





最近由于一直在用Spark搞数据挖掘,花了些时间系统学习了一下Spark的MLlib机器学习库,它和sklearn有八九分相似,也是Estimator,Transformer,Pipeline那一套,各种fit,transform接口。sklearn有多好学,MLlib就有多好学,甚至MLlib还要更加简单一些,因为MLlib库中支持的功能相对更少一些,并且MLlib基于DataFrame数据比sklearn基于numpy array会更加直观一些。
那学了这个MLlib有啥子用呢?主要有以下三方面用处。
第一是对海量数据特征工程处理。如果有遇到需要对50G以上的数据进行Tf-idf特征提取,缺失值填充,特征筛选,最邻近查找等特征工程任务时,使用Pandas的同学可能要望洋兴叹了,这时候会使用Spark MLlib的同学就会露出迷之微笑。
第二是提供机器学习模型的候选baseline。众所周知,目前工业界应用最主流的机器学习模型是xgboost,lightgbm,以及深度学习那一套。遗憾的是,MLlib原生并不带xgboost和lightgbm,对深度学习的支持也不多。但MLlib提供非常丰富的基础模型诸如决策树,随机森林,梯度提升树,朴素贝叶斯等,这些简单易用的模型可以提供一个基本的baseline。如果生产要求不是非常高的话,baseline也是可以直接拿过来落地成产品的。
