





本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例。本文的内容不包括如何编写高效的正则表达式、如何优化正则表达式,这些主题请查看其他教程。
注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
尊重作者的劳动,转载请注明作者及原文地址 >.
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程:
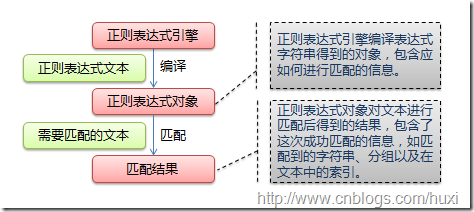
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:

1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern= re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match= pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# hello
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。 可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
1
2
3
4
a= re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b= re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
1
2
m= re.match(r'hello','hello world!')
print m.group()
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]): 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]): 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):返回(start(group), end(group))。
expand(template): 将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import re
m= re.match(r'(\w+) (\w+)(?P.*)','hello world!')
print "m.string:", m.string
print "m.re:", m.re
print "m.pos:", m.pos
print "m.endpos:", m.endpos
print "m.lastindex:", m.lastindex
print "m.lastgroup:", m.lastgroup
print "m.group(1,2):", m.group(1,2)
print "m.groups():", m.groups()
print "m.groupdict():", m.groupdict()
print "m.start(2):", m.start(2)
print "m.end(2):", m.end(2)
print "m.span(2):", m.span(2)
print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')
### output ###
# m.string: hello world!
# m.re: <_sre.SRE_Pattern object at 0x016E1A38>
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
1
2
3
4
5
6
7
8
9
10
11
12
13
import re
p= re.compile(r'(\w+) (\w+)(?P.*)', re.DOTALL)
print "p.pattern:", p.pattern
print "p.flags:", p.flags
print "p.groups:", p.groups
print "p.groupindex:", p.groupindex
### output ###
# p.pattern: (\w+) (\w+)(?P.*)
# p.flags: 16
# p.groups: 3
# p.groupindex: {'sign': 3}
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。 pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。 注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。 示例参见2.1小节。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# encoding: UTF-8
import re
# 将正则表达式编译成Pattern对象
pattern= re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match= pattern.search('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出 ###
# world
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
1
2
3
4
5
6
7
import re
p= re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):搜索string,以列表形式返回全部能匹配的子串。
1
2
3
4
5
6
7
import re
p= re.compile(r'\d+')
print p.findall('one1two2three3four4')
### output ###
# ['1', '2', '3', '4']
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
1
2
3
4
5
6
7
8
import re
p= re.compile(r'\d+')
for min p.finditer('one1two2three3four4'):
print m.group(),
### output ###
# 1 2 3 4
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):使用repl替换string中每一个匹配的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import re
p= re.compile(r'(\w+) (\w+)')
s= 'i say, hello world!'
print p.sub(r'\2 \1', s)
def func(m):
return m.group(1).title()+ ' ' + m.group(2).title()
print p.sub(func, s)
### output ###
# say i, world hello!
# I Say, Hello World!
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):返回 (sub(repl, string[, count]), 替换次数)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import re
p= re.compile(r'(\w+) (\w+)')
s= 'i say, hello world!'
