数据的分组与聚合操作
在数据分析工作流中,一个重要的工作是对数据进行分类,并在每一组上应用一个聚合函数或转换函数。在经历载入、合并、准备数据集之后,可能需要计算分组统计或者制作数据透视表用于报告或者可视化的目的。pandas提供了一个非常灵活的groupby接口,来对数据集进行切片、切块和总结。本章主要内容如下:
- 使用一个或多个键将pandas对象拆分成多块
- 计算组汇总统计信息
- 应用组内变换或其他操作
- 计算数据透视表和交叉表
- 执行分位数分析和其他统计组分析
import pandas as pdimport numpy as np
GroupBy
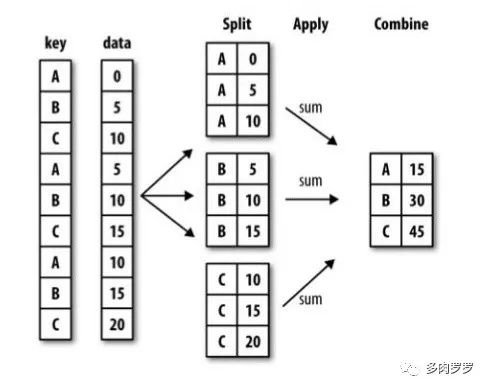
groupby包含三个步骤:split-apply-combine。首先是将数据按照特定轴向分离,进行分组;然后将函数应用到各个组中;最后将结果联合起来。
# 我们先创建一个DataFrame。对其进行groupby操作df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'], 'key2': ['one', 'two', 'one', 'two', 'one'], 'data1': np.random.randn(5), 'data2': np.random.randn(5)})df
| key1 | key2 | data1 | data2 |
|---|
| 0 | a | one | 0.209170 | -0.331921 |
|---|
| 1 | a | two | 0.162572 | 0.322581 |
|---|
| 2 | b | one | 0.145062 | 1.242235 |
|---|
| 3 | b | two | -1.705477 | -0.563494 |
|---|
| 4 | a | one | 0.309842 | -1.541020 |
|---|
# 根据key1标签计算data1列的均值grouped = df['data1'].groupby(df['key1'])grouped
# grouped变量是一个GroupBy对象,可以对其进行操作# 比如计算均值grouped.mean() # 得到的就是data1根据key1分组的均值
key1
a 0.227195
b -0.780207
Name: data1, dtype: float64
# 当然我们可以使用列表传入Series分组键进行分组means = df['data1'].groupby([df['key1'], df['key2']]).mean() # means含有多层索引means
key1 key2
a one 0.259506
two 0.162572
b one 0.145062
two -1.705477
Name: data1, dtype: float64
# 当然,分组的键也可以是正确长度的任何数组states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])years = np.array([2005, 2005, 2006, 2005, 2006])df['data1'].groupby([states, years]).mean()
California 2005 0.162572
2006 0.145062
Ohio 2005 -0.748154
2006 0.309842
Name: data1, dtype: float64
# 分组信息如果在DataFrame中,则可以直接使用列名作为分组键df.groupby('key1').mean() # 因为df['key2']不是数值数据,所以并不会计算均值
| data1 | data2 |
|---|
| key1 | | |
|---|
| a | 0.227195 | -0.516787 |
|---|
| b | -0.780207 | 0.339371 |
|---|
# 使用size查看组大小信息,注意缺失值将排除在外df.groupby(['key1', 'key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
遍历各分组
GroupBy对象支持迭代,会先生成一个包含组名和数据块的2维元组序列
for name, group in df.groupby('key1'): print(name) print(group)
a
key1 key2 data1 data2
0 a one 0.209170 -0.331921
1 a two 0.162572 0.322581
4 a one 0.309842 -1.541020
b
key1 key2 data1 data2
2 b one 0.145062 1.242235
3 b two -1.705477 -0.563494
# 在有多个分组键的情况下,元组中的第一个元素是键值的元组for k, group in df.groupby(['key1', 'key2']): print(k) print(group)
('a', 'one')
key1 key2 data1 data2
0 a one 0.209170 -0.331921
4 a one 0.309842 -1.541020
('a', 'two')
key1 key2 data1 data2
1 a two 0.162572 0.322581
('b', 'one')
key1 key2 data1 data2
2 b one 0.145062 1.242235
('b', 'two')
key1 key2 data1 data2
3 b two -1.705477 -0.563494
# 选择任意一块数据进行操作pieces = dict(list(df.groupby('key1')))pieces['b']
| key1 | key2 | data1 | data2 |
|---|
| 2 | b | one | 0.145062 | 1.242235 |
|---|
| 3 | b | two | -1.705477 | -0.563494 |
|---|
默认情况下,groupby在axis=0的轴向上进行分组,但是也可以选定其他轴向。
# 我们可以根据数据类型进行分组df.dtypes
key1 object
key2 object
data1 float64
data2 float64
dtype: object
grouped = df.groupby(df.dtypes, axis=1)for dtype, group in grouped: print(dtype) print(group)
float64
data1 data2
0 0.209170 -0.331921
1 0.162572 0.322581
2 0.145062 1.242235
3 -1.705477 -0.563494
4 0.309842 -1.541020
object
key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
选择一列或者所有列的子集
将从DataFrame中创建的GroupBy对象用列名称或者列名称数组进行索引时,相当于获取用于聚合的列子集。也就是说:
- df.groupby('key1')['data1'] 相当于df['data1'].groupby(df['key1'])
- df.groupby('key1')[['data1']]相当于df[['data1']].groupby(df['key1'])
对于大型数据集,可能只需要聚合少部分列
# 计算data2列的均值并获得DataFramedf.groupby('key1')[['data1']].mean()
| data1 |
|---|
| key1 | |
|---|
| a | 0.227195 |
|---|
| b | -0.780207 |
|---|
# 如果只有单个列名进行传递,则返回的是Seriess_grouped = df.groupby(['key1', 'key2'])['data2']s_grouped # 可以看到获得的是分组的Series
s_grouped.mean()
key1 key2
a one -0.936470
two 0.322581
b one 1.242235
two -0.563494
Name: data2, dtype: float64
使用字典和Series分组
分组信息可能会以非数组形式存在
people = pd.DataFrame(np.random.randn(5, 5), columns=['a', 'b', 'c', 'd', 'e'], index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])people.iloc[2:3, [1, 2]] = np.nanpeople
| a | b | c | d | e |
|---|
| Joe | 1.221724 | 0.110267 | 1.285643 | -2.290401 | 0.409033 |
|---|
| Steve | 0.847775 | -0.455833 | 0.725666 | -0.694706 | -1.162236 |
|---|
| Wes | -0.504510 | NaN | NaN | 1.069262 | 1.364316 |
|---|
| Jim | -2.089744 | -0.940379 | -0.737187 | 0.189542 | -1.010504 |
|---|
| Travis | -1.310530 | -0.341813 | -1.730868 | 0.289435 | 0.053035 |
|---|
