






高斯混合模型(GMM)是一种常用的聚类模型,通常我们利用最大期望算法(EM)对高斯混合模型中的参数进行估计。
本教程中,我们自己动手一步步实现高斯混合模型。GMM以及EM的完整python代码请看这里。

高斯混合模型(Gaussian Mixture Model,GMM)是一种软聚类模型。 GMM也可以看作是K-means的推广,因为GMM不仅是考虑到了数据分布的均值,也考虑到了协方差。和K-means一样,我们需要提前确定簇的个数。
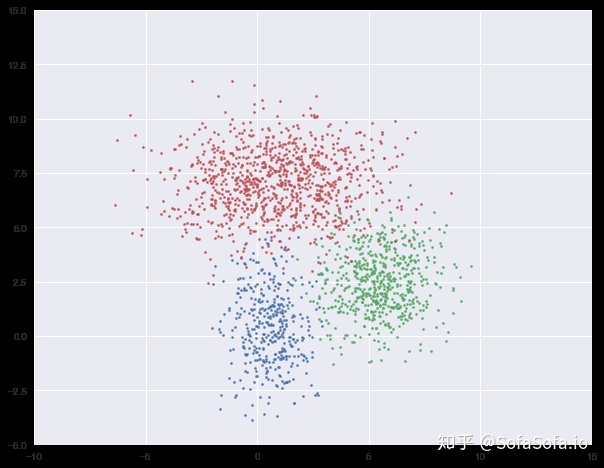
GMM的基本假设为数据是由几个不同的高斯分布的随机变量组合而成。如下图,我们就是用三个二维高斯分布生成的数据集。