第三是为xgboost,深度学习等模型提供超参优化模型评估等支持。
通过引入XGBoost4J-Spark库,Spark上也是可以分布式跑xgboost的。通过引入mmlspark库,Spark上也是可以分布式跑lightgbm的,通过引入TensorflowOnSpark,Spark上也是可以分布式跑TensorFlow的。而MLlib的超参调优和模型评估等功能无疑可以很好地和这些牛逼闪闪的框架很好地协作起来。
以上是一些MLlib常用的使用场景。废话不多说了,让我们出发吧!
在Python与算法之美公众号后台回复关键字:"MLlib"获取本文全部源码。
一,MLlib基本介绍
MLlib是Spark的机器学习库,包括以下主要功能。
实用工具:线性代数,统计,数据处理等工具
特征工程:特征提取,特征转换,特征选择
常用算法:分类,回归,聚类,协同过滤,降维
模型优化:模型评估,参数优化。
MLlib库包括两个不同的部分。
spark.mllib 包含基于rdd的机器学习算法API,目前不再更新,在3.0版本后将会丢弃,不建议使用。
spark.ml 包含基于DataFrame的机器学习算法API,可以用来构建机器学习工作流Pipeline,推荐使用。
二,MLlib基本概念
DataFrame: MLlib中数据的存储形式,其列可以存储特征向量,标签,以及原始的文本,图像。
Transformer:转换器。具有transform方法。通过附加一个或多个列将一个DataFrame转换成另外一个DataFrame。
Estimator:估计器。具有fit方法。它接受一个DataFrame数据作为输入后经过训练,产生一个转换器Transformer。
Pipeline:流水线。具有setStages方法。顺序将多个Transformer和1个Estimator串联起来,得到一个流水线模型。
三,Pipeline流水线范例
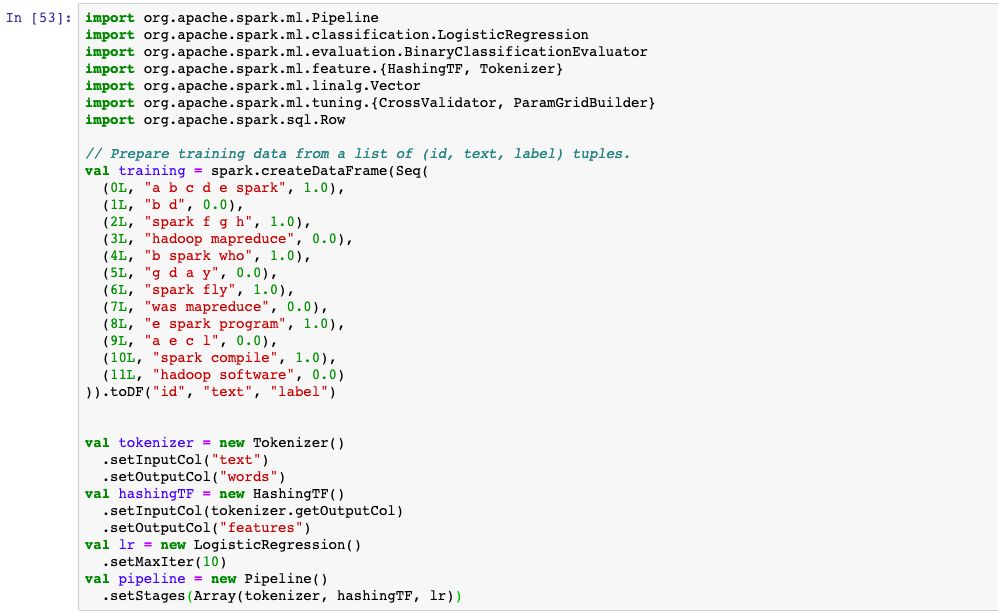
任务描述:用逻辑回归模型预测句子中是否包括”spark“这个单词。
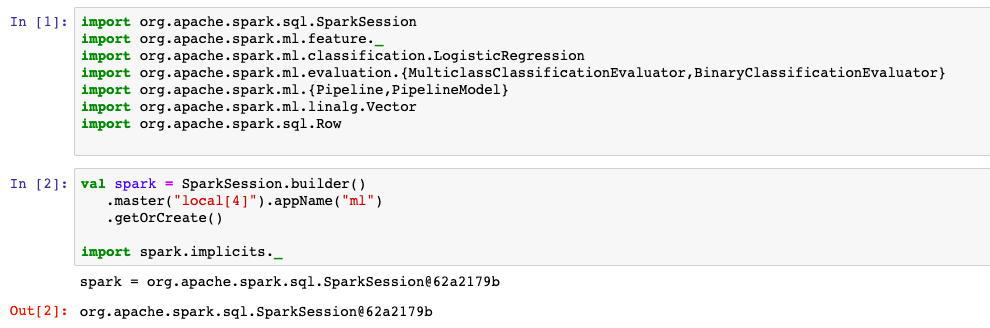
1,准备数据
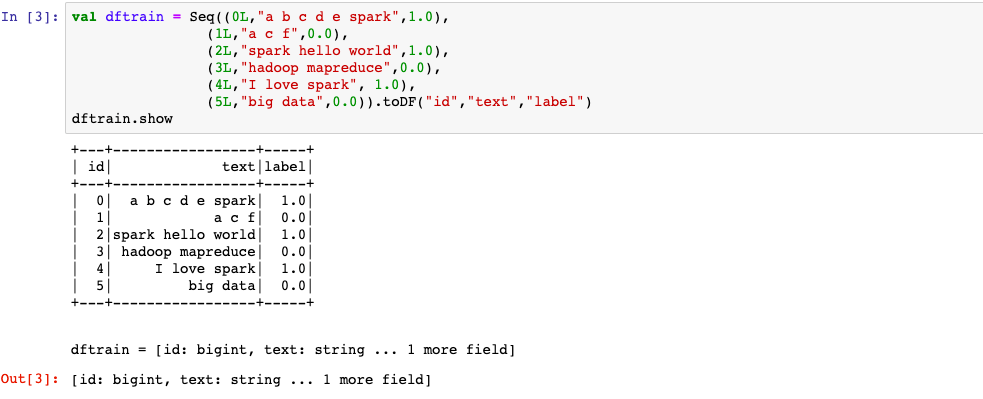
2,构建模型
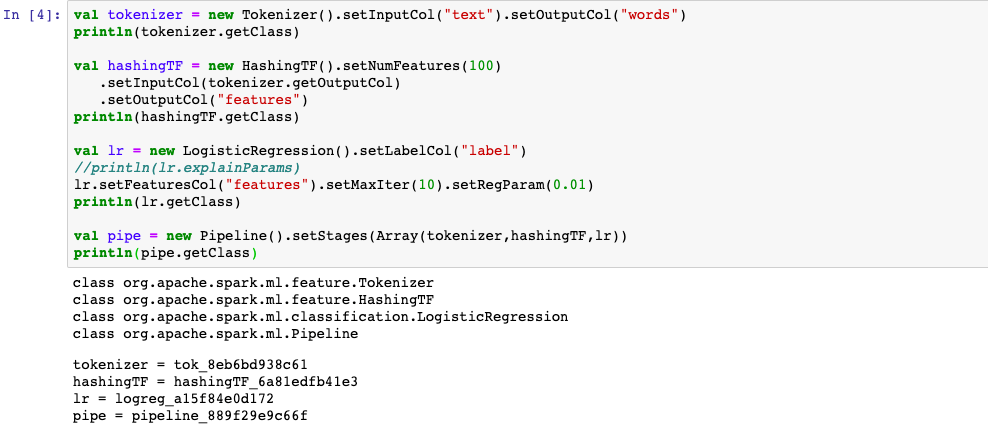
3,训练模型

4,使用模型