print p.subn(r'\2 \1', s)
def func(m):
return m.group(1).title()+ ' ' + m.group(2).title()
print p.subn(func, s)
### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
正则表达式 re模块
hejiasheng 于 2014-02-10 07:00:17+00:00 更新访问次数:1547
Regular Expression、regex或regexp,(缩写为RE) 是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
计算机里处理文本和数据是非常重要的事情。
一般匹配规则:¶
1 字符串匹配
"abcd" 这种是没有特殊规则,就是完全按照 字符去匹配。 例如:"hello,abcd" 可以匹配。 "hello,abc" 匹配不上。
>>>importre
>>>re.search("abcd","hello,abcd")
<_sre.SRE_Match objectat 0x994e2c0>
>>>re.search("abcd","hello,abdc")
2 选择匹配 gray|grey ,“gray” 和"grey " 都能匹配上。 或者用 gr(a|e)y 规则来匹配后面2个单词 "gray","grey"。
>>>printre.search("gray|grey","gray")
<_sre.SRE_Match objectat 0x994e2c0>
>>>printre.search("gray|grey","grey")
<_sre.SRE_Match objectat 0x994e2c0>
>>>printre.search("gray|grey","grcy")
None
>>>printre.search("gr(a|e)y","gray")
<_sre.SRE_Match objectat 0xb77268a0>
3 数量限定
‘+’加号代表前面的字符必须至少出现一次。(1次、或多次)。例如,“goo+gle”可以匹配google、gooogle、goooogle等;
?问号代表前面的字符最多只可以出现一次。(0次、或1次)。例如,“colou?r”可以匹配color或者colour;
‘*’星号代表前面的字符可以不出现,也可以出现一次或者多次。(0次、或1次、或多次)。例如,“0*42”可以匹配42、042、0042、00042等。>>>re.search("goo+gle","google")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search("goo+gle","gogle")
>>>re.search("goo+gle","goooogle")
<_sre.SRE_Match objectat 0x994e2c0>
“?” 例子
>>>re.search("colou?r","color")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search("colou?r","colour")
<_sre.SRE_Match objectat 0x994e2c0>
>>>re.search("colou?r","colouur")
>>>#对比 "+"
>>>re.search("colou+r","colouur")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search("colou+r","color")
“*” 例子:
>>>re.search("goo*gle","google")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search("goo*gle","gooogle")
<_sre.SRE_Match objectat 0x994e2c0>
4 [...] 括号里面包含的任意字符
b[aeou]d 匹配"bad","bed","bod","bud"
>>>re.search("b[aeoud]d","bad")
<_sre.SRE_Match objectat 0x994e2c0>
>>>re.search("b[aeoud]d","bed")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search("b[aeoud]d","bud")
<_sre.SRE_Match objectat 0x994e2c0>
>>>re.search("b[aeoud]d","bcd")
>>>re.search("b[aeoud]d","baed")
匹配 [0-9],[0-9a-z]
>>>re.search('b[0-9a-z]d',"b12d")
>>>re.search('b[0-9a-z]d',"b1d")
<_sre.SRE_Match objectat 0xb7717e20>
>>>re.search('b[0-9a-z]d',"bad")
<_sre.SRE_Match objectat 0x994e2c0>
5 多字符匹配 {n}
[0-9]{3} : []以内的字母、数字在后面字符串中出现的次数。 “hd543”,符合规则。 "hello32rew",不符合规则。
>>>re.search("[0-9]{3}","hd23")
>>>re.search("[0-9]{3}","hd232")
<_sre.SRE_Match objectat 0x92ec2c0>
>>>re.search("[0-9]{3}","hd234")
<_sre.SRE_Match objectat 0xb77bee20>
>>>
>>>re.search("[0-9]{4}","hd234")
>>>re.search("[0-9d]{4}","hd234")
<_sre.SRE_Match objectat 0x92ec2c0>
6. []{m,n}, 按照[]内规则匹配 m---n之间个数,m必须小于n。
7 "." 匹配任何1个字符。
>>>importre
>>>re.search('b.b',"beb")
<_sre.SRE_Match objectat 0xb7280170>
>>>re.search('b.b',"bab")