# 'f'未用于分组mapping = {'a': 'red', 'b':'blue', 'c':'blue', 'd':'blue', 'e': 'red', 'f': 'orange'}by_column = people.groupby(mapping, axis=1)by_column.sum()
| blue | red |
|---|
| Joe | -0.894491 | 1.630757 |
|---|
| Steve | -0.424873 | -0.314461 |
|---|
| Wes | 1.069262 | 0.859806 |
|---|
| Jim | -1.488024 | -3.100248 |
|---|
| Travis | -1.783247 | -1.257495 |
|---|
# 使用Series分组map_series = pd.Series(mapping)people.groupby(map_series, axis=1).count()
| blue | red |
|---|
| Joe | 3 | 2 |
|---|
| Steve | 3 | 2 |
|---|
| Wes | 1 | 2 |
|---|
| Jim | 3 | 2 |
|---|
| Travis | 3 | 2 |
|---|
使用函数分组
作为分组键传递的函数将会按照每个索引值调用一次,同时返回值用作分组名称。
# 根据名字长度分组people.groupby(len).sum()
| a | b | c | d | e |
|---|
| 3 | -1.372529 | -0.830111 | 0.548455 | -1.031598 | 0.762845 |
|---|
| 5 | 0.847775 | -0.455833 | 0.725666 | -0.694706 | -1.162236 |
|---|
| 6 | -1.310530 | -0.341813 | -1.730868 | 0.289435 | 0.053035 |
|---|
可以将函数与数组、字典或Series进行混合,所有的对象在内部都转换为数组。
key_list = ['one', 'one', 'one', 'two', 'two']for key, group in people.groupby([len, key_list]): print(key) print(group)
(3, 'one')
a b c d e
Joe 1.221724 0.110267 1.285643 -2.290401 0.409033
Wes -0.504510 NaN NaN 1.069262 1.364316
(3, 'two')
a b c d e
Jim -2.089744 -0.940379 -0.737187 0.189542 -1.010504
(5, 'one')
a b c d e
Steve 0.847775 -0.455833 0.725666 -0.694706 -1.162236
(6, 'two')
a b c d e
Travis -1.31053 -0.341813 -1.730868 0.289435 0.053035
根据索引层级分组
在分层索引的某个层级上可以进行聚合
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'], [1, 3, 5, 1, 3]], names=['cty', 'tenor'])hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)hier_df
| cty | US | JP |
|---|
| tenor | 1 | 3 | 5 | 1 | 3 |
|---|
| 0 | 2.303857 | 1.048559 | -0.188793 | -0.178907 | -0.334412 |
|---|
| 1 | -0.221124 | 0.218428 | -0.435082 | 0.538684 | -0.740732 |
|---|
| 2 | 0.187450 | 0.325777 | -0.892818 | -0.897597 | 0.855642 |
|---|
| 3 | -0.006315 | 0.537607 | 0.855795 | -0.135583 | -0.635938 |
|---|
# 根据层级索引时,将层级数值或层级名称传递给level关键字hier_df.groupby(level='cty', axis=1).count()
数据聚合
数据聚合就是对Series或DataFrame所有列使用aggregate和所需函数,或者调用mean、std等方法 groupby优化方法:
| 函数名 | 描述 |
|---|
| count | 分组中的非NA数量 |
| sum | 非NA值的累和 |
| mean | 非NA值的均值 |
| median | 非NA值的算数中位数 |
逐列及多函数应用
# 使用上篇文章使用的tips数据集tips = pd.read_csv(r'tip.csv')tips['tip_pct'] = tips['tip'] / (tips['total_bill'])tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
|---|
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
|---|
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
|---|
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
|---|
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
|---|
# 根据day和smoker对tips进行分组grouped = tips.groupby(['day', 'smoker'])# 获得描述性统计(不使用describe方法)# 将函数名以字符串形式传递grouped_pct = grouped['tip_pct']grouped_pct.agg('mean') # 得到的是Series
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
# 若传递的是函数或者函数名的列表,则会获得一个列名为函数名的DataFrame# 首先定义一个函数,获得极差def peak_to_peak(arr): return arr.max() - arr.min()grouped_pct.agg(['mean', 'std', peak_to_peak]) # 只有groupby内置的方法才可以直接传字符串,否则报错
| | mean | std | peak_to_peak |
|---|
| day | smoker | | | |
|---|
| Fri | No | 0.151650 | 0.028123 | 0.067349 |
|---|
| Yes | 0.174783 | 0.051293 | 0.159925 |
|---|
| Sat | No | 0.158048 | 0.039767 | 0.235193 |
|---|
| Yes | 0.147906 | 0.061375 | 0.290095 |
|---|
| Sun | No | 0.160113 | 0.042347 | 0.193226 |
|---|
| Yes | 0.187250 | 0.154134 | 0.644685 |
|---|
| Thur | No | 0.160298 | 0.038774 | 0.193350 |
|---|
| Yes | 0.163863 | 0.039389 | 0.151240 |
|---|
# 如果传递的是(name, function)的元组,那么DataFrame的列名则是元组的第一个元素grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
| | foo | bar |
|---|
| day | smoker | | |
|---|
| Fri | No | 0.151650 | 0.028123 |
|---|
| Yes | 0.174783 | 0.051293 |
|---|
| Sat | No | 0.158048 | 0.039767 |
|---|
| Yes | 0.147906 | 0.061375 |
|---|
| Sun | No | 0.160113 | 0.042347 |
|---|
| Yes | 0.187250 | 0.154134 |
|---|
| Thur | No | 0.160298 | 0.038774 |
|---|
| Yes | 0.163863 | 0.039389 |
|---|
在DataFrame中,可以指定应用到所有列上的函数列表或者每一列上应用不同函数
functions = ['count', 'mean', 'max']result = grouped['tip_pct', 'total_bill'].agg(functions)result
| | tip_pct | total_bill |
|---|
| | count | mean | max | count | mean | max |
|---|
| day | smoker | | | | | | |
|---|
| Fri | No | 4 | 0.151650 | 0.187735 | 4 | 18.420000 | 22.75 |
|---|
| Yes | 15 | 0.174783 | 0.263480 | 15 | 16.813333 | 40.17 |
|---|