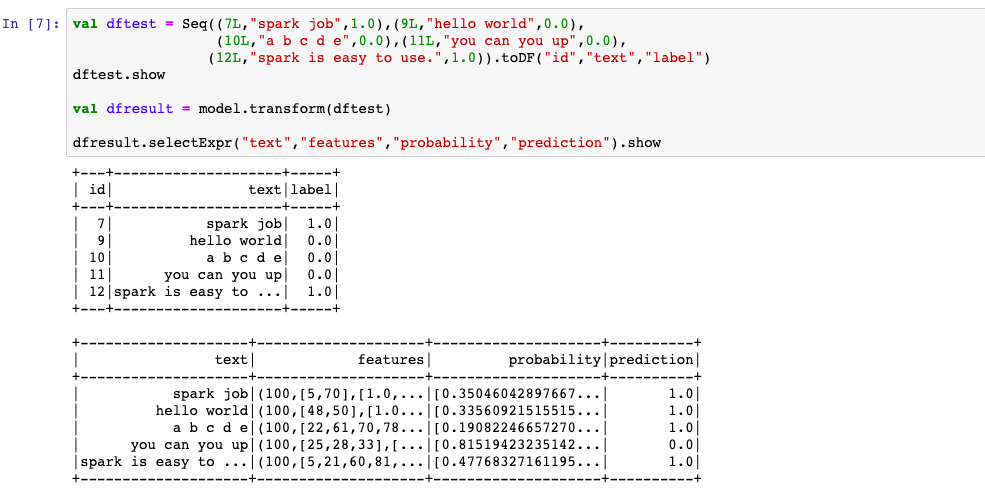
5,评估模型
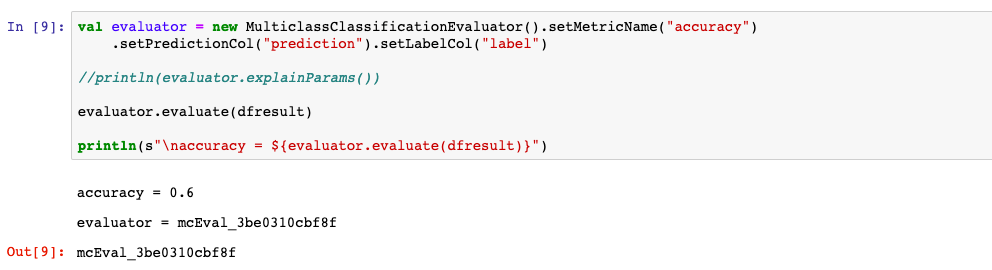
6,保存模型
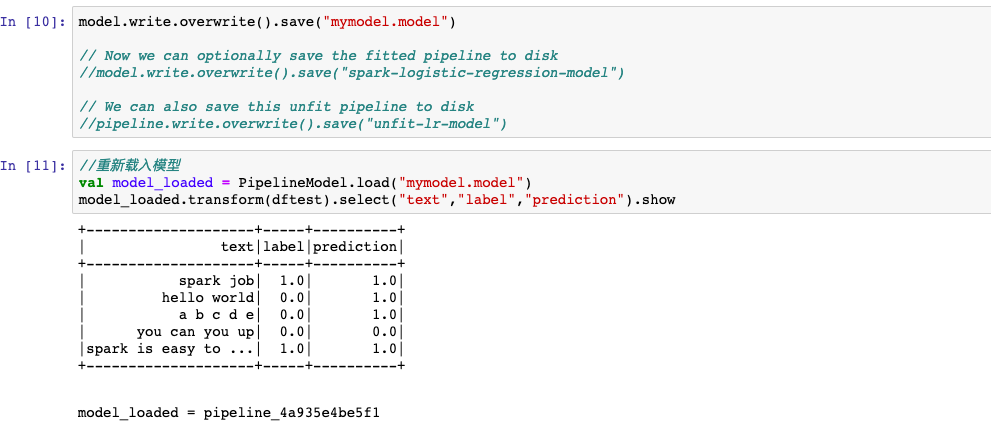
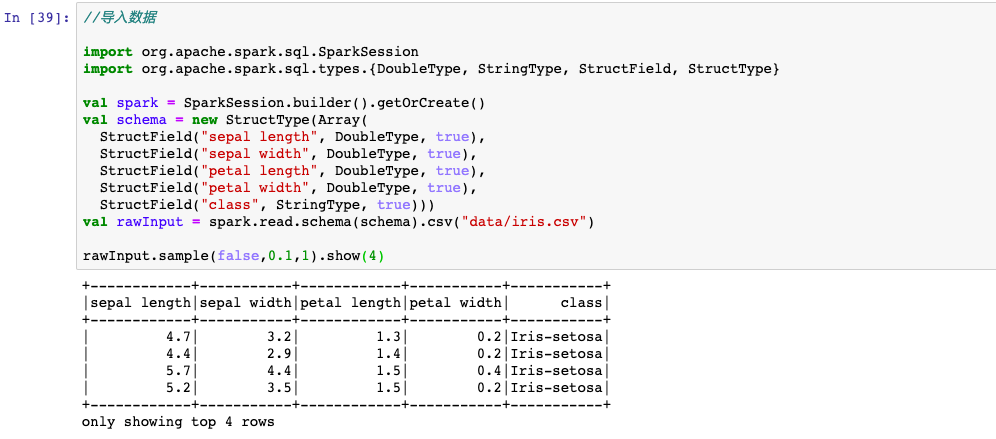
四,导入数据
可以使用spark.read导入csv,image,libsvm,txt等格式数据。
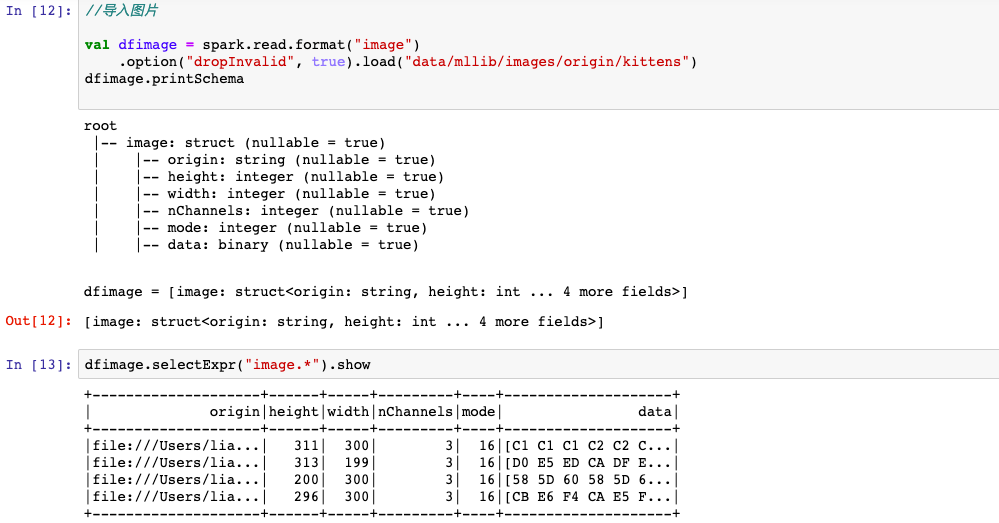
五,特征工程
spark的特征处理功能主要在 spark.ml.feature 模块中,包括以下一些功能。
特征提取:Tf-idf, Word2Vec, CountVectorizer, FeatureHasher
特征转换:OneHotEncoderEstimator, Normalizer, Imputer(缺失值填充), StandardScaler, MinMaxScaler, Tokenizer(构建词典),StopWordsRemover, SQLTransformer, Bucketizer, Interaction(交叉项), Binarizer(二值化), n-gram,……
