







到了考试周了佯,可是偏偏这个时候迎来了很多很多的课程设计,幸好教授把C语言的课程设计提前发出了,不然都在最后几周,加上数据结构的课程设计就没有时间做这个啦~
刚开始打算做成UWP应用的,可是网上的教程都是C#,并且用C++做的话某些功能和C#不一样,所以就这样拖了好多周,省赛前一点儿也没有开始做,等到省赛结束之后,别人都差不多完成啦!而我才开始准备查找资料……
然而一周过去了,进度还是0%。噫,1%吧!
眼看就要开始验收了,算了,还是用最简单的 EasyX 做吧!以后的 C# 课程设计再考虑 UWP。
周一开始敲代码,整整一周的课余时间,都在努力做这个,现在想起来,那个时候真的好累唉,居然没有感觉到~😔
最初做这个游戏是因为想起来 秦时明月中的 墨攻棋阵,也就是黑白棋,努力还原动漫中的场景,周末的时候终于完成了。
先附图:

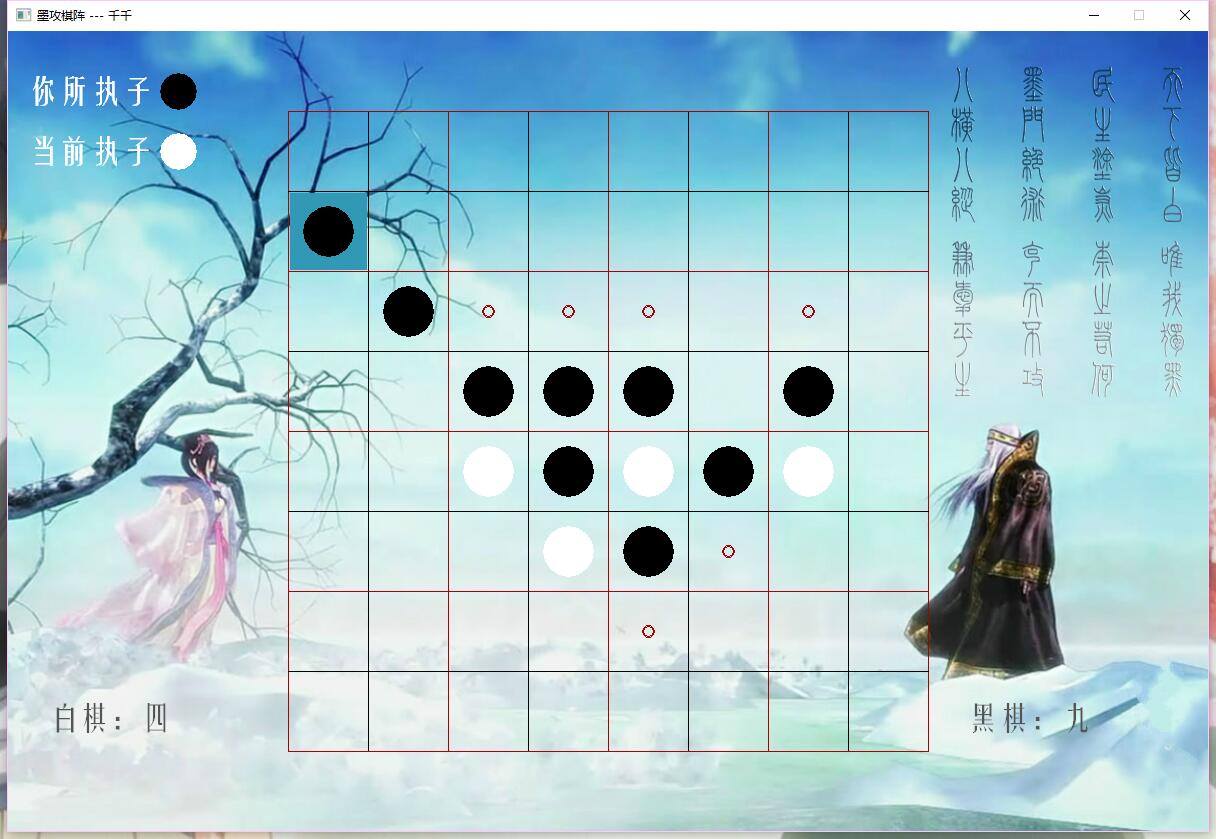


怎么说千千也都是新手呢!感觉做的还算满意吧!
人机对战中有三种模式哦!
简单、中等、困难
那么,接下来,我们一起来看看黑白棋中的AI是如何实现的。
对于我们来说,下棋的时候总是想着如何才能对自己最有利,当前最优?还是全局最优?
如果我们往后几步考虑的话,那便是全局最优啦!那当我们只看眼下哪一个位置的落子对自己最有利,这样便是当前最优,也是局部最优。
在黑白棋中,我们同样可以采用这样的思想。
首先来看看简单AI,因为简单呗,所以它返回的仅仅只是当前的最优解,再怎么说也不能让它随机返回坐标对吧!
那局部最优解又是以什么为评测标准的呢?
嗯,我们采用的是能够转换对方棋子最多的位置,这个可不是行动力哦!
POINT2 Easy()//人机对战简单AI
{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









