






背景
众所周知,作为目前使用的最多的内存型数据库之一的Redis,使用单线程(这里的单线程是指Redis用来接收网络请求、处理请求、返回结果这一过程中使用了一个线程)就能够最高抗住五十万的qps,其性能是非常之高。
至于为啥Redis单线程就能有这么高的性能,网上有很多文章写了,本文就不多讲。
之前Redis社区也经常提及多线程特性,但是直到最近发布的Redis6-rc1版本才实现了多线程版本。
网上有同学对Redis多线程和单线程版本进行了性能测试,对比显示,Redis的多线程版本性能至少比单线程版本提高了50%。
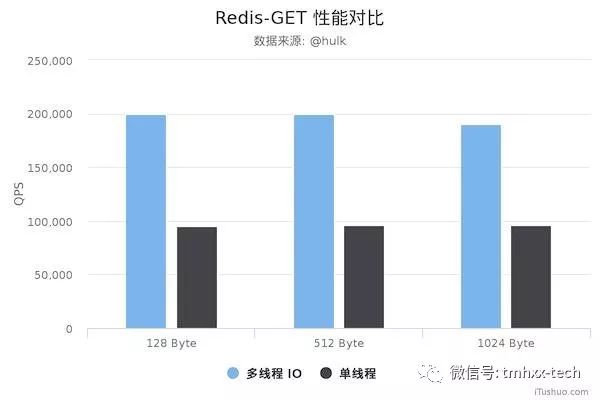
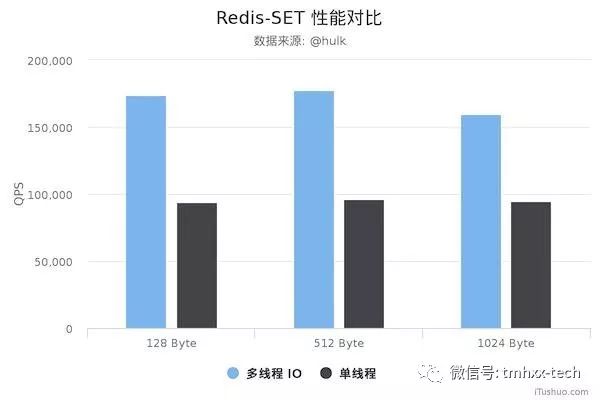
本文就来深度剖析下Redis6里面的多线程实现原理。
分析
Redis5单线程实现
在分析Redis6里面的多线程实现之前,先来简要看一下Redis6之前的单线程版本中命令的执行过程。
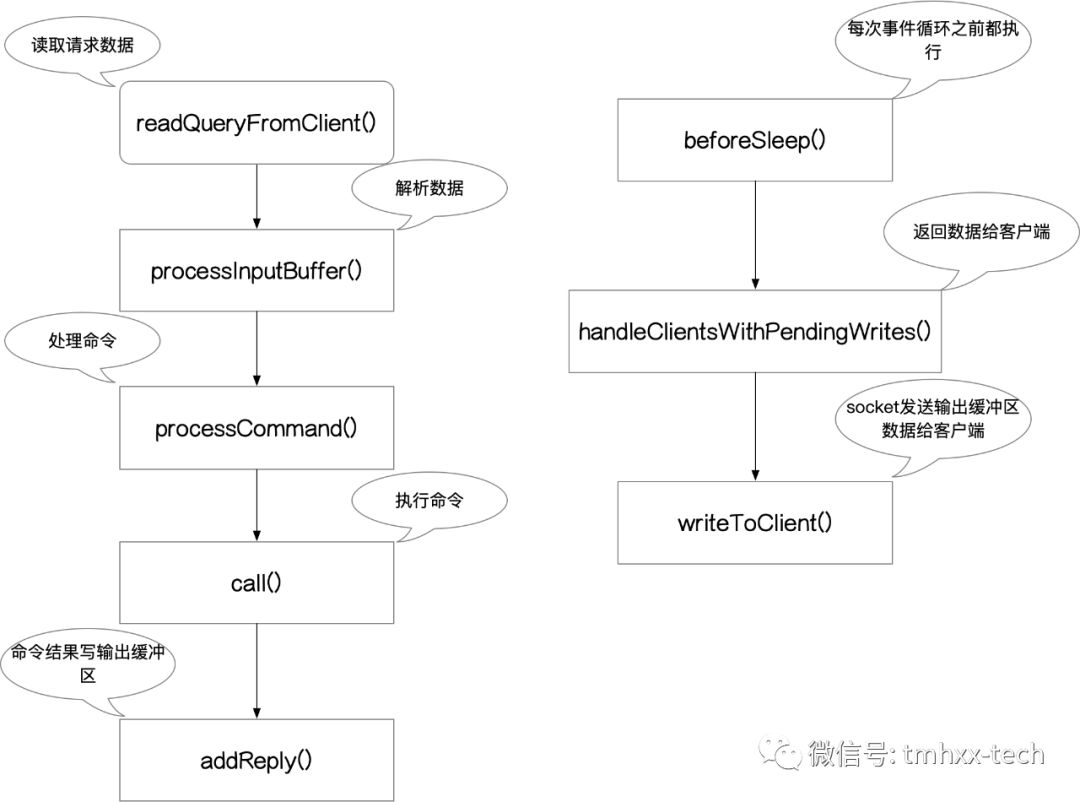
在客户端与Redis服务器建立连接之后,所有的请求都会执行到readQueryFromClient()方法中,readQueryFromClient()方法会从socket中读取数据放到输入缓冲区querybuf中,接着会调用processInputBuffer()(实际上readQueryFromClient()是调用的processInputBufferAndReplicate(),而在processInputBufferAndReplicate()中又调用了processInputBuffer())方法按照RESP协议来解析参数。解析完参数之后会调用processCommand()方法执行具体的命令。在processCommand()中根据命令名称找到对应的命令并调用命令的call()完成具体的操作,命令在执行完成之后都会调用addReply()方法返回执行结果。
但是这里需要注意的是addReply()方法只是把返回的数据写入到输出缓冲区client->buf或者client->reply中,并不执行实际的网络发送操作。
Redis在每次进入事件循环之前,都会先调用beforeSleep()方法,实际的网络发送数据操作是在beforeSleep()方法中完成的。
beforeSleep()中会调用handleClientsWithPendingWrites()返回数据给客户端:handleClientsWithPendingWrites()中会调用writeToClient()方法把输出缓冲区client->buf和client->reply中的数据通过socket发送给客户端。
流程图如下所示:
 redis.png
redis.png
Redis6为了支持多线程,又会做什么改变呢?
别急,且听我娓娓道来!
Redis6多线程实现
首先,在main()方法中会调用InitServerLast()方法,InitServerLast()方法中会调用initThreadedIO()方法,从方法名中就可以看出来,这个方法的主要作用是初始化IO线程。
initThreadedIO
void initThreadedIO(void) {
// 设置标志位,表示io线程还没有激活
io_threads_active = 0; /* We start with threads not active. */
/*如果设置的io线程数量为1,则不启动多余的io线程,只使用主线程*/
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn the I/O threads. */
for (int i = 0; i < server.io_threads_num; i++) {
pthread_t tid;
pthread_mutex_init(&io_threads_mutex[i],NULL);
io_threads_pending[i] = 0;
io_threads_list[i] = listCreate();
// 当前线程(主线程)会先锁定所有的互斥锁
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 生成新的io线程,每个io线程执行IOThreadMain()方法,方法参数是当前索引
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}
initThreadedIO()方法主要完成下面几件事:
初始化IO线程标志位
io_threads_active为0,即表示IO线程还未激活。1表示已激活。校验
io_threads_num。io_threads_num表示用户设置的要开启的io线程的数量。如果io_threads_num=0则表示用户不需要开启多余的IO线程,直接使用主线程进行IO。IO线程数最大不超过128。初始化指定数量的线程以及对应的互斥锁。