| Sat | No | 45 | 0.158048 | 0.291990 | 45 | 19.661778 | 48.33 |
|---|
| Yes | 42 | 0.147906 | 0.325733 | 42 | 21.276667 | 50.81 |
|---|
| Sun | No | 57 | 0.160113 | 0.252672 | 57 | 20.506667 | 48.17 |
|---|
| Yes | 19 | 0.187250 | 0.710345 | 19 | 24.120000 | 45.35 |
|---|
| Thur | No | 45 | 0.160298 | 0.266312 | 45 | 17.113111 | 41.19 |
|---|
| Yes | 17 | 0.163863 | 0.241255 | 17 | 19.190588 | 43.11 |
|---|
产生的DataFrame拥有分层列
result['tip_pct']
| | count | mean | max |
|---|
| day | smoker | | | |
|---|
| Fri | No | 4 | 0.151650 | 0.187735 |
|---|
| Yes | 15 | 0.174783 | 0.263480 |
|---|
| Sat | No | 45 | 0.158048 | 0.291990 |
|---|
| Yes | 42 | 0.147906 | 0.325733 |
|---|
| Sun | No | 57 | 0.160113 | 0.252672 |
|---|
| Yes | 19 | 0.187250 | 0.710345 |
|---|
| Thur | No | 45 | 0.160298 | 0.266312 |
|---|
| Yes | 17 | 0.163863 | 0.241255 |
|---|
和以前一样,可以传递具有自定义名称的元组列表
ftuples = [('Durchschnitt', 'mean'), ('Abweichung', np.var)]grouped['tip_pct', 'total_bill'].agg(ftuples)
| | tip_pct | total_bill |
|---|
| | Durchschnitt | Abweichung | Durchschnitt | Abweichung |
|---|
| day | smoker | | | | |
|---|
| Fri | No | 0.151650 | 0.000791 | 18.420000 | 25.596333 |
|---|
| Yes | 0.174783 | 0.002631 | 16.813333 | 82.562438 |
|---|
| Sat | No | 0.158048 | 0.001581 | 19.661778 | 79.908965 |
|---|
| Yes | 0.147906 | 0.003767 | 21.276667 | 101.387535 |
|---|
| Sun | No | 0.160113 | 0.001793 | 20.506667 | 66.099980 |
|---|
| Yes | 0.187250 | 0.023757 | 24.120000 | 109.046044 |
|---|
| Thur | No | 0.160298 | 0.001503 | 17.113111 | 59.625081 |
|---|
| Yes | 0.163863 | 0.001551 | 19.190588 | 69.808518 |
|---|
使用含有列名与函数对应关系的字典传递给agg,使列执行不同的函数操作;当多个函数应用于至少一个列时,会产生多层列
grouped.agg({'tip_pct': ['min', 'max', 'mean', 'std'], 'size': 'sum'})
| | tip_pct | size |
|---|
| | min | max | mean | std | sum |
|---|
| day | smoker | | | | | |
|---|
| Fri | No | 0.120385 | 0.187735 | 0.151650 | 0.028123 | 9 |
|---|
| Yes | 0.103555 | 0.263480 | 0.174783 | 0.051293 | 31 |
|---|
| Sat | No | 0.056797 | 0.291990 | 0.158048 | 0.039767 | 115 |
|---|
| Yes | 0.035638 | 0.325733 | 0.147906 | 0.061375 | 104 |
|---|
| Sun | No | 0.059447 | 0.252672 | 0.160113 | 0.042347 | 167 |
|---|
| Yes | 0.065660 | 0.710345 | 0.187250 | 0.154134 | 49 |
|---|
| Thur | No | 0.072961 | 0.266312 | 0.160298 | 0.038774 | 112 |
|---|
| Yes | 0.090014 | 0.241255 | 0.163863 | 0.039389 | 40 |
|---|
返回不含行索引的聚合数据
# 使用as_index=False来禁用分组键作为索引tips.groupby(['day','smoker'], as_index=False).mean()# 当然,使用reset_index也是一样的tips.groupby(['day','smoker']).mean().reset_index()
| day | smoker | total_bill | tip | size | tip_pct |
|---|
| 0 | Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
|---|
| 1 | Fri | Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
|---|
| 2 | Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
|---|
| 3 | Sat | Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
|---|
| 4 | Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
|---|
| 5 | Sun | Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
|---|
| 6 | Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
|---|
| 7 | Thur | Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
|---|
通用split-apply-combine
使用之前的tip数据集,选出tip_pct最高的五个组。首先,可以写一个在特定列中选出最大值所在行的函数
def top(df, n=5, column='tip_pct'): return tips.sort_values(by=column)[-n:]
top(tips, n=6)
| total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
|---|
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
# 按照smoker, day分组# top函数在每一行分组上被调用,之后使用pandas.concat将结果粘贴,分组名为标签# top函数的参数可以放在函数后进行传递tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')
| | | total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| smoker | day | | | | | | | | |
|---|
| No | Fri | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Sat | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Sun | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Thur | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Yes | Fri | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Sat | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Sun | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
| Thur | 170 | 50.81 | 10.0 | Yes | Sat | Dinner | 3 | 0.196812 |
|---|
压缩分组键
向groupby传递groupby_key=False ,不展示分组索引
tips.groupby('smoker').apply(top)
| | total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| smoker | | | | | | | | |