<_sre.SRE_Match objectat 0xb7280368>
>>>re.search('b.b',"badb")
>>>re.search('b..b',"badb")
<_sre.SRE_Match objectat 0xb7280170>
>>>
8 “^” 匹配字符串的开始
>>>re.search('^bad',"badb")
<_sre.SRE_Match objectat 0xb7280368>
>>>re.search('^ad',"badb")
>>>re.search('^.ad',"badb")
<_sre.SRE_Match objectat 0xb7280170>
>>>re.search('^..ad',"badb")
>>>
9
"$" 匹配字符串的结尾
>>>re.search('adb$',"badb")
<_sre.SRE_Match objectat 0xb7280170>
>>>re.search('.db$',"badb")
<_sre.SRE_Match objectat 0xb7280368>
10
'\d'匹配数字
‘\D' 匹配非数字>>>re.search('\d',"badec3b2v432")
<_sre.SRE_Match objectat 0xb7280368>
>>>re.search('\D',"badec3b2v432")
<_sre.SRE_Match objectat 0xb7280170>
>>>
11
'\w'匹配任意数字和字母
'\W'非数字和字母
12
'\s'匹配任意空白字符,相当于[\t\n\r\f\v]
\S 匹配任意非空白字符,相当于[^\t\n\r\f\v]
使用方法¶
A)
compiled_pattern =re.compile(pattern)
result =compiled_pattern.match(string)
B)
result =re.match(pattern,string)
pattern,就是上面提到的规则。
除了match,以为还有几个函数,我们一起做说明: match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是只报告从位置 0 开始的匹配情况。
search() 函数是扫描整个字符串来查找匹配。如果想要搜索整个字符串来寻找匹配,应当用 search()。 但search 返回第一个匹配的字符串。
split() 将字符串按照规则分成list。如果按照规则里面找不到,就不分割,返回原字符串。
>>>re.split(":","test:test1:test2")
['test','test1','test2']
findall() 函数搜索整个字符串,返回所有匹配项。返回一个list。
sub() 函数 查找并替换
>>>re.sub("one","num","one world, on dream",1)
'num world, on dream'
>>>re.sub("one","num","one world, one dream",1)
'num world, one dream'
>>>re.sub("one","num","one world, one dream",2)
'num world, num dream'
>>>
可以:
>>>p =re.compile('(one|two|three)')
>>>p.sub('num','one word two words three words')
'num word num words num words'
匹配网址的实例:
#coding=utf-8
importre
urls=r'fdsa... '
s =re.findall("",urls)
prints
非贪婪匹配 + 后结束标记
all_buf =re.findall(r' ]',buf)
forn inall_buf:
printn
简单匹配 @ 后面的用户正则
#s = "@fdsa;1232"
s ="fdsfds@fdsa你好.1, 232"
a =re.findall("""@(.*?)(?=[;,| '".?])""",s)
print a[0]
如果@后面没有任何特殊符号,就结束了匹配方法,加了$:
>>>a=re.compile("@(.*?)(?=[ ,'$]|$)")
>>>printa.findall("@sina @abd, @fds")
正则表达式的元字符有. ^ $ * ? { [ ] | ( ) .表示任意字符 []用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字符集,对于字符集中的字符可以理解成或的关系。 ^ 如果放在字符串的开头,则表示取非的意思。[^5]表示除了5之外的其他字符。而如果^不在字符串的开头,则表示它本身。
具有重复功能的元字符: * 对于前一个字符重复0到无穷次 对于前一个字符重复1到无穷次 ?对于前一个字符重复0到1次 {m,n} 对于前一个字符重复次数在为m到n次,其中,{0,} = *,{1,} = , {0,1} = ? {m} 对于前一个字符重复m次
\d 匹配任何十进制数;它相当于类 [0-9]。 \D 匹配任何非数字字符;它相当于类 [^0-9]。 \s 匹配任何空白字符;它相当于类 [ fv]。 \S 匹配任何非空白字符;它相当于类 [^ fv]。 \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。
正则表达式(可以称为REs,regex,regex pattens)是一个小巧的,高度专业化的编程语言,它内嵌于python开发语言中,可通过re模块使用。正则表达式的
pattern可以被编译成一系列的字节码,然后用C编写的引擎执行。下面简单介绍下正则表达式的语法
正则表达式包含一个元字符(metacharacter)的列表,列表值如下: . ^ $ * + ? { [ ] \ | ( )
1.元字符([ ]),它用来指定一个character class。所谓character classes就是你想要匹配的字符(character)的集合.字符(character)可以单个的列出,也可以通过"-"来分隔两个字符来表示一 个范围。例如,[abc]匹配a,b或者c当中任意一个字符,[abc]也可以用字符区间来表示---[a-c].如果想要匹配单个大写字母,你可以用 [A-Z]。