Redis把所有的IO线程保存在数组
io_threads中,每个线程都对应着一个互斥锁,这些互斥锁保存在io_threads_mutex数组中。每个IO线程都会对应着一个任务列表,任务列表中保存着对应线程需要处理的client对象。这些任务列表保存在
io_threads_list数组中。同时Redis会记录每个IO线程对应的队列中需要处理的client对象的个数,这些个数保存在
io_threads_pending数组中。Redis主线程在生成具体的线程之前会先初始化互斥锁并且获取所有的互斥锁,为什么会这么做呢?后面再分析。
生成IO线程的时候传入了
IOThreadMain函数指针,说明每个IO线程都是执行IOThreadMain()方法。IOThreadMain方法的参数是对应的线程在io_threads数组中的下标索引。
initThreadedIO()方法执行完成之后,io_threads_num个的IO线程已经启动了,且执行的是IOThreadMain()方法,那么我们继续来看下IOThreadMain()()方法。
IOThreadMain
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
// 首先获取当前线程在io_threads数组中的下标,在io_threads_pending和io_threads_list中的下标是一致的
long id = (unsigned long)myid;
while(1) {
/* Wait for start */
// 先自旋一会,如果自旋期间当前线程被分配了任务的话就可以不用抢夺互斥锁
// 可以提高性能
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
/* Give the main thread a chance to stop this thread. */
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
/* Process: note that the main thread will never touch our list
* before we drop the pending count to 0. */
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 从io_threads_list列表中获取任务
// 如果是写任务,则进行写操作
// 如果是读任务,则进行读操作
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}
IOThreadMain()在一个死循环中完成下面几件事:
判断当前线程有没有被分配新的任务。
那么怎么判断呢?是通过共享数组
io_threads_pending来实现。前面说了,
io_threads_pending数组保存的是每个线程被分配的任务client对象的个数。如果io_threads_pending>0,则表示有新的任务需要处理。那么什么时候会进行任务分配呢?谁来进行呢?这个后面会分析。这里先给出答案:由主线程来进行分配。
在判断
io_threads_pending[id](id是当前线程在数组中的索引)是否大于0的时候,IO线程会先自旋一会。这样做的一个好处就是如果IO线程在自旋期间主线程就给当前线程分配了任务的话,io线程就不会去抢夺互斥锁。节省了抢夺互斥锁的开销(这个开销还挺大的)。如果自旋之后还没有任务分配,IO线程则会调用
pthread_mutex_lock()方法来抢夺对应的互斥锁。之前提到过在
initThreadedIO()方法中主线程在生成具体的IO线程之前会先调用pthread_mutex_lock()把所有的互斥锁给锁上。所以IO线程此时会因为抢锁失败处于阻塞状态。这里有一点需要注意的是:主线程和IO线程通过共享变量数组
io_threads_pending来进行通信。主线程修改io_threads_pending,IO线程读取io_threads_pending,那么就有可能存在线程安全问题。那么Redis是怎么避免线程安全问题的呢?答案是通过
_Atomic限定符。io_threads_pending变量在声明的时候加上了_Atomic限定符:_Atomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM];_Atomic是C11标准中引入的原子操作:被_Atomic修饰的变量被认为是原子变量,对原子变量的操作是不可分割的(Atomicity),且操作结果对其他线程可见,执行的顺序也不能被重排。所以io_threads_pending是属于线程安全的变量。执行具体的读操作或者写操作。
在判断被分配到读写任务之后。IO线程就会进行具体的读写操作。