|---|
| No | 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
| Yes | 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
tips.groupby('smoker', as_index=False).apply(top)
| | total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| 0 | 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
| 1 | 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
tips.groupby('smoker', group_keys=False).apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct |
|---|
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
|---|
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
|---|
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
|---|
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
|---|
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
|---|
tips.groupby(['day','smoker']).mean()
| | total_bill | tip | size | tip_pct |
|---|
| day | smoker | | | | |
|---|
| Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
|---|
| Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
|---|
| Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
|---|
| Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
|---|
| Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
|---|
| Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
|---|
| Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
|---|
| Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
|---|
tips.groupby(['day','smoker'], group_keys=False).mean()
| | total_bill | tip | size | tip_pct |
|---|
| day | smoker | | | | |
|---|
| Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
|---|
| Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
|---|
| Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
|---|
| Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
|---|
| Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
|---|
| Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
|---|
| Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
|---|
| Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
|---|
注意:
as_index:对于聚合输出,返回以组标签作为索引的对象。仅与DataFrame输入相关。as_index = False实际上是“SQL风格”的分组输出。
group_keys:调用apply时,选择是否将组键添加到索引
分位数与桶分析
使用groupby方法与cut, qcut配合使用,对数据更方便地进行分桶或分位分析
frame = pd.DataFrame({'data1': np.random.randn(1000), 'data2': np.random.randn(1000)})quantiles = pd.cut(frame.data1, 4)quantiles[:10]
0 (-1.138, 0.242]
1 (0.242, 1.622]
2 (0.242, 1.622]
3 (-1.138, 0.242]
4 (-1.138, 0.242]
5 (-2.524, -1.138]
6 (0.242, 1.622]
7 (-1.138, 0.242]
8 (-1.138, 0.242]
9 (-1.138, 0.242]
Name: data1, dtype: category
Categories (4, interval[float64]): [(-2.524, -1.138] < (-1.138, 0.242] < (0.242, 1.622] < (1.622, 3.002]]
def get_stats(group): return {'min': group.min(), 'max': group.max(), 'count': group.count(), 'mean': group.mean()}grouped = frame.data2.groupby(quantiles)grouped.apply(get_stats)
data1
(-2.524, -1.138] min -2.243129
max 2.431713
count 116.000000
mean 0.111999
(-1.138, 0.242] min -2.734511
max 2.722345
count 467.000000
mean 0.028268
(0.242, 1.622] min -2.654807
max 2.826075
count 356.000000
mean 0.075527
(1.622, 3.002] min -2.873482
max 2.594543
count 61.000000
mean -0.007187
Name: data2, dtype: float64
# 上面获得的是等长桶,我们可以使用qcut方法获得等大小的桶grouping = pd.qcut(frame.data1, 10, labels=False)grouped = frame.data2.groupby(grouping)grouped.apply(get_stats).unstack()
| min | max | count | mean |
|---|
| data1 | | | | |
|---|
| 0 | -2.243129 | 2.431713 | 100.0 | 0.102224 |
|---|
| 1 | -2.296063 | 2.376008 | 100.0 | -0.015589 |
|---|
| 2 | -1.947194 | 2.722345 | 100.0 | 0.070937 |
|---|
| 3 | -1.980102 | 2.534790 | 100.0 | 0.107431 |
|---|
| 4 | -2.734511 | 2.335623 | 100.0 | -0.025969 |
|---|
| 5 | -2.424619 | 2.345450 | 100.0 | 0.098001 |
|---|
| 6 | -2.654807 | 2.398495 | 100.0 | 0.026486 |
|---|
| 7 | -2.076728 | 2.826075 | 100.0 | 0.038720 |
|---|
| 8 | -2.483275 | 2.118598 | 100.0 | 0.056305 |
|---|
| 9 | -2.873482 | 2.594543 | 100.0 | 0.067875 |
|---|
使用指定分组值填充缺失值
s = pd.Series(np.random.randn(6))s[::2] = np.nans.fillna(s.mean())
0 0.057708
1 -0.045778
2 0.057708
3 0.047644
4 0.057708
5 0.171259
dtype: float64
states = ['Ohio', 'New Year', 'Vermont', 'Florida', 'Oregon', 'Nevada', 'California', 'Idaho']group_key = ['East'] * 4 + ['West'] * 4data = pd.Series(np.random.randn(8), index=states)data
Ohio 0.350673
New Year -0.126434
Vermont -0.299054
Florida -0.175114