元字符(metacharacters)在character class里面不起作用,如[akm$]将匹配"a","k","m","$"中的任意一个字符。在这里元字符(metacharacter)"$"就是一个普通字符。
2.元字符[^]. 你可以用补集来匹配不在区间范围内的字符。其做法是把"^"作为类别的首个字符;其它地方的"^"只会简单匹配 "^"字符本身。例如,[^5] 将匹配除 "5" 之外的任意字符。同时,在[ ]外,元字符^表示匹配字符串的开始,如"^ab+"表示以ab开头的字符串。
举例验证,
>>> m=re.search("^ab+","asdfabbbb")
>>> print m
None
>>> m=re.search("ab+","asdfabbbb")
>>> print m
<_sre.SRE_Match object at 0x011B1988>
>>> print m.group()
abbbb
上例不能用re.match,因为match匹配字符串的开始,我们无法验证元字符"^"是否代表字符串的开始位置。
>>> m=re.match("^ab+","asdfabbbb")
>>> print m
None
>>> m=re.match("ab+","asdfabbbb")
>>> print m
None
#验证在元字符[]中,"^"在不同位置所代表的意义。
>>> re.search("[^abc]","abcd") #"^"在首字符表示取反,即abc之外的任意字符。
<_sre.SRE_Match object at 0x011B19F8>
>>> m=re.search("[^abc]","abcd")
>>> m.group()
'd'
>>> m=re.search("[abc^]","^") #如果"^"在[ ]中不是首字符,那么那就是一个普通字符
>>> m.group()
'^'
不过对于元字符”^”有这么一个疑问.官方文档http://docs.python.org/library/re.html有关元字符”^”有这么一句话,Matches the start
of the string, and in MULTILINE mode also matches immediately after each newline.
我理解的是”^”匹配字符串的开始,在MULTILINE模式下,也匹配换行符之后。
>>> m=re.search("^a\w+","abcdfa\na1b2c3")
>>> m.group()
'abcdfa'
>>> m=re.search("^a\w+","abcdfa\na1b2c3",re.MULTILINE),
>>> m.group() #
'abcdfa'
我 认为flag设定为re.MULTILINE,根据上面那段话,他也应该匹配换行符之后,所以应该有m.group应该有"a1b2c3",但是结果没 有,用findall来尝试,可以找到结果。所以这里我理解之所以group里面没有,是因为search和match方法是匹配到就返回,而不是去匹配 所有。
>>> m=re.findall("^a\w+","abcdfa\na1b2c3",re.MULTILINE)
>>> m
['abcdfa', 'a1b2c3']
3. 元字符(\),元字符backslash。做为 Python 中的字符串字母,反斜杠后面可以加不同的字符以表示不同特殊意义。
它也可以用于取消所有的元字符,这样你 就可以在模式中匹配它们了。例如,如果你需要匹配字符 "[" 或 "\",你可以在它们之前用反斜杠来取消它们的特殊意义: \[ 或 \\
4。元字符($)匹配字符串的结尾或者字符串结尾的换行之前。(在MULTILINE模式下,"$"也匹配换行之前)
正则表达式"foo"既匹配"foo"又匹配"foobar",而"foo$"仅仅匹配"foo".
>>> re.findall("foo.$","foo1\nfoo2\n")#匹配字符串的结尾的换行符之前。
['foo2']
>>> re.findall("foo.$","foo1\nfoo2\n",re.MULTILINE)
['foo1', 'foo2']
>>> m=re.search("foo.$","foo1\nfoo2\n")
>>> m
<_sre.SRE_Match object at 0x00A27170>
>>> m.group()
'foo2'
>>> m=re.search("foo.$","foo1\nfoo2\n",re.MULTILINE)
>>> m.group()
'foo1'
看来re.MULTILINE对$的影响还是蛮大的。
5.元字符(*),匹配0个或多个
6.元字符(?),匹配一个或者0个
7.元字符(+), 匹配一个或者多个
8,元字符(|), 表示"或",如A|B,其中A,B为正则表达式,表示匹配A或者B
9.元字符({})
{m},用来表示前面正则表达式的m次copy,如"a{5}",表示匹配5个”a”,即"aaaaa"
>>> re.findall("a{5}","aaaaaaaaaa")
['aaaaa', 'aaaaa']
>>> re.findall("a{5}","aaaaaaaaa")
['aaaaa']
{m.n}用来表示前面正则表达式的m到n次copy,尝试匹配尽可能多的copy。
>>> re.findall("a{2,4}","aaaaaaaa")
['aaaa', 'aaaa']
通过上面的例子,可以看到{m,n},正则表达式优先匹配n,而不是m,因为结果不是["aa","aa","aa","aa"]
>>> re.findall("a{2}","aaaaaaaa")
['aa', 'aa', 'aa', 'aa']
{m,n}? 用来表示前面正则表达式的m到n次copy,尝试匹配尽可能少的copy
>>> re.findall("a{2,4}?","aaaaaaaa")
['aa', 'aa', 'aa', 'aa']
10。元字符( "( )" ),用来表示一个group的开始和结束。
比较常用的有(REs),(?PREs),这是无名称的组和有名称的group,有名称的group,可以通过matchObject.group(name)
获取匹配的group,而无名称的group可以通过从1开始的group序号来获取匹配的组,如matchObject.group(1)。具体应用将在下面的group()方法中举例讲解
11.元字符(.)