每个IO线程都会遍历自己的任务队列(在
io_threads_list[id]中),对队列中的每一个client对象执行具体的读写操作。变量
io_threads_op标识当前线程需要进行的操作:如果是IO_THREADS_OP_WRITE,表示写操作,则所有的IO线程都会调用writeToClient()方法把各个client对象的输出缓冲区的数据通过socket返回给客户端,IO_THREADS_OP_READ表示读操作。所有的IO线程都会调用readQueryFromClient()方法读取客户端的请求。这里有一点需要注意的是:所有的IO线程,只会同时进行读操作或者进行写操作。
handleClientsWithPendingWritesUsingThreads
Redis在每次事件循环开始前都会先调用beforeSleep()方法,在beforeSleep()方法中会调用handleClientsWithPendingWritesUsingThreads()方法:
int handleClientsWithPendingWritesUsingThreads(void) {
// 1. 判断是否还有client对象需要写数据给客户端
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
/* If we have just a few clients to serve, don't use I/O threads, but the
* boring synchronous code. */
// 2. 判断是否的确需要使用多IO线程进行数据读写
if (stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
/* Start threads if needed. */
// 3. 如果IO线程没有激活的话则开启IO线程
if (!io_threads_active) startThreadedIO();
if (tio_debug) printf("%d TOTAL WRITE pending clients\n", processed);
/* Distribute the clients across N different lists. */
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
// 4.按照RoundRobin算法把需要返回数据的client对象分配给IO线程
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the
* start condition atomic var. */
// 5. 设置标志位为写操作,统计各个io线程需要处理的client的个数
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 0; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
/* Wait for all threads to end their work. */
// 6. 空循环等待所有的IO线程完成IO读写
while(1) {
unsigned long pending = 0;
for (int j = 0; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O WRITE All threads finshed\n");
/* Run the list of clients again to install the write handler where
* needed. */
// 7. 如果还有数据没有写完的话则继续处理
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
/* Install the write handler if there are pending writes in some
* of the clients. */
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
// 8. 清空需要写数据的client对象列表
listEmpty(server.clients_pending_write);
return processed;
}
handleClientsWithPendingWritesUsingThreads()主要完成下面几个操作:
判断当前需要返回数据给客户端的client对象(Redis把需要返回数据的client对象保存在
server.clients_pending_write列表中)的个数。如果没有需要处理的client对象则直接返回。判断是否有必要使用多IO线程进行数据处理。
Redis会调用