特征选择:VectorSlicer(向量切片), RFormula, ChiSqSelector(卡方检验)
LSH转换:局部敏感哈希广泛用于海量数据中求最邻近,聚类等算法。
1,Word2Vec
Word2Vec可以使用浅层神经网络提取文本中词的相似语义信息。
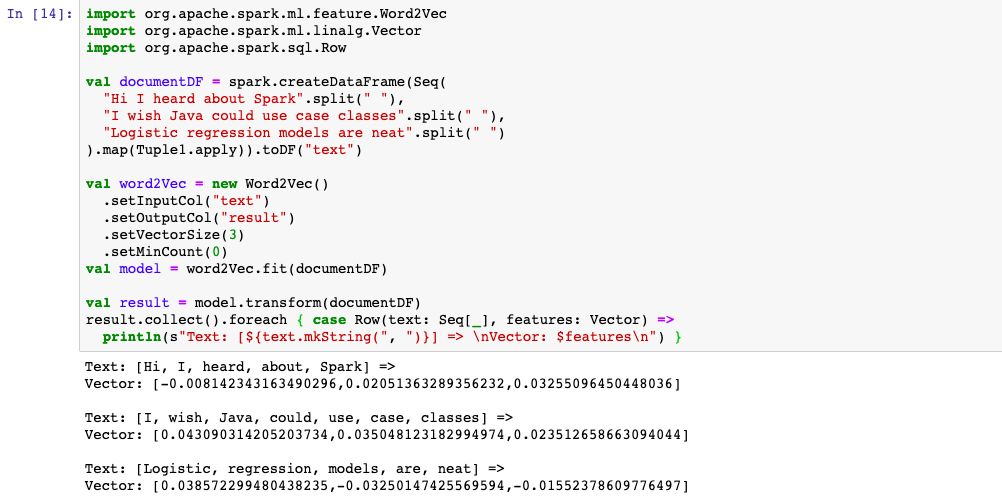
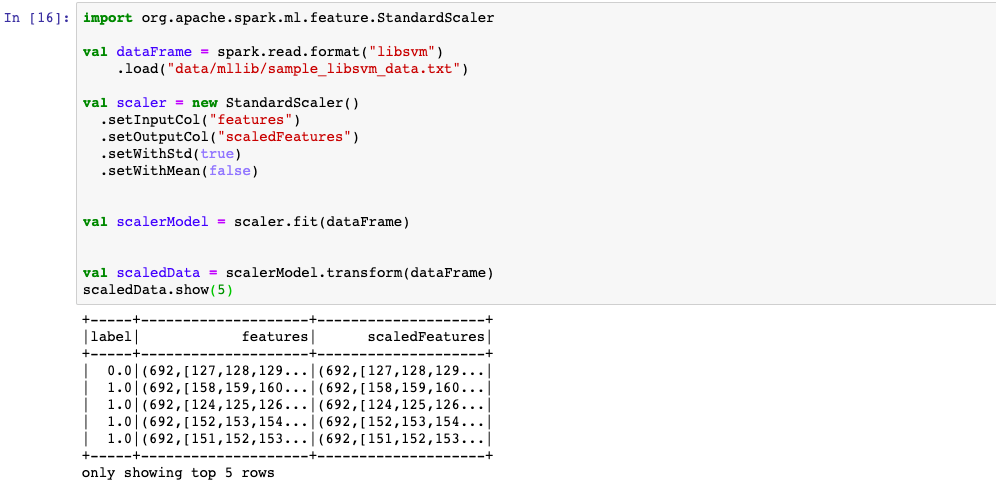
2,StandardScaler 正态标准化
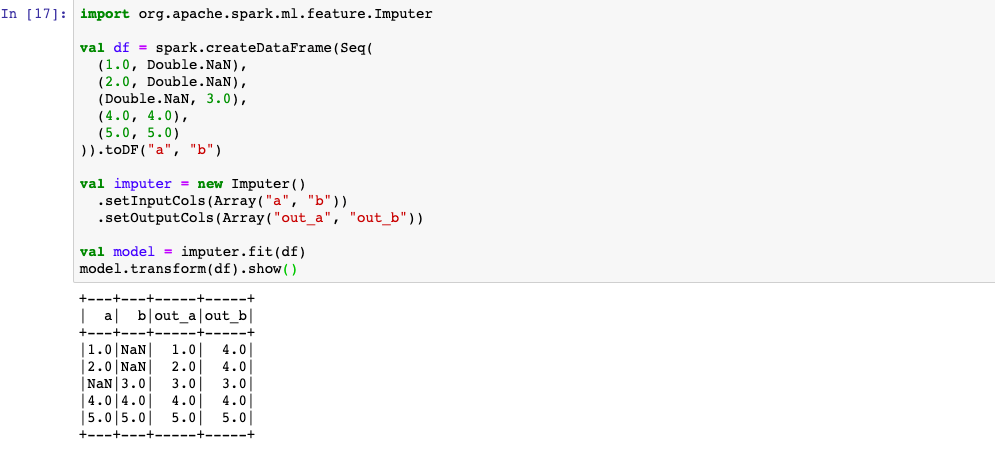
3,Imputer 缺失值填充
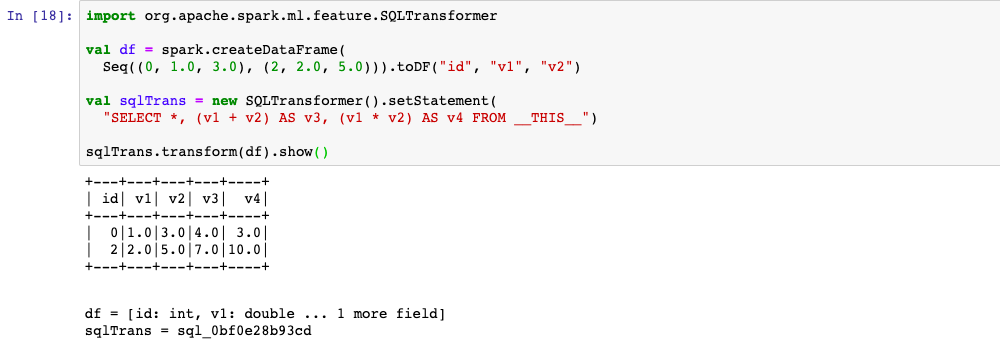
4,SQLTransformer
可以使用SQL语法将DataFrame进行转换,等效于注册表的作用。
但它可以用于Pipeline中作为Transformer。
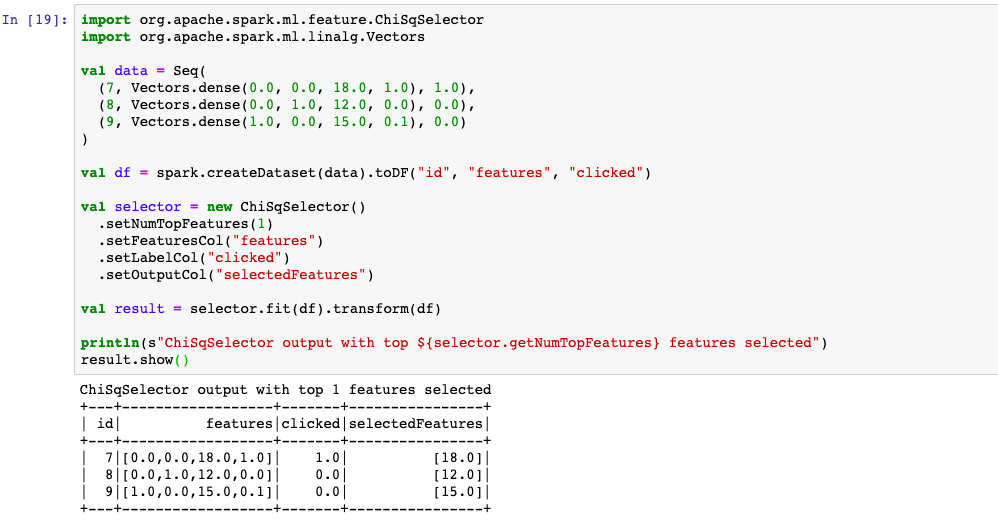
5,ChiSqSelector
当label是离散值时,ChiSqSelector选择器可以根据Chi2检验统计量筛选特征。
六,分类模型