元字符“.”在默认模式下,匹配除换行符外的所有字符。在DOTALL模式下,匹配所有字符,包括换行符。
>>> import re
>>> re.match(".","\n")
>>> m=re.match(".","\n")
>>> print m
None
>>> m=re.match(".","\n",re.DOTALL)
>>> print m
<_sre.SRE_Match object at 0x00C2CE20>
>>> m.group()
'\n'
下面我们首先来看一下Match Object对象拥有的方法,下面是常用的几个方法的简单介绍
1.group([group1,…])
返回匹配到的一个或者多个子组。如果是一个参数,那么结果就是一个字符串,如果是多个参数,那么结果就是一个参数一个item的元组。group1的默 认值为0(将返回所有的匹配值).如果groupN参数为0,相对应的返回值就是全部匹配的字符串,如果group1的值是[1…99]范围之内的,那么 将匹配对应括号组的字符串。如果组号是负的或者比pattern中定义的组号大,那么将抛出IndexError异常。如果pattern没有匹配到,但 是group匹配到了,那么group的值也为None。如果一个pattern可以匹配多个,那么组对应的是样式匹配的最后一个。另外,子组是根据括号 从左向右来进行区分的。
>>> m=re.match("(\w+) (\w+)","abcd efgh, chaj")
>>> m.group() # 匹配全部
'abcd efgh'
>>> m.group(1) # 第一个括号的子组.
'abcd'
>>> m.group(2)
'efgh'
>>> m.group(1,2) # 多个参数返回一个元组
('abcd', 'efgh')
>>> m=re.match("(?P\w+) (?P\w+)","sam lee")
>>> m.group("first_name") #使用group获取含有name的子组
'sam'
>>> m.group("last_name")
'lee'
下面把括号去掉
>>> m=re.match("\w+ \w+","abcd efgh, chaj")
>>> m.group()
'abcd efgh'
>>> m.group(1)
Traceback (most recent call last):
File "", line 1, in
m.group(1)
IndexError: no such group
If a group matches multiple times, only the last match is accessible:
如果一个组匹配多个,那么仅仅返回匹配的最后一个的。
>>> m=re.match(r"(..)+","a1b2c3")
>>> m.group(1)
'c3'
>>> m.group()
'a1b2c3'
Group的默认值为0,返回正则表达式pattern匹配到的字符串
>>> s="afkak1aafal12345adadsfa"
>>> pattern=r"(\d)\w+(\d{2})\w"
>>> m=re.match(pattern,s)
>>> print m
None
>>> m=re.search(pattern,s)
>>> m
<_sre.SRE_Match object at 0x00C2FDA0>
>>> m.group()
'1aafal12345a'
>>> m.group(1)
'1'
>>> m.group(2)
'45'
>>> m.group(1,2,0)
('1', '45', '1aafal12345a')
2。groups([default])
返回一个包含所有子组的元组。Default是用来设置没有匹配到组的默认值的。Default默认是"None”,
>>> m=re.match("(\d+)\.(\d+)","23.123")
>>> m.groups()
('23', '123')
>>> m=re.match("(\d+)\.?(\d+)?","24") #这里的第二个\d没有匹配到,使用默认值"None"
>>> m.groups()
('24', None)
>>> m.groups("0")
('24', '0')
3.groupdict([default])
返回匹配到的所有命名子组的字典。Key是name值,value是匹配到的值。参数default是没有匹配到的子组的默认值。这里与groups()方法的参数是一样的。默认值为None
>>> m=re.match("(\w+) (\w+)","hello world")
>>> m.groupdict()
{}
>>> m=re.match("(?P\w+) (?P\w+)","hello world")
>>> m.groupdict()
{'secode': 'world', 'first': 'hello'}
通过上例可以看出,groupdict()对没有name的子组不起作用
正则表达式对象
re.search(string[, pos[, endpos]])
扫描字符串string,查找与正则表达式匹配的位置。如果找到一个匹配就返回一个MatchObject对象(并不会匹配所有的)。如果没有找到那么返回None。
第二个参数表示从字符串的那个位置开始,默认是0
第三个参数endpos限定字符串最远被查找到哪里。默认值就是字符串的长度。.