stopThreadedIOIfNeeded()方法来判断是否的确需要时使用多IO线程,判断的依据是:当前需要处理的Client对象的数量超过了两倍的IO线程数量。如果没有的话则不会使用多IO线程,即使IO线程已经激活了也会先关闭(并非把线程给关了,只是把对应的互斥锁给锁上了,以及设置激活标志位io_threads_active=0)int stopThreadedIOIfNeeded(void) {
int pending = listLength(server.clients_pending_write);
/* Return ASAP if IO threads are disabled (single threaded mode). */
if (server.io_threads_num == 1) return 1;
// 只要当前需要处理的client对象的数量超过两倍的IO线程的数量的情况下才会使用多线程
if (pending < (server.io_threads_num*2)) {
if (io_threads_active) stopThreadedIO();
return 1;
} else {
return 0;
}
}如果判断出不需要使用多IO线程,则依然是由主线程调用
handleClientsWithPendingWrites()方法完成数据的返回操作。如果需要使用多IO线程且IO线程还没激活的情况下则调用
startThreadedIO()激活IO线程。void startThreadedIO(void) {
if (tio_debug) { printf("S"); fflush(stdout); }
if (tio_debug) printf("--- STARTING THREADED IO ---\n");
serverAssert(io_threads_active == 0);
for (int j = 0; j < server.io_threads_num; j++)
// 把所有的互斥锁给释放掉
pthread_mutex_unlock(&io_threads_mutex[j]);
// 设置激活标志位为1
io_threads_active = 1;
}startThreadedIO()方法的处理逻辑很简单:主线程把所有上锁的互斥锁给释放掉,然后设置激活标志位为1. 在主线程释放锁之后,被阻塞的IO线程会抢到锁从而继续判断有没有被分配任务。主线程按照Round Robin算法把需要返回数据给客户端的client分配到各个队列中,也就是
io_threads_list数组中。设置
io_threads_op为写操作,同时统计各个IO线程需要处理的client对象的个数,并写入对应的io_threads_pending数组中。这里需要提一句,在第三步中主线程调用
startThreadedIO()方法释放了IO线程的互斥锁之后,IO线程就会从pthread_mutex_lock()方法中返回,接着继续会判断对应的队列中的client数量是否为0,此时对应的任务可能还是0,如果为0,接着又会继续自旋,抢锁、释放锁等。所以我觉得
startThreadedIO()方法可以在计算完各个IO线程的任务数量之后再调用,这个时候IO线程会从阻塞中返回,此时任务数肯定不为0,就可以避免空循环了。主线程空循环等待所有的IO线程执行完成。
从这里可以看到,当IO线程在执行具体的读写操作的时候,主线程是属于空循环等待状态的。
如果还有数据没有写完的话则由主线程继续处理。
主线程清空
clients_pending_write。
从这整个过程可以看下来,当主线程执行的时候,IO线程基本上处于阻塞或者自旋空循环的状态,而IO线程执行读写操作的时候,主线程处于自旋空循环状态。两个之间通过_Atomic类型的变量来通信。
所以从根本上保证了线程安全问题。
有写数据就有读数据,继续来看下多线程读数据。
handleClientsWithPendingReadsUsingThreads
Redis在每次事件循环之后都会调用afterSleep()方法,在afterSleep()方法中会调用handleClientsWithPendingReadsUsingThreads()方法。
int handleClientsWithPendingReadsUsingThreads(void) {
// 判断是否使用多线程进行读
if (!io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
//... 其他省略代码
}
handleClientsWithPendingReadsUsingThreads()首先判断需要使用多IO线程读取数据之后,紧接着会判断当前多少个client需要读取数据。需要读取数据的client对象保存在server.clients_pending_read中,那么数据是哪里写到server.clients_pending_read中去的呢?