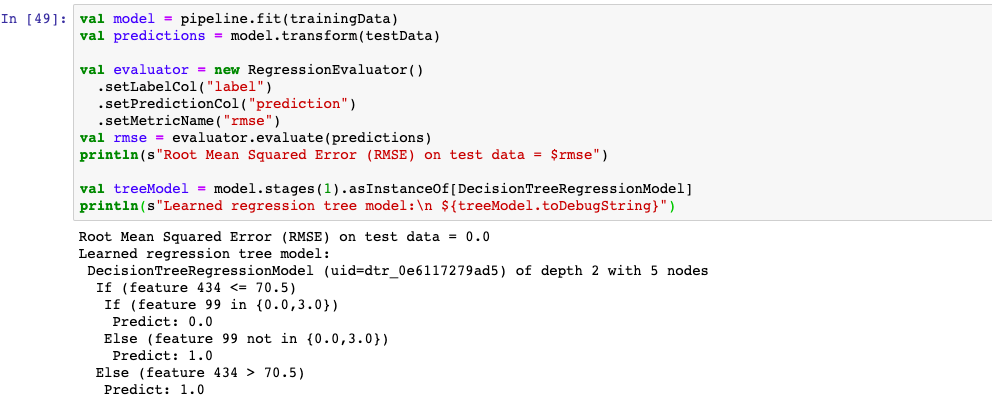
Mllib支持常见的机器学习分类模型:逻辑回归,SoftMax回归,决策树,随机森林,梯度提升树,线性支持向量机,朴素贝叶斯,One-Vs-Rest,以及多层感知机模型。这些模型的接口使用方法基本大同小异,下面仅仅列举常用的决策树作为示范。更多范例参见官方文档。
此外,通过导入引入XGBoost4J-Spark库,也可以在Spark上运行xgboost,此处也进行示范。
1,决策树
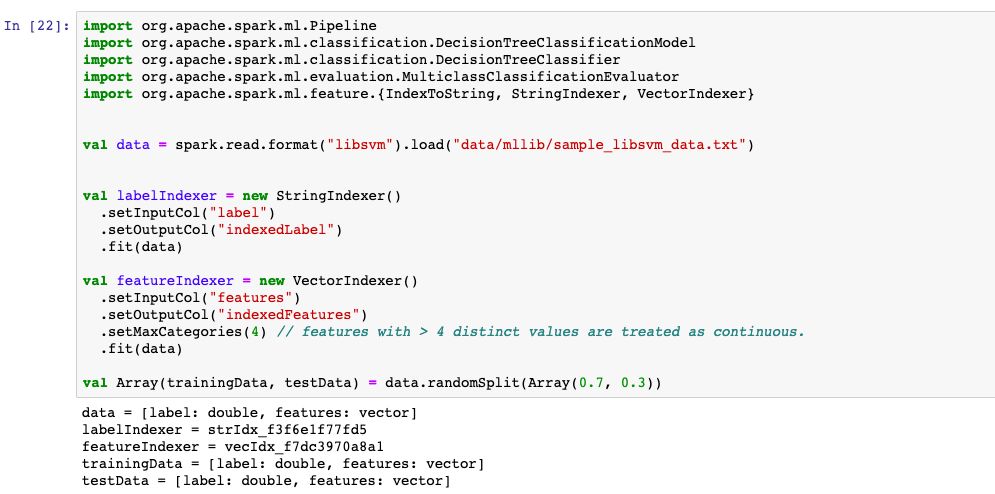
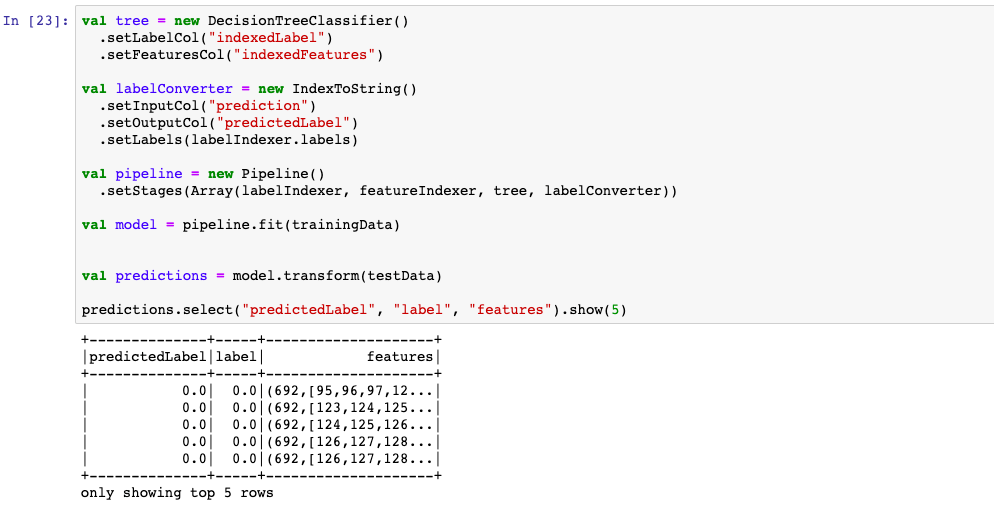
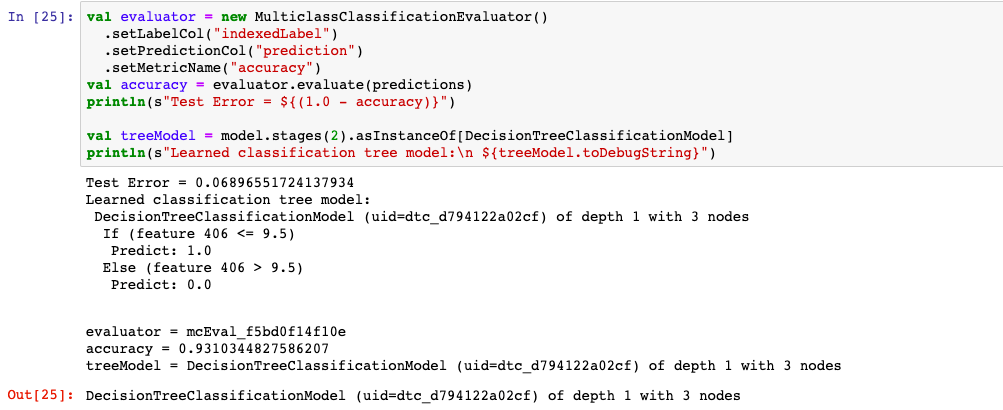
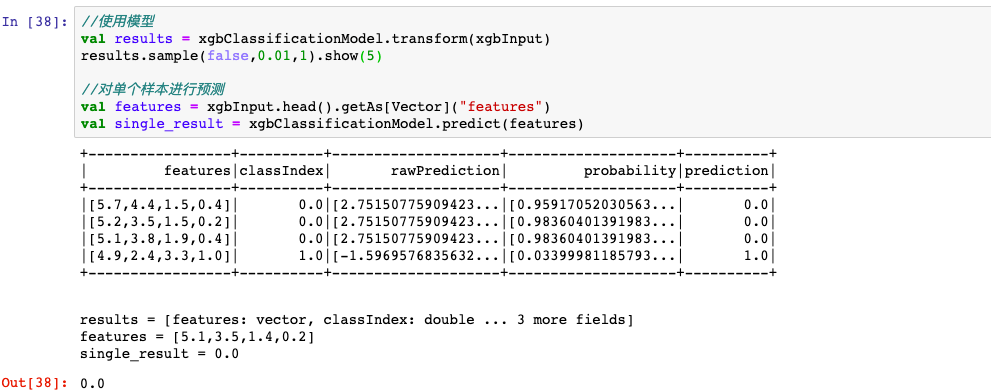
2,xgboost
spark也可以使用xgboost模型,既可以进行分布式训练,也可以进行分布式预测,支持各种参数设置和earlystopping。
支持模型保存,并且保存后的模型和Python等语言是可以相互调用的。
需要注意的是,输入xgboost的数据格式只能包含两列,features和label。
