构师最基本的要求是能写优雅的代码,所以必须要知道什么是优雅代码。也就是在代码方面形成自己的无关编程语言的方法论,而不是模棱两可。
这篇文章来介绍什么我对于优雅代码的理解。这也是我在知乎内部和 PyCon China 分享的内容,尽量跟编程语言不相关。这个分享大致准备了两个月时间,希望对能对大家有所帮助。
优雅代码
我们如何来形容优雅的代码?平时貌似一直用这些形容词可读性高
逻辑清晰
高内聚,低耦合
已测试
等等
但是这些词没有任何指导意义,我准备从最基本的概念入手。
OOP 三大特征封装
继承
多态
封装:Encapsulation refers to the bundling of data with the methods that operate on that data. Encapsulation is used to hide the values or state of a structured data object inside a class, preventing unauthorized parties' direct access to them. ——From Wikipedia
先看一个例子,这是我们经常会看到一段代码
class Person(object):
def __init__(self, birth_day, sex, children, lover):
self.birth_day = birth_day
self.sex = sex
self.children = children
self.lover = lover
self.age = self.compute_age()
def compute_age(self):
today = date.today()
if (today.month, today.day) > (self.birth_day.month, self.birth_day.day):
return today.year - self.birth_day.year
else:
return today.year - self.birth_day.year - 1
person = Person(date(1990, 1, 1), u"male", [], u"新垣结衣")
# 属性修改
person.birth_day = date(2020, 1, 1)
person.children = [1]
person.sex = u"female"
person.lover = u"刘亦菲"
person.age = 18
这段代码存在比较严重的问题,因为这个类具有业务逻辑。一个人的生日能随便乱改?生日确定了,年龄不能改?性别貌似也不行?除了女朋友和孩子都不行,而且孩子只允许增加。所以要对这些属性做保护。所以改成了下面这样
class Person(object):
def __init__(self, birth_day, sex, children, lover):
self._birth_day = birth_day
self._sex = sex
self.children = children
self.lover = lover
@property
def birth_day(self):
return self._birth_day
@property
def age(self):
today = date.today()
if (today.month, today.day) > (self._birth_day.month, self._birth_day.day):
return today.year - self._birth_day.year
else:
return today.year - self._birth_day.year - 1
@property
def sex(self):
return self._sex
这样可以吗,仔细分析下 children 还是还存在问题,因为每次我想设置新的 children 的时候,都需要把所有的孩子拿出来,要不然会可能会出现孩子被无意间减少的情况。当然有人会说我们直接 person.children.append 就好了,但是这样会把我们内部使用 list 的实现细节暴露出去,如果我们以后想换成其他数据结构 set 是不是就很麻烦,要改很多调用方。所以又改成了这样。
class Person(object):
def __init__(self, birth_day, sex, children, lover):
self._birth_day = birth_day
self._sex = sex
self._children = children
self.lover = lover
# 中间部分,birth_day,age,property
@property
def children(self):
return self._children
def add_child(self, child):
self._children.append(child)
是不是这样会好些。但是如果按照更高的要求,lover 这个名字暴露出去也不太好,因为如果有一天我想把名字换成 bride 怎么办,是不是多外部使用 lover 的地方都要改动。
这样的程序看起有人会说啰嗦,在 《Fluent Python》里这么提到“What’s the simplest thing that could possibly work?” The idea is to focus on the goal. Implementing setters and getters up front is a distraction from the goal. In Python, we can simply use public attributes knowing we can change them to properties later, if the need arises. ——From 《Fluent Python》
但是这个观点我是完全不同意的,因为一旦的信息泄露出去,就很难在收回了。已经被大量的模块使用的基础模块,不是想改就改的。
封装总结:尽可能隐藏一个模块的实现细节(属性名称,属性是否可变,算法,数据结构,数据类型)
访问控制只是为了防止程序员的无意误用,不打算,也无法防止程序员的故意破坏
继承:Inheritance is the mechanism of basing an object or class upon another object (prototypical inheritance) or class (class-based inheritance), retaining similar implementation. ——From Wikipedia
各种书里都说继承是 is-a 或者 is-a-kind-of 的关系,例如 duck 是 bird,duck 可以继承 bird;ostrich 是 bird,ostrich 可以继承 bird;但是我不同意这个观点。先看个例子
class Bird(object):
name = "Bird"
def fly(self):
pass
def run(self):
print(self.name + " run")
class Ostrich(Bird):
name = "Ostrich"
def laid_eggs(self):
pass
这个程序的问题问题还是比较严重的,因为 Ostrich 为了复用 run 方法继承了 Bird,但是 Ostrich 不会飞。如果调用了 Ostrich().fly() 是不符合逻辑的,可能会引起不可预知的问题。同理我设计一个 stack 的类,stack 只有 push 和 pop 两个方法
class Stack(list):
def push(self, item):
self.append(item)
# 直接使用 list 的 pop 方法
# def pop(self, index: int = ...):
# pass
这样实现造成 stack 具有 list 所有的方法,假设 stack 有了一百万个元素,直接调用了 remove 方法,可能就出现出严重的性能问题了。造成了信息泄露,封装不够严谨。使用组合方式用 list 来实现 stack 就会好多。「优先选用组合,后考虑继承」也是《设计模式》这本书的核心思想。
