






 本文利用Jieba、Word2Vec和NetworkX对《倚天屠龙记》进行自然语言处理,通过Word2Vec计算人物相似度,使用NetworkX构建人物关系图,展示了张无忌不同身份的关系网络。分析发现,Word2Vec和NetworkX结合能有效提取实体信息,节省阅读和分析时间。
本文利用Jieba、Word2Vec和NetworkX对《倚天屠龙记》进行自然语言处理,通过Word2Vec计算人物相似度,使用NetworkX构建人物关系图,展示了张无忌不同身份的关系网络。分析发现,Word2Vec和NetworkX结合能有效提取实体信息,节省阅读和分析时间。
最近在了解到,在机器学习中,自然语言处理是较大的一个分支。存在许多挑战。例如: 如何分词,识别实体关系,实体间关系,关系网络展示等。
我用Jieba + Word2vec + NetworkX 结合在一起,做了一次自然语言分析。语料是 倚天屠龙记。 之前也有很多人用金庸的武侠小说做分析和处理,希望带来一些不同的地方。截几张图来看看:

所有人物的相似图连接。
关系同上。展示形式为多中心结构
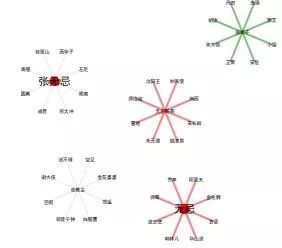
以张无忌的不同身份为中心的网络关系图。
这次分析的不一样之处主要是:
1、Word2Vec的相似度结果 - 作为后期社交网络权重
2、NetworkX中分析和展示
上面两个方法结合起来,可以大幅减少日常工作中阅读文章的时间。 采用机器学习,可以从头到尾半自动抽取文章中的实体信息,节约大量时间和成本。 在各种工作中都有利用的场景, 如果感兴趣的朋友,可以联系合作。
先来看看,用Word2Vec+NetworkX 可以发现什么。

一、分析结果
实体的不同属性(张无忌的总多马甲)
张无忌,无忌,张教主,无忌哥哥,张公子。同一个张无忌有多个身份,不同身份又和不同的人联系,有不一样的相似度。
先来看看图:
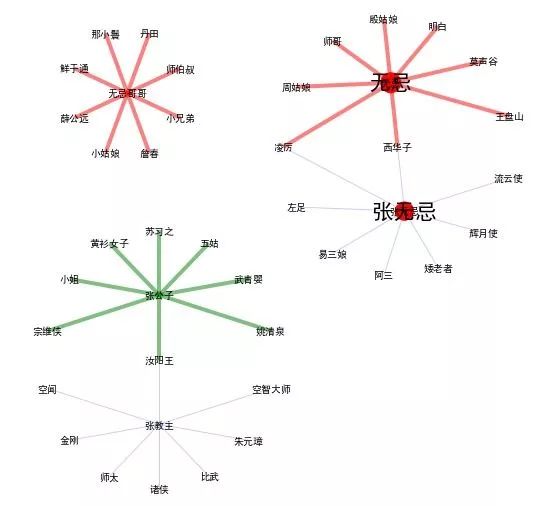
无忌哥哥是过于亲密的名字,一般不喊。好似和这个词相似度高的都是比较奇怪的角色。
无忌是关系熟了以后,平辈或者长辈可以称呼的名字。还有周姑娘,殷姑娘等
张无忌是通用的名字,人人可以称呼 和马甲联系密切。
张公子是礼貌尊称。 例如,黄衫女子,汝阳王等
张教主是头衔。既要尊重,也表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2638
2638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