Oregon 0.667130
Nevada 1.023922
California 0.840702
Idaho -0.662078
dtype: float64
data[['Vermont', 'Nevada', 'Idaho']] = np.nandata
Ohio 0.350673
New Year -0.126434
Vermont NaN
Florida -0.175114
Oregon 0.667130
Nevada NaN
California 0.840702
Idaho NaN
dtype: float64
data.groupby(group_key).mean()
East 0.016375
West 0.753916
dtype: float64
fill_mean = lambda g: g.fillna(g.mean())data.groupby(group_key).apply(fill_mean)
Ohio 0.350673
New Year -0.126434
Vermont 0.016375
Florida -0.175114
Oregon 0.667130
Nevada 0.753916
California 0.840702
Idaho 0.753916
dtype: float64
# 为每个分组预定义填充值fill_values = {'East': 0.5, 'West': -1}fill_func = lambda g: g.fillna(fill_values[g.name])data.groupby(group_key).apply(fill_func)
Ohio 0.350673
New Year -0.126434
Vermont 0.500000
Florida -0.175114
Oregon 0.667130
Nevada -1.000000
California 0.840702
Idaho -1.000000
dtype: float64
示例:随机采样与排列
使用Series的sample方法
# 构造一副英式扑克牌# 红桃。黑桃,梅花,方块suits = ['H', 'S', 'C', 'D']card_val = (list(range(1, 11)) + [10] * 3) * 4base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']cards = []for suit in ['H', 'S', 'C', 'D']: cards.extend(str(num) + suit for num in base_names)deck = pd.Series(card_val, index=cards)
deck[:13]
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
dtype: int64
# 从其中随机拿出五张牌deck.sample(5)
10D 10
7H 7
AH 1
6S 6
4D 4
dtype: int64
# 为了后续方便使用,我们定义一个随机抽牌的函数def draw(deck, n=5): return deck.sample(n)# 从每个花色中随机抽取两张牌,花色是牌名的最后一个字符get_suit = lambda card: card[-1]deck.groupby(get_suit).apply(draw, 2)
C QC 10
KC 10
D 10D 10
JD 10
H 2H 2
QH 10
S 7S 7
AS 1
dtype: int64
示例:分组加权平均
df = pd.DataFrame({'category': ['a', 'a', 'a', 'b', 'b', 'b'], 'data': np.random.randn(6), 'weights': np.random.rand(6)})df
| category | data | weights |
|---|
| 0 | a | 0.262284 | 0.552361 |
|---|
| 1 | a | 1.141605 | 0.295554 |
|---|
| 2 | a | 0.219825 | 0.030885 |
|---|
| 3 | b | 1.523184 | 0.917011 |
|---|
| 4 | b | -0.304085 | 0.136345 |
|---|
| 5 | b | -1.890389 | 0.219738 |
|---|
grouped = df.groupby('category')get_wavg = lambda g: np.average(g['data'], weights=g['weights'])grouped.apply(get_wavg)
category
a 0.556522
b 0.738300
dtype: float64
数据透视表和交叉表
数据透视表:根据一个或多个键聚合一张表的数据,将数据在矩形格式中排列。
pandas中出了groupby工具以及分层索引的重塑操作外,还有pivot_table方法,可以实现数据透视表的功能,pivot_table还可以添加部分总计。
# 使用index设置分组tips.pivot_table(index=['day', 'smoker'])
| | size | tip | tip_pct | total_bill |
|---|
| day | smoker | | | | |
|---|
| Fri | No | 2.250000 | 2.812500 | 0.151650 | 18.420000 |
|---|
| Yes | 2.066667 | 2.714000 | 0.174783 | 16.813333 |
|---|
| Sat | No | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
|---|
| Yes | 2.476190 | 2.875476 | 0.147906 | 21.276667 |
|---|
| Sun | No | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
|---|
| Yes | 2.578947 | 3.516842 | 0.187250 | 24.120000 |
|---|
| Thur | No | 2.488889 | 2.673778 | 0.160298 | 17.113111 |
|---|
| Yes | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
|---|
# 使用groupby呈现grouped = tips.groupby(['day', 'smoker'])for key, group in grouped: print(key) print(group)
('Fri', 'No')
total_bill tip smoker day time size tip_pct
91 22.49 3.50 No Fri Dinner 2 0.155625
94 22.75 3.25 No Fri Dinner 2 0.142857
99 12.46 1.50 No Fri Dinner 2 0.120385
223 15.98 3.00 No Fri Lunch 3 0.187735
('Fri', 'Yes')
total_bill tip smoker day time size tip_pct
90 28.97 3.00 Yes Fri Dinner 2 0.103555
92 5.75 1.00 Yes Fri Dinner 2 0.173913
93 16.32 4.30 Yes Fri Dinner 2 0.263480
95 40.17 4.73 Yes Fri Dinner 4 0.117750
96 27.28 4.00 Yes Fri Dinner 2 0.146628
97 12.03 1.50 Yes Fri Dinner 2 0.124688
98 21.01 3.00 Yes Fri Dinner 2 0.142789
100 11.35 2.50 Yes Fri Dinner 2 0.220264
101 15.38 3.00 Yes Fri Dinner 2 0.195059
220 12.16 2.20 Yes Fri Lunch 2 0.180921
221 13.42 3.48 Yes Fri Lunch 2 0.259314
222 8.58 1.92 Yes Fri Lunch 1 0.223776
224 13.42 1.58 Yes Fri Lunch 2 0.117735
225 16.27 2.50 Yes Fri Lunch 2 0.153657
226 10.09 2.00 Yes Fri Lunch 2 0.198216
('Sat', 'No')
total_bill tip smoker day time size tip_pct
19 20.65 3.35 No Sat Dinner 3 0.162228
20 17.92 4.08 No Sat Dinner 2 0.227679
21 20.29 2.75 No Sat Dinner 2 0.135535
22 15.77 2.23 No Sat Dinner 2 0.141408
23 39.42 7.58 No Sat Dinner 4 0.192288
24 19.82 3.18 No Sat Dinner 2 0.160444
25 17.81 2.34 No Sat Dinner 4 0.131387
26 13.37 2.00 No Sat Dinner 2 0.149589
27 12.69 2.00 No Sat Dinner 2 0.157604
28 21.70 4.30 No Sat Dinner 2 0.198157