可以用spark.ml.feature.VectorAssembler将不同特征转换成一个 features向量。



七,回归模型
Mllib支持常见的回归模型,如线性回归,广义线性回归,决策树回归,随机森林回归,梯度提升树回归,生存回归,保序回归。
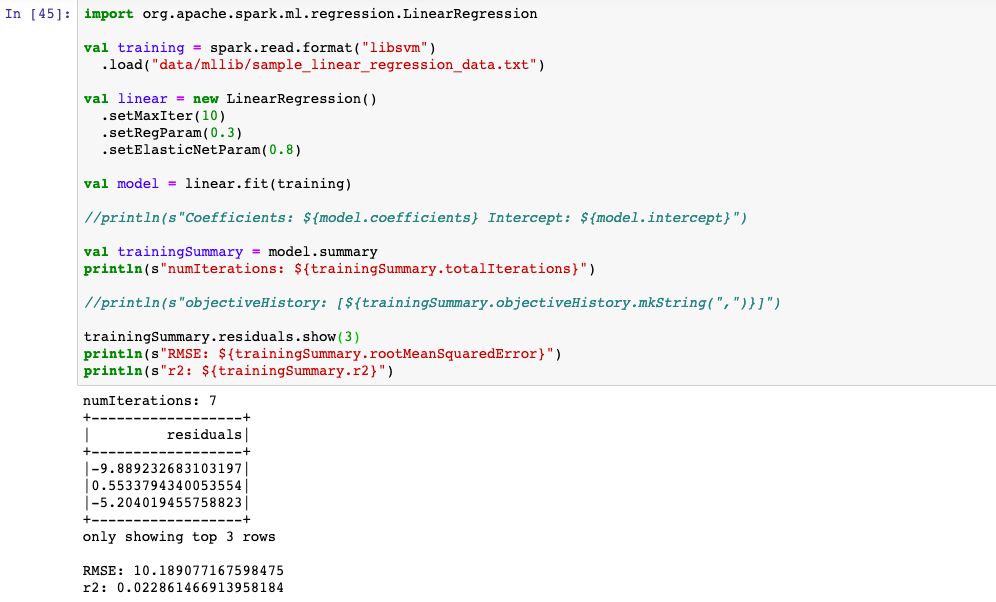
1,线性回归
2,决策树回归
八,聚类模型
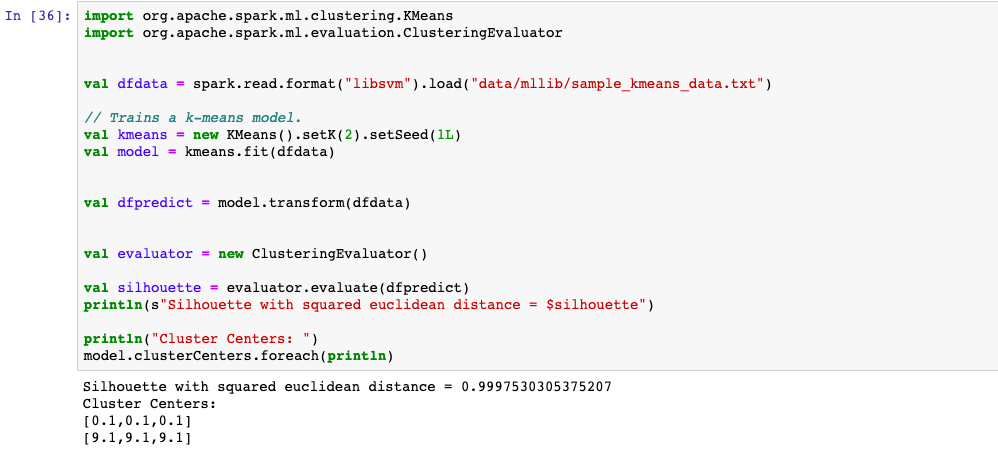
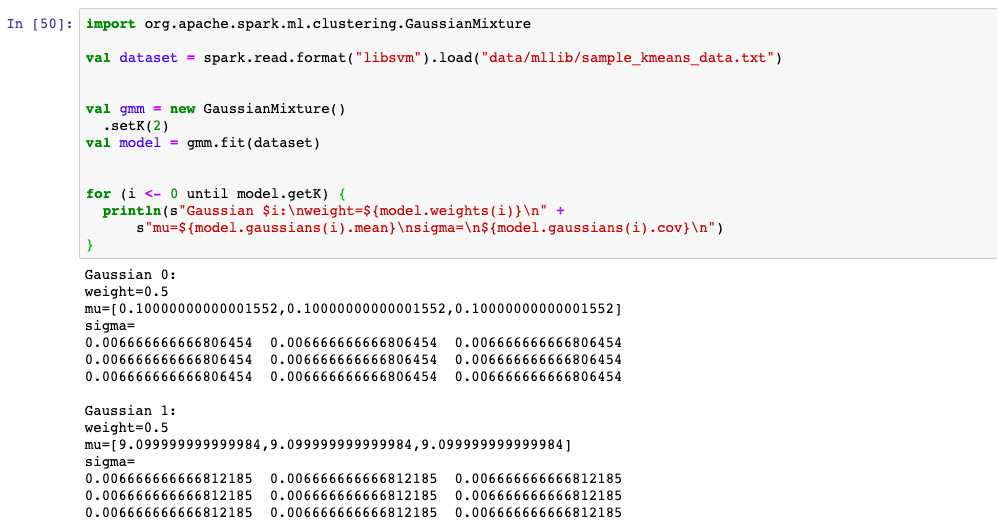
Mllib支持的聚类模型较少,主要有K均值聚类,高斯混合模型GMM,以及二分的K均值,隐含狄利克雷分布LDA模型等。
1,K均值聚类
2,高斯混合模型
九,降维模型
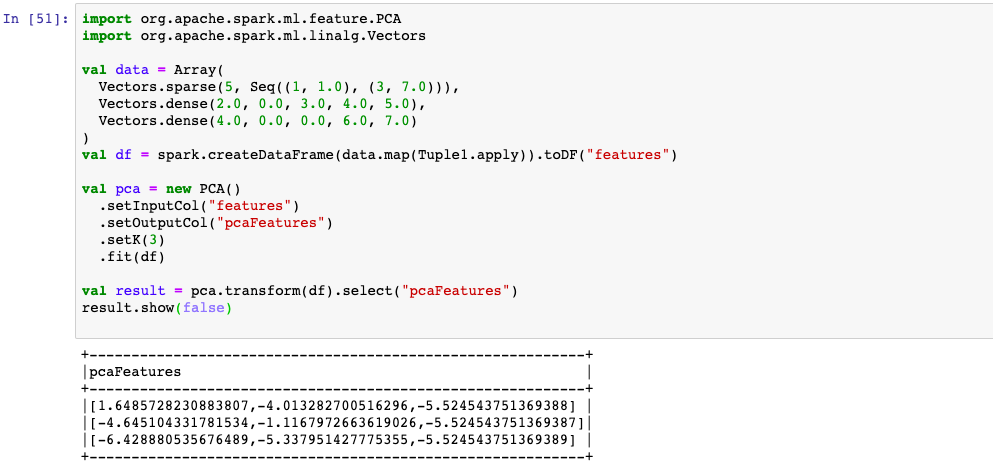
Mllib中支持的降维模型只有主成分分析PCA算法。这个模型在spark.ml.feature中,通常作为特征预处理的一种技巧使用。
1,PCA降维模型
十,模型优化
模型优化一般也称作模型选择(Model selection)或者超参调优(hyperparameter tuning)。