(教程完整版请看这里。)
2. 最大期望算法(Expectation–Maximization, EM)
有了隐变量还不够,我们还需要一个算法来找到最佳的W,从而得到GMM的模型参数。EM算法就是这样一个算法。
简单说来,EM算法分两个步骤。
- 第一个步骤是E(期望),用来更新隐变量WW;
- 第二个步骤是M(最大化),用来更新GMM中各高斯分布的参量
然后重复进行以上两个步骤,直到达到迭代终止条件。
3. 具体步骤以及Python实现
完整代码在第4节。
首先,我们先引用一些我们需要用到的库和函数。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from scipy.stats import multivariate_normal
plt.style.use('seaborn')接下来,我们生成2000条二维模拟数据,其中400个样本来自N(μ1,var1)N(μ1,var1),600个来自N(μ2,var2)N(μ2,var2),1000个样本来自N(μ3,var3)N(μ3,var3)
# 第一簇的数据
num1, mu1, var1 = 400, [0.5, 0.5], [1, 3]
X1 = np.random.multivariate_normal(mu1, np.diag(var1), num1)
# 第二簇的数据
num2, mu2, var2 = 600, [5.5, 2.5], [2, 2]
X2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)
# 第三簇的数据
num3, mu3, var3 = 1000, [1, 7], [6, 2]
X3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)
# 合并在一起
X = np.vstack((X1, X2, X3))数据如下图所示:
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X1[:, 0], X1[:, 1], s=5)
plt.scatter(X2[:, 0], X2[:, 1], s=5)
plt.scatter(X3[:, 0], X3[:, 1], s=5)
plt.show()3.1 变量初始化
首先要对GMM模型参数以及隐变量进行初始化。通常可以用一些固定的值或者随机值。
n_clusters是GMM模型中聚类的个数,和K-Means一样我们需要提前确定。这里通过观察可以看出是3。(拓展阅读:如何确定GMM中聚类的个数?)
n_points是样本点的个数。
Mu是每个高斯分布的均值。
Var是每个高斯分布的方差,为了过程简便,我们这里假设协方差矩阵都是对角阵。
W是上面提到的隐变量,也就是每个样本属于每一簇的概率,在初始时,我们可以认为每个样本属于某一簇的概率都是1/31/3。
Pi是每一簇的比重,可以根据W求得,在初始时,Pi = [1/3, 1/3, 1/3]
n_clusters = 3
n_points = len(X)
Mu = [[0, -1], [6, 0], [0, 9]]
Var = [[1, 1], [1, 1], [1, 1]]
Pi = [1 / n_clusters] * 3
W = np.ones((n_points, n_clusters)) / n_clusters
Pi = W.sum(axis=0) / W.sum()3.2 E步骤
E步骤中,我们的主要目的是更新W。第ii个变量属于第mm簇的概率为:
Wi,m=πjP(Xi|μm,varm)∑3j=1πjP(Xi|μj,varj)Wi,m=πjP(Xi|μm,varm)∑j=13πjP(Xi|μj,varj)
根据WW,我们就可以更新每一簇的占比πmπm,
πm=∑ni=1Wi,m∑kj=1∑ni=1Wi,jπm=∑i=1nWi,m∑j=1k∑i=1nWi,j
def update_W(X, Mu, Var, Pi):
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
W = pdfs / pdfs.sum(axis=1).reshape(-1, 1)
return W
def update_Pi(W):
Pi = W.sum(axis=0) / W.sum()
return Pi以下是计算对数似然函数的logLH以及用来可视化数据的plot_clusters。
def logLH(X, Pi, Mu, Var):
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
return np.mean(np.log(pdfs.sum(axis=1)))
def plot_clusters(X, Mu, Var, Mu_true=None, Var_true=None):
colors = ['b', 'g', 'r']
n_clusters = len(Mu)
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X[:, 0], X[:, 1], s=5)
ax = plt.gca()
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'ls': ':'}
ellipse = Ellipse(Mu[i], 3 * Var[i][0], 3 * Var[i][1], **plot_args)
ax.add_patch(ellipse)
if (Mu_true is not None) & (Var_true is not None):
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'alpha': 0.5}
ellipse = Ellipse(Mu_true[i], 3 * Var_true[i][0], 3 * Var_true[i][1], **plot_args)
ax.add_patch(ellipse)
plt.show()3.2 M步骤
M步骤中,我们需要根据上面一步得到的W来更新均值Mu和方差Var。 Mu和Var是以W的权重的样本X的均值和方差。
因为这里的数据是二维的,第mm簇的第kk个分量的均值,
μm,k=∑ni=1Wi,mXi,k∑ni=1Wi,mμm,k=∑i=1nWi,mXi,k∑i=1nWi,m
第mm簇的第kk个分量的方差,
varm,k=∑ni=1Wi,m(Xi,k−μm,k)2∑ni=1Wi,mvarm,k=∑i=1nWi,m(Xi,k−μm,k)2∑i=1nWi,m
以上迭代公式写成如下函数update_Mu和update_Var。
def update_Mu(X, W):
n_clusters = W.shape[1]
Mu = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Mu[i] = np.average(X, axis=0, weights=W[:, i])
return Mu
def update_Var(X, Mu, W):
n_clusters = W.shape[1]
Var = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Var[i] = np.average((X - Mu[i]) ** 2, axis=0, weights=W[:, i])
return Var3.3 迭代求解
下面我们进行迭代求解。
图中实现是真实的高斯分布,虚线是我们估计出的高斯分布。可以看出,经过5次迭代之后,两者几乎完全重合。
loglh = []
for i in range(5):
plot_clusters(X, Mu, Var, [mu1, mu2, mu3], [var1, var2, var3])
loglh.append(logLH(X, Pi, Mu, Var))
W = update_W(X, Mu, Var, Pi)
Pi = update_Pi(W)
Mu = update_Mu(X, W)
print('log-likehood:%.3f'%loglh[-1])
Var = update_Var(X, Mu, W)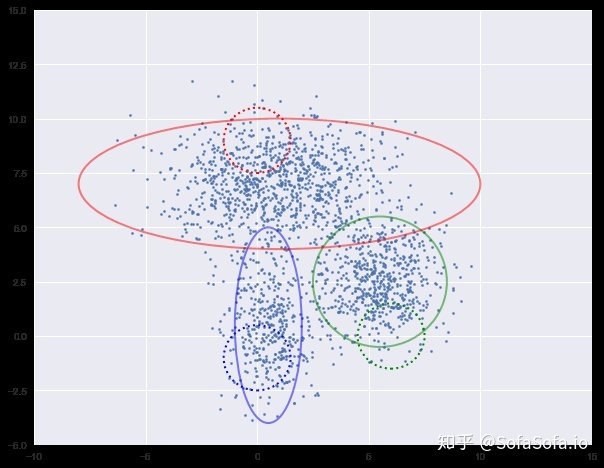
log-likehood:-8.054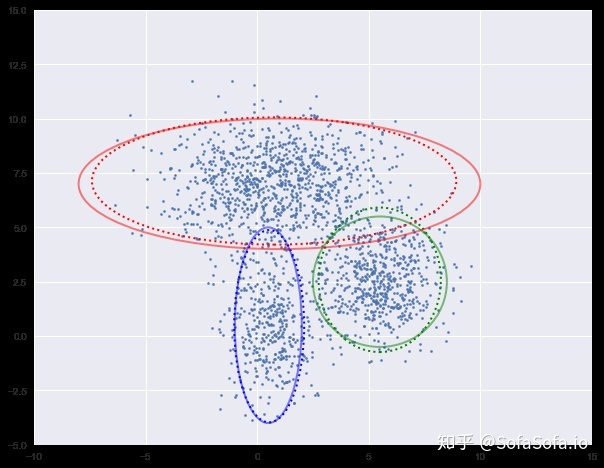
log-likehood:-4.731
log-likehood:-4.729
log-likehood:-4.728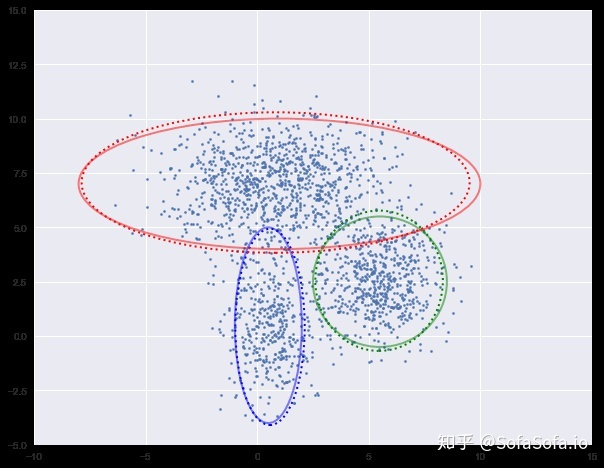
原文:GMM与EM算法的Python实现-SofaSofa
找工求职怎能没有好简历:数据科学、ML岗位的简历应该怎么写?
SofaSofa数据实战:还在拿MNIST练习?不如试试这个
你想知道自己水平如何?不如来做套数据科学、机器学习的自测题(戳这里,以及戳这里)
更多中美企业校招、社招机器学习、数据科学岗位面试题(看这里)















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