29 19.65 3.00 No Sat Dinner 2 0.152672
30 9.55 1.45 No Sat Dinner 2 0.151832
31 18.35 2.50 No Sat Dinner 4 0.136240
32 15.06 3.00 No Sat Dinner 2 0.199203
33 20.69 2.45 No Sat Dinner 4 0.118415
34 17.78 3.27 No Sat Dinner 2 0.183915
35 24.06 3.60 No Sat Dinner 3 0.149626
36 16.31 2.00 No Sat Dinner 3 0.122624
37 16.93 3.07 No Sat Dinner 3 0.181335
38 18.69 2.31 No Sat Dinner 3 0.123596
39 31.27 5.00 No Sat Dinner 3 0.159898
40 16.04 2.24 No Sat Dinner 3 0.139651
57 26.41 1.50 No Sat Dinner 2 0.056797
59 48.27 6.73 No Sat Dinner 4 0.139424
64 17.59 2.64 No Sat Dinner 3 0.150085
65 20.08 3.15 No Sat Dinner 3 0.156873
66 16.45 2.47 No Sat Dinner 2 0.150152
68 20.23 2.01 No Sat Dinner 2 0.099357
70 12.02 1.97 No Sat Dinner 2 0.163894
71 17.07 3.00 No Sat Dinner 3 0.175747
74 14.73 2.20 No Sat Dinner 2 0.149355
75 10.51 1.25 No Sat Dinner 2 0.118934
104 20.92 4.08 No Sat Dinner 2 0.195029
108 18.24 3.76 No Sat Dinner 2 0.206140
110 14.00 3.00 No Sat Dinner 2 0.214286
111 7.25 1.00 No Sat Dinner 1 0.137931
212 48.33 9.00 No Sat Dinner 4 0.186220
227 20.45 3.00 No Sat Dinner 4 0.146699
228 13.28 2.72 No Sat Dinner 2 0.204819
232 11.61 3.39 No Sat Dinner 2 0.291990
233 10.77 1.47 No Sat Dinner 2 0.136490
235 10.07 1.25 No Sat Dinner 2 0.124131
238 35.83 4.67 No Sat Dinner 3 0.130338
239 29.03 5.92 No Sat Dinner 3 0.203927
242 17.82 1.75 No Sat Dinner 2 0.098204
('Sat', 'Yes')
total_bill tip smoker day time size tip_pct
56 38.01 3.00 Yes Sat Dinner 4 0.078927
58 11.24 1.76 Yes Sat Dinner 2 0.156584
60 20.29 3.21 Yes Sat Dinner 2 0.158206
61 13.81 2.00 Yes Sat Dinner 2 0.144823
62 11.02 1.98 Yes Sat Dinner 2 0.179673
63 18.29 3.76 Yes Sat Dinner 4 0.205577
67 3.07 1.00 Yes Sat Dinner 1 0.325733
69 15.01 2.09 Yes Sat Dinner 2 0.139241
72 26.86 3.14 Yes Sat Dinner 2 0.116902
73 25.28 5.00 Yes Sat Dinner 2 0.197785
76 17.92 3.08 Yes Sat Dinner 2 0.171875
102 44.30 2.50 Yes Sat Dinner 3 0.056433
103 22.42 3.48 Yes Sat Dinner 2 0.155219
105 15.36 1.64 Yes Sat Dinner 2 0.106771
106 20.49 4.06 Yes Sat Dinner 2 0.198145
107 25.21 4.29 Yes Sat Dinner 2 0.170171
109 14.31 4.00 Yes Sat Dinner 2 0.279525
168 10.59 1.61 Yes Sat Dinner 2 0.152030
169 10.63 2.00 Yes Sat Dinner 2 0.188147
170 50.81 10.00 Yes Sat Dinner 3 0.196812
171 15.81 3.16 Yes Sat Dinner 2 0.199873
206 26.59 3.41 Yes Sat Dinner 3 0.128244
207 38.73 3.00 Yes Sat Dinner 4 0.077459
208 24.27 2.03 Yes Sat Dinner 2 0.083642
209 12.76 2.23 Yes Sat Dinner 2 0.174765
210 30.06 2.00 Yes Sat Dinner 3 0.066534
211 25.89 5.16 Yes Sat Dinner 4 0.199305
213 13.27 2.50 Yes Sat Dinner 2 0.188395
214 28.17 6.50 Yes Sat Dinner 3 0.230742
215 12.90 1.10 Yes Sat Dinner 2 0.085271
216 28.15 3.00 Yes Sat Dinner 5 0.106572
217 11.59 1.50 Yes Sat Dinner 2 0.129422
218 7.74 1.44 Yes Sat Dinner 2 0.186047
219 30.14 3.09 Yes Sat Dinner 4 0.102522
229 22.12 2.88 Yes Sat Dinner 2 0.130199
230 24.01 2.00 Yes Sat Dinner 4 0.083299
231 15.69 3.00 Yes Sat Dinner 3 0.191205
234 15.53 3.00 Yes Sat Dinner 2 0.193175
236 12.60 1.00 Yes Sat Dinner 2 0.079365
237 32.83 1.17 Yes Sat Dinner 2 0.035638
240 27.18 2.00 Yes Sat Dinner 2 0.073584
241 22.67 2.00 Yes Sat Dinner 2 0.088222
('Sun', 'No')
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.059447
1 10.34 1.66 No Sun Dinner 3 0.160542
2 21.01 3.50 No Sun Dinner 3 0.166587
3 23.68 3.31 No Sun Dinner 2 0.139780
4 24.59 3.61 No Sun Dinner 4 0.146808
5 25.29 4.71 No Sun Dinner 4 0.186240
6 8.77 2.00 No Sun Dinner 2 0.228050
7 26.88 3.12 No Sun Dinner 4 0.116071
8 15.04 1.96 No Sun Dinner 2 0.130319
9 14.78 3.23 No Sun Dinner 2 0.218539
10 10.27 1.71 No Sun Dinner 2 0.166504
11 35.26 5.00 No Sun Dinner 4 0.141804
12 15.42 1.57 No Sun Dinner 2 0.101816
13 18.43 3.00 No Sun Dinner 4 0.162778
14 14.83 3.02 No Sun Dinner 2 0.203641
15 21.58 3.92 No Sun Dinner 2 0.181650
16 10.33 1.67 No Sun Dinner 3 0.161665
17 16.29 3.71 No Sun Dinner 3 0.227747
18 16.97 3.50 No Sun Dinner 3 0.206246
41 17.46 2.54 No Sun Dinner 2 0.145475
42 13.94 3.06 No Sun Dinner 2 0.219512
43 9.68 1.32 No Sun Dinner 2 0.136364
44 30.40 5.60 No Sun Dinner 4 0.184211
45 18.29 3.00 No Sun Dinner 2 0.164024
46 22.23 5.00 No Sun Dinner 2 0.224921
47 32.40 6.00 No Sun Dinner 4 0.185185
48 28.55 2.05 No Sun Dinner 3 0.071804
49 18.04 3.00 No Sun Dinner 2 0.166297
50 12.54 2.50 No Sun Dinner 2 0.199362