class Stack(object):
def __init__(self):
self._items = []
def push(self, item):
self._items.append(item)
def pop(self):
self._items.pop()
当然继承仅仅考虑封装的严谨性并不够。到这里就可以看出继承并不是 is-a 或者 is-a-kind-of 的关系,而是 behaves-like-a, is-substitutable-for 的关系。关于为什么是 behaves-like-a, is-substitutable-for 的关系在后文的 「liskov substitution principle」 还会深入的提到。
继承总结:继承使用不当会破坏封装,造成信息泄露
先考虑组合,在考虑继承
继承是 behaves-like-a, is-substitutable-for 的关系,不是 is-a 或 is-a-kind-of 的关系
多态:Polymorphism is the provision of a single interface to entities of different types or the use of a single symbol to represent multiple different types ——From Wikipedia
class Development(object):
__metaclass__ = abc.ABCMeta
def run(self):
self.rfc_review()
self.write_code()
self._test()
self.release()
@abc.abstractmethod
def rfc_review(self):
pass
@abc.abstractmethod
def write_code(self):
pass
@staticmethod
def _test():
print("test")
@abc.abstractmethod
def release(self):
pass
class ZhihuDevelopment(Development):
def rfc_review(self):
print("MySQL,HBase")
def write_code(self):
print("Java")
def release(self):
print("build APP, upload")
LiveDevelopment().run()
Development 类的 run 方法被不同的子类在不同的场景使用。不同子类实现的 rfc_review,write_code,release 方法,在相同的场景 run 方法里使用。
多态总结:相同的实现代码适用不同的场合
不同的实现代码适用相同的场合
SOLID Principle:Single responsibility principle
Open–closed principle
Liskov substitution principle
Interface segregation principle
Dependency inversion principle
一 . Single responsibility principle:A module should have one, and only one, reason to change.
A module should be responsible to one, and only one, actor.
设计一个获取知乎问题信息的类,主要包含两个逻辑 1 .获取数据 2. format 成指定格式,最开始代码可能是这样的
class Question(object):
def __init__(self, question_id, data_formatting):
self._question_id = question_id
self._data_formatting = data_formatting
def get(self):
# connect_MySQL
# get_data_from_MySQL
# connect_Redis
# get_data_from_Redis
return self._format_data()
def _format_data(self):
# do some thing
pass
这样的设计 get 函数负责了两个逻辑,一个是获取数据的具体逻辑,一个是调用 format 函数。一个函数模块负责了两个功能,优化成如下版本会好一些。分成三个模块 get(主逻辑)_get_data (获取数据)_format_data(格式化数据)
class Question(object):
def __init__(self, question_id, data_formatting):
self._question_id = question_id
self._data_formatting = data_formatting
def get(self):
self._get_data()
return self._format_data()
def _get_data(self):
# connect_MySQL
# get_data_from_MySQL
# connect_Redis
# get_data_from_Redis
pass
def _format_data(self):
# do something
pass
如果 format 的逻辑继续复杂,就可以继续抽象成(如果 format 逻辑不复杂,不用继续抽象)
class Question(object):
def __init__(self, question_id, data_formatting):
self._question_id = question_id
self._data_formatter = DataFormatter(data_formatting)
def get(self):
self._get_data()
return self._data_formatter.format()
def _get_data(self):
# connect_MySQL
# get_data_from_MySQL
# connect_Redis
# get_data_from_Redis
pass
class DataFormatter(object):
def __init__(self, data_formatting):
self._data_formatting = data_formatting
def format(self):
# step1
# step2
pass
Question(question_id=1, data_formatting="PDF").get()
这样每个模块的职责都比较单一了。逻辑清晰,易于测试。
如何理解 responsibility 呢,我个人的理解是这样的职责是从外部角度定义的
职责可能不是一件事,而是很多有相同目标的事情
在架构上,后端的微服务,客户端/前端的组件化。包括后文提到的 DIP 都是 Single responsibility 的应用。
Single responsibility principle 总结:每个软件模块都有且只有一个需要被改变的理由
二. Dependency inversion principle:High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions. ——From Wikipedia
设想一下如果 DataFormatter 需要添加新的初始化参数 color,我们会怎么做?就会不得不修改 Question ,让 Question 增加新的参数。这样每次我们修改 DataFormatter ,都需要牵连 Question ,Python 是动态语言不会涉及大量的重新编译,如果是 C++ ,Question,DataFormatter 代码量又很大的话,每次都要重新编译,花费时间也会很多。现在的依赖关系是这样的
根据单一职责 Question 只关心本身的逻辑,Question 只想拿到一个可用 DataFormatter 实例,不应当关心 DataFormatter 的初始化。改成如下版本应该会好些