答:在readQueryFromClient()中。
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
if (postponeClientRead(c)) return;
//... 省略代码
/* There is more data in the client input buffer, continue parsing it
* in case to check if there is a full command to execute. */
processInputBufferAndReplicate(c);
}
前文提到了,readQueryFromClient()会读取客户端发送的请求,readQueryFromClient()会调用postponeClientRead()方法来判断是否需要把读数据请求放到IO线程中去执行。
postponeClientRead()实现如下:
int postponeClientRead(client *c) {
if (io_threads_active &&
server.io_threads_do_reads &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
// 给client对象的标志位增加CLIENT_PENDING_READ,这很重要
c->flags |= CLIENT_PENDING_READ;
// 把client对象添加到server.clients_pending_read列表中
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
如果IO线程已激活,允许使用多IO线程来读取数据,并且当前client的标志位不包含CLIENT_MASTER、CLIENT_SLAVE以及CLIENT_PENDING_READ,则先给当前client对象增加CLIENT_PENDING_READ标志位,然后把当前client对象添加到server.clients_pending_read列表末尾并返回1。
postponeClientRead()返回1之后,readQueryFromClient()方法随即返回,结束执行。
现在重新回到handleClientsWithPendingReadsUsingThreads()方法中:
int handleClientsWithPendingReadsUsingThreads(void) {
if (!io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
/* Distribute the clients across N different lists. */
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
// 按照RoundRobin算法分配读任务
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the
* start condition atomic var. */
// 2. 设置读操作标志位并统计各个IO线程任务数
io_threads_op = IO_THREADS_OP_READ;
for (int j = 0; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
/* Wait for all threads to end their work. */
// 3. 等待所有的线程处理完了所有的client的读数据操作
while(1) {
unsigned long pending = 0;// pending表示所有的线程加起来需要处理的client的数量
for (int j = 0; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
/* Run the list of clients again to process the new buffers. */
listRewind(server.clients_pending_read,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~ CLIENT_PENDING_COMMAND;
// 4. 执行命令
processCommandAndResetClient(c);
}
// 5. 如果还有数据需要读取的话读取数据
processInputBufferAndReplicate(c);
}
listEmpty(server.clients_pending_read);
return processed;
}
handleClientsWithPendingReadsUsingThreads()方法主要完成下面几个任务:
主线程按照RoundRobin算法给IO线程分配任务。
主线程设置读操作标志位并统计各个IO线程任务数。
主线程空循环等待所有的IO线程处理完了所有的client的读数据操作。
此时
io_threads_op = IO_THREADS_OP_READ,IO线程会执行readQueryFromClient()方法进行读数据操作。看到这里,可能会有小伙伴有疑问,前文提到过,当有客户端发送请求的时候最终会执行
readQueryFromClient()方法,在readQueryFromClient()方法中会把client对象添加到server.clients_pending_read列表中。现在IO线程再次调用readQueryFromClient()方法,会不会又把当前client添加到server.clients_pending_read列表中然后形成死循环呢?答案是不会的。
重新来看一下
postponeClientRead()方法:int postponeClientRead(client *c) {
if (io_threads_active &&
server.io_threads_do_reads &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
// 给client对象的标志位增加CLIENT_PENDING_READ,这很重要
c->flags |= CLIENT_PENDING_READ;
// 把client对象添加到server.clients_pending_read列表中
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}在判断要不要把client对象添加到
server.clients_pending_read列表的时候会先判断当前client有没有CLIENT_PENDING_READ标志位,如果有的话则不会添加到server.clients_pending_read列表。在主线程把client对象添加到
server.clients_pending_read列表之前会先设置对应的client的CLIENT_PENDING_READ标志位,所以在IO线程调用readQueryFromClient()方法的时候不会重复进行添加,会继续往下执行。前面分析过,在Redis5的版本中,主线程调用
readQueryFromClient()读取数据,readQueryFromClient()又会调用processInputBuffer()方法解析参数,解析完参数之后processInputBuffer()会立即调用processCommand()方法执行命令,并把执行结果写入到输出缓冲区中。也就是说,在Redis6之前的版本中只要调用了
readQueryFromClient()方法就会执行具体的命令。那么在Redis6里面会一样吗?如果一样的话,那IO线程就不只是读数据了,还会执行命令,这样的话多个IO线程同时执行命令的话,如果不加锁的话就很大概率会出现线程安全问题。但是如果加锁了,就违背了Redis初衷,而且还会影响性能。
答案是不一样。
Redis6中
readQueryFromClient()最终还是调用processInputBuffer()来解析请求参数。来继续看processInputBuffer():void processInputBuffer(client *c) {
/* Keep processing while there is something in the input buffer */
while(c->qb_pos < sdslen(c->querybuf)) {
//...其他省略解析参数的代码
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
resetClient(c);
} else {
/* If we are in the context of an I/O thread, we can't really
* execute the command here. All we can do is to flag the client
* as one that needs to process the command. */
// 判断当前client是否处于多线程环境,如果是的话,
// 只是给client新增CLIENT_PENDING_COMMAND标志位,不会继续执行命令
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
/* We are finally ready to execute the command. */
// 执行命令
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid exiting this