51 10.29 2.60 No Sun Dinner 2 0.252672
52 34.81 5.20 No Sun Dinner 4 0.149382
53 9.94 1.56 No Sun Dinner 2 0.156942
54 25.56 4.34 No Sun Dinner 4 0.169797
55 19.49 3.51 No Sun Dinner 2 0.180092
112 38.07 4.00 No Sun Dinner 3 0.105070
113 23.95 2.55 No Sun Dinner 2 0.106472
114 25.71 4.00 No Sun Dinner 3 0.155581
115 17.31 3.50 No Sun Dinner 2 0.202195
116 29.93 5.07 No Sun Dinner 4 0.169395
150 14.07 2.50 No Sun Dinner 2 0.177683
151 13.13 2.00 No Sun Dinner 2 0.152323
152 17.26 2.74 No Sun Dinner 3 0.158749
153 24.55 2.00 No Sun Dinner 4 0.081466
154 19.77 2.00 No Sun Dinner 4 0.101163
155 29.85 5.14 No Sun Dinner 5 0.172194
156 48.17 5.00 No Sun Dinner 6 0.103799
157 25.00 3.75 No Sun Dinner 4 0.150000
158 13.39 2.61 No Sun Dinner 2 0.194922
159 16.49 2.00 No Sun Dinner 4 0.121286
160 21.50 3.50 No Sun Dinner 4 0.162791
161 12.66 2.50 No Sun Dinner 2 0.197472
162 16.21 2.00 No Sun Dinner 3 0.123381
163 13.81 2.00 No Sun Dinner 2 0.144823
165 24.52 3.48 No Sun Dinner 3 0.141925
166 20.76 2.24 No Sun Dinner 2 0.107900
167 31.71 4.50 No Sun Dinner 4 0.141911
185 20.69 5.00 No Sun Dinner 5 0.241663
('Sun', 'Yes')
total_bill tip smoker day time size tip_pct
164 17.51 3.00 Yes Sun Dinner 2 0.171331
172 7.25 5.15 Yes Sun Dinner 2 0.710345
173 31.85 3.18 Yes Sun Dinner 2 0.099843
174 16.82 4.00 Yes Sun Dinner 2 0.237812
175 32.90 3.11 Yes Sun Dinner 2 0.094529
176 17.89 2.00 Yes Sun Dinner 2 0.111794
177 14.48 2.00 Yes Sun Dinner 2 0.138122
178 9.60 4.00 Yes Sun Dinner 2 0.416667
179 34.63 3.55 Yes Sun Dinner 2 0.102512
180 34.65 3.68 Yes Sun Dinner 4 0.106205
181 23.33 5.65 Yes Sun Dinner 2 0.242177
182 45.35 3.50 Yes Sun Dinner 3 0.077178
183 23.17 6.50 Yes Sun Dinner 4 0.280535
184 40.55 3.00 Yes Sun Dinner 2 0.073983
186 20.90 3.50 Yes Sun Dinner 3 0.167464
187 30.46 2.00 Yes Sun Dinner 5 0.065660
188 18.15 3.50 Yes Sun Dinner 3 0.192837
189 23.10 4.00 Yes Sun Dinner 3 0.173160
190 15.69 1.50 Yes Sun Dinner 2 0.095602
('Thur', 'No')
total_bill tip smoker day time size tip_pct
77 27.20 4.00 No Thur Lunch 4 0.147059
78 22.76 3.00 No Thur Lunch 2 0.131810
79 17.29 2.71 No Thur Lunch 2 0.156738
81 16.66 3.40 No Thur Lunch 2 0.204082
82 10.07 1.83 No Thur Lunch 1 0.181728
84 15.98 2.03 No Thur Lunch 2 0.127034
85 34.83 5.17 No Thur Lunch 4 0.148435
86 13.03 2.00 No Thur Lunch 2 0.153492
87 18.28 4.00 No Thur Lunch 2 0.218818
88 24.71 5.85 No Thur Lunch 2 0.236746
89 21.16 3.00 No Thur Lunch 2 0.141777
117 10.65 1.50 No Thur Lunch 2 0.140845
118 12.43 1.80 No Thur Lunch 2 0.144811
119 24.08 2.92 No Thur Lunch 4 0.121262
120 11.69 2.31 No Thur Lunch 2 0.197605
121 13.42 1.68 No Thur Lunch 2 0.125186
122 14.26 2.50 No Thur Lunch 2 0.175316
123 15.95 2.00 No Thur Lunch 2 0.125392
124 12.48 2.52 No Thur Lunch 2 0.201923
125 29.80 4.20 No Thur Lunch 6 0.140940
126 8.52 1.48 No Thur Lunch 2 0.173709
127 14.52 2.00 No Thur Lunch 2 0.137741
128 11.38 2.00 No Thur Lunch 2 0.175747
129 22.82 2.18 No Thur Lunch 3 0.095530
130 19.08 1.50 No Thur Lunch 2 0.078616
131 20.27 2.83 No Thur Lunch 2 0.139615
132 11.17 1.50 No Thur Lunch 2 0.134288
133 12.26 2.00 No Thur Lunch 2 0.163132
134 18.26 3.25 No Thur Lunch 2 0.177985
135 8.51 1.25 No Thur Lunch 2 0.146886
136 10.33 2.00 No Thur Lunch 2 0.193611
137 14.15 2.00 No Thur Lunch 2 0.141343
139 13.16 2.75 No Thur Lunch 2 0.208967
140 17.47 3.50 No Thur Lunch 2 0.200343
141 34.30 6.70 No Thur Lunch 6 0.195335
142 41.19 5.00 No Thur Lunch 5 0.121389
143 27.05 5.00 No Thur Lunch 6 0.184843
144 16.43 2.30 No Thur Lunch 2 0.139988
145 8.35 1.50 No Thur Lunch 2 0.179641
146 18.64 1.36 No Thur Lunch 3 0.072961
147 11.87 1.63 No Thur Lunch 2 0.137321
148 9.78 1.73 No Thur Lunch 2 0.176892
149 7.51 2.00 No Thur Lunch 2 0.266312
195 7.56 1.44 No Thur Lunch 2 0.190476
243 18.78 3.00 No Thur Dinner 2 0.159744
('Thur', 'Yes')
total_bill tip smoker day time size tip_pct
80 19.44 3.00 Yes Thur Lunch 2 0.154321
83 32.68 5.00 Yes Thur Lunch 2 0.152999
138 16.00 2.00 Yes Thur Lunch 2 0.125000
191 19.81 4.19 Yes Thur Lunch 2 0.211509
192 28.44 2.56 Yes Thur Lunch 2 0.090014
193 15.48 2.02 Yes Thur Lunch 2 0.130491
194 16.58 4.00 Yes Thur Lunch 2 0.241255
196 10.34 2.00 Yes Thur Lunch 2 0.193424
197 43.11 5.00 Yes Thur Lunch 4 0.115982
198 13.00 2.00 Yes Thur Lunch 2 0.153846
199 13.51 2.00 Yes Thur Lunch 2 0.148038