>>> m=re.search("abcd", '1abcd2abcd')
>>> m.group() #找到即返回一个match object,然后根据该对象的方法,查找匹配到的结果。
'abcd'
>>> m.start()
1
>>> m.end()
5
>>> re.findall("abcd","1abcd2abcd")
['abcd', 'abcd']
re.split(pattern, string[, maxsplit=0, flags=0])
用pattern来拆分string。如果pattern有含有括号,那么在pattern中所有的组也会返回。
>>> re.split("\W+","words,words,works",1)
['words', 'words,works']
>>> re.split("[a-z]","0A3b9z",re.IGNORECASE)
['0A3', '9', '']
>>> re.split("[a-z]+","0A3b9z",re.IGNORECASE)
['0A3', '9', '']
>>> re.split("[a-zA-Z]+","0A3b9z")
['0', '3', '9', '']
>>> re.split('[a-f]+', '0a3B9', re.IGNORECASE)#re.IGNORECASE用来忽略pattern中的大小写。
['0', '3B9']
如果在split的时候捕获了组,并且匹配字符串的开始,那么返回的结果将会以一个空串开始。
>>> re.split('(\W+)', '...words, words...')
['', '...', 'words', ', ', 'words', '...', '']
>>> re.split('(\W+)', 'words, words...')
['words', ', ', 'words', '...', '']
re.findall(pattern, string[, flags])
以list的形式返回string中所有与pattern匹配的不重叠的字符串。String从左向右扫描,匹配的返回结果也是以这个顺序。
Return all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found. If one or more groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group. Empty matches are included in the result unless they touch the beginning of another match.
>>> re.findall('(\W+)', 'words, words...')
[', ', '...']
>>> re.findall('(\W+)d', 'words, words...d')
['...']
>>> re.findall('(\W+)d', '...dwords, words...d')
['...', '...']
re.finditer(pattern, string[, flags])
与findall类似,只不过是返回list,而是返回了一个叠代器
我们来看一个sub和subn的例子
>>> re.sub("\d","abc1def2hijk","RE")
'RE'
>>> x=re.sub("\d","abc1def2hijk","RE")
>>> x
'RE'
>>> re.sub("\d","RE","abc1def2hijk",)
'abcREdefREhijk'
>>> re.subn("\d","RE","abc1def2hijk",)
('abcREdefREhijk', 2)
通过例子我们可以看出sub和subn的差别:sub返回替换后的字符串,而subn返回由替换后的字符串以及替换的个数组成的元组。
re.sub(pattern, repl, string[, count, flags])
用repl替换字符串string中的pattern。如果pattern没有匹配到,那么返回的字符串没有变化]。Repl可以是一个字符串,也可以是 一个function。如果是字符串,如果repl是个方法/函数。对于所有的pattern匹配到。他都回调用这个方法/函数。这个函数和方法使用单个 match object作为参数,然后返回替换后的字符串。下面是官网提供的例子:
>>> def dashrepl(matchobj):
... if matchobj.group(0) == '-': return ' '
... else: retu















 6753
6753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