* loop and trimming the client buffer later. So we return
* ASAP in that case. */
return;
}
}
}
// 省略代码
}从代码里面可以看到,
processInputBuffer()方法在调用processCommandAndResetClient()执行命令之前会先判断当前的clien是否包含CLIENT_PENDING_READ标志位,如果是的话,则只是给当前的client添加CLIENT_PENDING_COMMAND标志位然后直接返回,并不会继续执行命令。总结下,在IO线程调用
readQueryFromClient()方法读取数据之后,会继续调用processInputBuffer()完成参数的解析,但是不会继续执行命令。所以,IO线程只做读数据的操作。
等所有IO线程读取数据之后由主线程执行具体的命令。
主线程遍历
server.clients_pending_read列表,对列表中的每一个client,会判断当前的client是否有CLIENT_PENDING_COMMAND标志位,如果有的话,则会继续调用processCommandAndResetClient(),而processCommandAndResetClient()会调用processCommand()执行具体的命令。在上一步中分析过,IO线程在调用
processInputBuffer()时如果发现client对象包含CLIENT_PENDING_READ标志位后会继续给当前client对象增加CLIENT_PENDING_COMMAND标志位。所以在这一步中,主线程会对
server.clients_pending_read列中的所有的client调用processCommandAndResetClient()方法执行具体的命令。如果还有数据没有读取完的话主线程则继续读取数据。
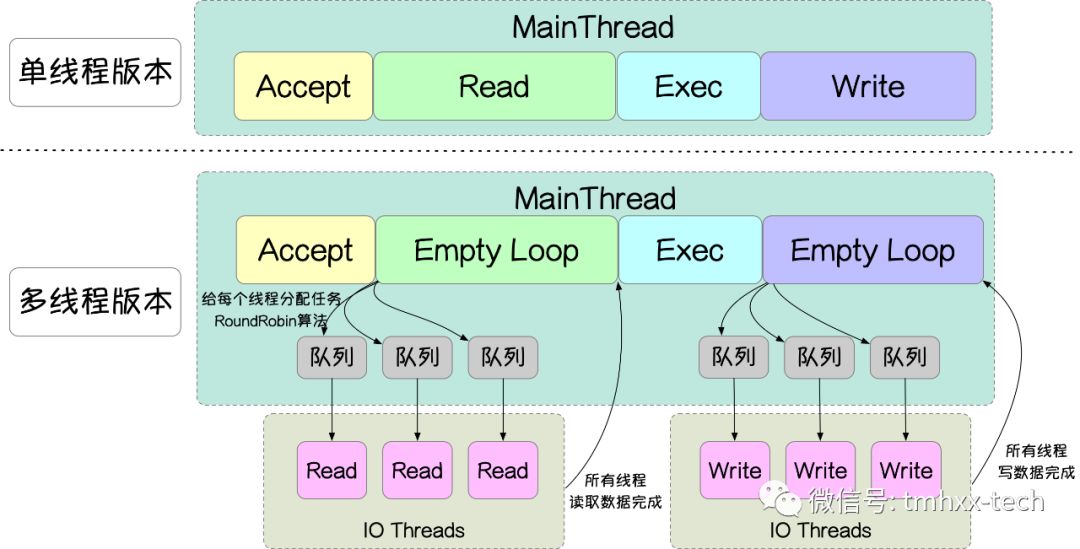
至此,Redis6里面的多线程实现已经分析完了,现在来总结下:
- Redis启动的时候会先启动IO线程(用户设置了线程数量,且允许多线程读),但是IO线程一开始处于阻塞状态。
- 每次有新客户端请求的时候主线程会执行到
readQueryFromClient(),在readQueryFromClient()中主线程会把client对象添加到server.clients_pending_read列表中。 - 在每次事件循环睡眠之后,Redis主线程会调用
handleClientsWithPendingReadsUsingThreads()方法,handleClientsWithPendingReadsUsingThreads()方法中主线程会把server.clients_pending_read列表中的client对象按照RoundRobin算法依次分配到io_threads_list队列数组中,并空循环等待所有的IO线程完成读数据操作。 - IO线程会从对应的
io_threads_list队列中获取client对象,依次调用readQueryFromClient()方法读取数据并按照RESP协议解析参数。 - 等所有IO线程执行完毕后,主线程会调用
processCommandAndResetClient()方法,processCommandAndResetClient()方法会调用processCommand()执行具体的命令,并把执行结果写入到client对象的输出缓冲区中。 - 每次事件循环之前,Redis主线程会调用
handleClientsWithPendingWritesUsingThreads()方法,handleClientsWithPendingWritesUsingThreads()中主线程会把所有需要返回数据的client对象按照RoundRobin算法分配到io_threads_list队列数组中,并空循环等待所有的IO线程完成写数据的操作。 - IO线程会从对应的
io_threads_list队列中获取client对象,依次调用writeToClient()方法把client对象输出缓冲区中的数据通过socket返回给客户端。
其他
可能会有同学问,Redis里面引入多线程之后,会不会存在线程安全问题。
根据上面的分析可以得出结论:不会存在线程安全问题。
Redis主线程跟IO线程通过共享变量io_threads_pending进行通信,而io_threads_pending是_Atomic限定符限定的,所以这一块不会存在线程安全问题。
而且,在IO线程执行读写数据操作的时候,主线程是处于空循环等待状态,不会进行其他的操作,所以也不会有线程安全问题。














 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