200 18.71 4.00 Yes Thur Lunch 3 0.213789
201 12.74 2.01 Yes Thur Lunch 2 0.157771
202 13.00 2.00 Yes Thur Lunch 2 0.153846
203 16.40 2.50 Yes Thur Lunch 2 0.152439
204 20.53 4.00 Yes Thur Lunch 4 0.194837
205 16.47 3.23 Yes Thur Lunch 3 0.196114
# 在tip_pct和size上进行聚合,并根据time分组,把smoker放入表的列,而将day放入表的行tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker')
| | size | tip_pct |
|---|
| smoker | No | Yes | No | Yes |
|---|
| time | day | | | | |
|---|
| Dinner | Fri | 2.000000 | 2.222222 | 0.139622 | 0.165347 |
|---|
| Sat | 2.555556 | 2.476190 | 0.158048 | 0.147906 |
|---|
| Sun | 2.929825 | 2.578947 | 0.160113 | 0.187250 |
|---|
| Thur | 2.000000 | NaN | 0.159744 | NaN |
|---|
| Lunch | Fri | 3.000000 | 1.833333 | 0.187735 | 0.188937 |
|---|
| Thur | 2.500000 | 2.352941 | 0.160311 | 0.163863 |
|---|
# 通过传递margins=True来包含部分统计。tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker', margins=True)
| | size | tip_pct |
|---|
| smoker | No | Yes | All | No | Yes | All |
|---|
| time | day | | | | | | |
|---|
| Dinner | Fri | 2.000000 | 2.222222 | 2.166667 | 0.139622 | 0.165347 | 0.158916 |
|---|
| Sat | 2.555556 | 2.476190 | 2.517241 | 0.158048 | 0.147906 | 0.153152 |
|---|
| Sun | 2.929825 | 2.578947 | 2.842105 | 0.160113 | 0.187250 | 0.166897 |
|---|
| Thur | 2.000000 | NaN | 2.000000 | 0.159744 | NaN | 0.159744 |
|---|
| Lunch | Fri | 3.000000 | 1.833333 | 2.000000 | 0.187735 | 0.188937 | 0.188765 |
|---|
| Thur | 2.500000 | 2.352941 | 2.459016 | 0.160311 | 0.163863 | 0.161301 |
|---|
| All | | 2.668874 | 2.408602 | 2.569672 | 0.159328 | 0.163196 | 0.160803 |
|---|
# 我们也可以使用不同的聚合函数,将函数传递给aggfunc,比如'count'和lentips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day', aggfunc=len, margins=True)
| day | Fri | Sat | Sun | Thur | All |
|---|
| time | smoker | | | | | |
|---|
| Dinner | No | 3.0 | 45.0 | 57.0 | 1.0 | 106.0 |
|---|
| Yes | 9.0 | 42.0 | 19.0 | NaN | 70.0 |
|---|
| Lunch | No | 1.0 | NaN | NaN | 44.0 | 45.0 |
|---|
| Yes | 6.0 | NaN | NaN | 17.0 | 23.0 |
|---|
| All | | 19.0 | 87.0 | 76.0 | 62.0 | 244.0 |
|---|
# 当然,也可以使用fill_value填充空值tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'], columns='day', aggfunc='mean', fill_value=0)
| | day | Fri | Sat | Sun | Thur |
|---|
| time | size | smoker | | | | |
|---|
| Dinner | 1 | No | 0.000000 | 0.137931 | 0.000000 | 0.000000 |
|---|
| Yes | 0.000000 | 0.325733 | 0.000000 | 0.000000 |
|---|
| 2 | No | 0.139622 | 0.162705 | 0.168859 | 0.159744 |
|---|
| Yes | 0.171297 | 0.148668 | 0.207893 | 0.000000 |
|---|
| 3 | No | 0.000000 | 0.154661 | 0.152663 | 0.000000 |
|---|
| Yes | 0.000000 | 0.144995 | 0.152660 | 0.000000 |
|---|
| 4 | No | 0.000000 | 0.150096 | 0.148143 | 0.000000 |
|---|
| Yes | 0.117750 | 0.124515 | 0.193370 | 0.000000 |
|---|
| 5 | No | 0.000000 | 0.000000 | 0.206928 | 0.000000 |
|---|
| Yes | 0.000000 | 0.106572 | 0.065660 | 0.000000 |
|---|
| 6 | No | 0.000000 | 0.000000 | 0.103799 | 0.000000 |
|---|
| Lunch | 1 | No | 0.000000 | 0.000000 | 0.000000 | 0.181728 |
|---|
| Yes | 0.223776 | 0.000000 | 0.000000 | 0.000000 |
|---|
| 2 | No | 0.000000 | 0.000000 | 0.000000 | 0.166005 |
|---|
| Yes | 0.181969 | 0.000000 | 0.000000 | 0.158843 |
|---|
| 3 | No | 0.187735 | 0.000000 | 0.000000 | 0.084246 |
|---|
| Yes | 0.000000 | 0.000000 | 0.000000 | 0.204952 |
|---|
| 4 | No | 0.000000 | 0.000000 | 0.000000 | 0.138919 |
|---|
| Yes | 0.000000 | 0.000000 | 0.000000 | 0.155410 |
|---|
| 5 | No | 0.000000 | 0.000000 | 0.000000 | 0.121389 |
|---|
| 6 | No | 0.000000 | 0.000000 | 0.000000 | 0.173706 |
|---|
pivot_table选项
| 选项名 | 描述 |
|---|
| values | 需要聚合的列名;默认情况下聚合所有数值型的列 |
| index | 在结果透视表的行上进行分组的列名或其他分组键 |
| columns | 在结果透视表的列上进行分组的列名或其他分组键 |
| aggfunc | 聚合函数或函数列表,默认为'mean' |
| fill_value | 替换缺失值 |
| dropna | 删除含有NA的列 |
| margins | 添加行/列小计和总计 |
crosstab-交叉表
crosstab前两个参数是数组、Series或者数组列表,计算分组频率
pd.crosstab([tips['time'], tips['day']], tips['smoker'], margins=True)
| smoker | No | Yes | All |
|---|
| time | day | | | |
|---|
| Dinner | Fri | 3 | 9 | 12 |
|---|
| Sat | 45 | 42 | 87 |
|---|
| Sun | 57 | 19 | 76 |
|---|
| Thur | 1 | 0 | 1 |
|---|
| Lunch | Fri | 1 | 6 | 7 |
|---|
| Thur | 44 | 17 | 61 |
|---|
| All | | 151 | 93 | 244 |
|---|
总结
本文主要讲解了pandas中分组聚合常用的GroupBy方法,这在数据分析中应用非常广泛。下一次我们将继续讲解时间序列。




















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