Mllib支持网格搜索方法进行超参调优,相关函数在spark.ml.tunning模块中。
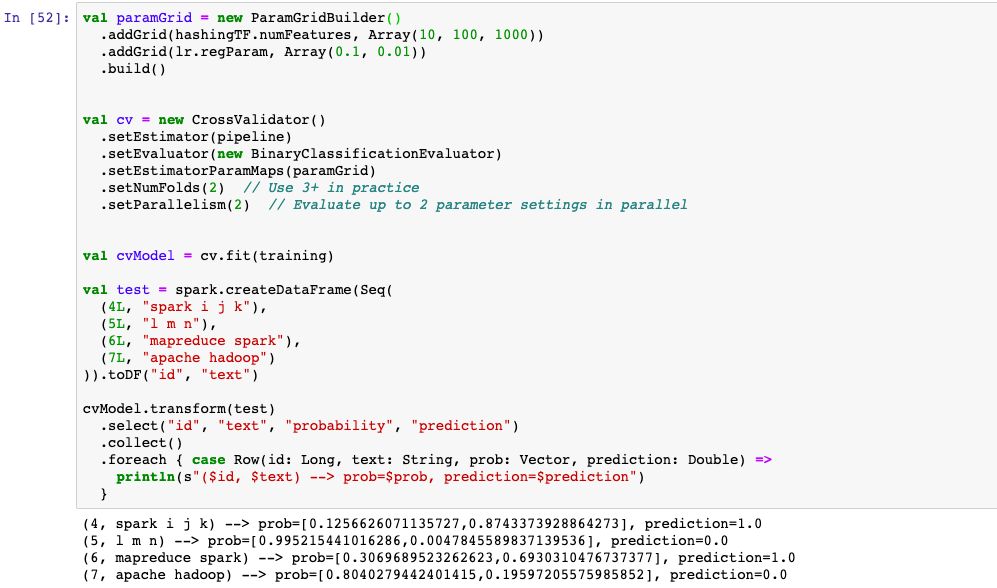
有两种使用网格搜索方法的模式,一种是通过交叉验证(cross-validation)方式进行使用,另外一种是通过留出法(hold-out)方法进行使用。
交叉验证模式使用的是K-fold交叉验证,将数据随机等分划分成K份,每次将一份作为验证集,其余作为训练集,根据K次验证集的平均结果来决定超参选取,计算成本较高,但是结果更加可靠。
而留出法只用将数据随机划分成训练集和验证集,仅根据验证集的单次结果决定超参选取,结果没有交叉验证可靠,但计算成本较低。
如果数据规模较大,一般选择留出法,如果数据规模较小,则应该选择交叉验证模式。
1,交叉验证模式
2,留出法模式

推荐阅读:
30分钟理解Spark的基本原理
3小时Scala入门
1小时入门Spark之RDD编程
2小时入门SparkSQL编程
7个小练习帮你打通SparkCore和SparkSQL编程任督二脉
公众号后台回复关键字:"MLlib"获取本文全部源码。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