class Question(object):
def __init__(self, question_id, data_formatter):
self._question_id = question_id
self._data_formatter = data_formatter
def get(self):
self._get_data()
return self._data_formatter.format()
def _get_data(self):
# connect_MySQL
# get_data_from_MySQL
# connect_Redis
# get_data_from_Redis
pass
class DataFormatter(object):
def __init__(self, data_formatting):
self._data_formatting = data_formatting
def format(self):
pass
data_formatter = DataFormatter(data_formatting="PDF")
Question(question_id=1, data_formatter=data_formatter).get()
现在的依赖关系变成了这样,上层仅仅知道我需要一个可用的 DataFormatter,下层你要给到我。
另外一个更好的例子来源于 知乎用户:Spring IoC有什么好处呢?,大家一定要看看。演讲时我讲了。文章由于篇幅原因我就赘述了。
一般的依赖关系https://www.wikiwand.com/en/Dependency_inversion_principle
应用 DIP 原则之后,中间的抽象层(Java IOC)对应的我们的 DataFormatter 的初始化过程。
Dependency inversion principle 总结:高层策略性代码不要依赖实现底层细节
底层细节的代码应该依赖高层策略性代码
三. Liskov substitution principle:What is wanted here is something like the following substitution property: If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T ——From Wikipedia
换成容易理解的Subtypes must be substitutable for their base types. 任何使用父类的地方,都可以替换成子类不出现故障或逻辑问题
随着 format 的逻辑越来越复杂,format 逻辑也需要抽象成不同的类了。但是 JsonFormatter 不支持 txt 类型。
class DataFormatter(object):
def __init__(self, data_formatting):
self._data_formatting = data_formatting
def format(self):
# do something
pass
class ThriftFormatter(DataFormatter):
def format(self):
# do something
pass
class JsonFormatter(DataFormatter):
def format(self):
if self._data_formatting != "txt":
# do something
pass
else:
raise Exception("")
data_formatter = JsonFormatter(data_formatting="PDF")
Question(question_id=1, data_formatter=data_formatter).get()
class Question(object):
def __init__(self, question_id, data_formatter):
self._question_id = question_id
self._data_formatter = data_formatter
def get(self):
self._get_data()
if isinstance(self._data_formatter, JsonFormatter) and self._data_formatter._data_formatting == "txt":
# do some thing
return
else:
return self._data_formatter.format()
# try:
# return self._data_formatter.format()
# except Exception:
# # do something
# return
def _get_data(self):
# connect_MySQL
# get_data_from_MySQL
# connect_Redis
# get_data_from_Redis
pass
上边的代码貌似存在一些问题,因为只要多一种不支持 txt 的类型,我们的 Question 模块就要发生改变,维护困难。原因就在于各个 DataFormatter 不可完全替换,行为不一致。这也是上文说为什么「继承是 behaves-like-a, is-substitutable-for 的关系,不是 is-a 或 is-a-kind-of 的关系」的原因。至于这个问题如何解决可以参考 SOLID Class Design: The Liskov Substitution Principle 。
在架构上选用对外行为一致,可替换的组件也是我们的追求。
Liskov substitution principle 总结:使用可替换的组件来构建软件系统
同一层次的组件遵守同一个约定,以方便替换
四. Interface segregation principle:No client should be forced to depend on modules it does not use.
这个原则很简单了,不要依赖不(直接)使用的组件,其实 DIP 原则会帮助我们实现 ISP,因为 DIP 中间的抽象(策略)层打破了依赖从上到下的依赖链条。使上层不在依赖下层的细节。这个原则的原则好处很明显,依赖减少使组件更容易被替换,符合 SRP。
Interface segregation principle 总结:在设计中避免不必要的依赖
软件系统不应该依赖其不直接使用的组件
五. Open–closed principle:A software artifact should be open for extension but closed for modification.
如果上文提到的几个原则都做到了,大概率也就符合了 Open–closed principle,完成了一个可扩展代码结构或者软件架构的设计。
Open–closed principle 总结:通过新增代码修改系统行为,而非修改原来的代码
概念之间的关系:参考 https://insights.thoughtworks.cn/do-you-really-know-solid/
总结:封装,尽可能掩盖模块内部实现细节,方便进行迭代和替换
继承,遵循 LSP,非 is-a 或 is-a-kind-of 的关系,而是 hehaves-like-a, is-substitutable-for 的关系
SRP,一个模块只负责一类事情,有且只有一个被修改的理由
DIP,高层策略性代码不要依赖实现底层细节,底层细节的代码应该依赖高层策略性代码
LSP,使用可替换的组件来构建软件系统,同一层次的组件遵守同一个行为约定,以方便替换SRP,不要依赖其不直接使用的组件
OCP,通过新增代码修改系统行为,而非修改原来的代码
最重要的:模块一定要隐藏实现细节,只暴露必要接口
优先考虑组合,后考虑在行为一致的基础上使用继承
高层策略性代码不要依赖实现底层细节,底层细节的代码应该依赖高层策略性代码
文章很长,恭喜你读到了这里,希望你能有所收获。有任何问题欢迎提出来讨论。
姚钢强
参考资料:















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









