





简介
今天我想简单记录一下自己构建语料库的过程, 方便自己查看和方便协作. 在工作中我们经常遇到一个问题就是每个研究者都有自己的语料库, 存储格式不同, 有用mysql这种结构化数据库的, 也有mogodb这种文档型数据库, 还有更多的是使用文本文件, 不管哪种形式, 都会导致数据交换出现困难. 他人使用这个语料库的时候需要自己写语料库的预处理函数, 否则语料库是不能进入计算的. 为了减少这种不必要的重复劳动, 我们就使用gensim.corpora.textcorpus.TextDirectoryCorpus类来管理语料. 也就是说, 我们的语料保存在文件夹中, 设置lines_are_documents=False来保证每个文件是一篇文档. 如果我们都以相同的方式管理语料库, 那么我们的协作就更顺畅.
目录结构
因为TextDirectoryCorpus可以支持嵌套的文件夹, 只要指定max_depth和min_depth两个参数就能控制文件夹深度. 我通常是使用一个文件夹放所有文本文件. 比如我有这样一个目录作为语料库:
1
2
3
4
5
6
7
8
9
10
11
12└─test-corpus # 根目录
│ dictionary.model # 字典数据
│ meta.csv # 元信息
│
└─corpus # 存放文档
01.txt
02.txt
03.txt
04.txt
05.txt
06.txt
07.txt
1
2
3import re
re.compile('.*\.txt')
输出:
re.compile(r'.*\.txt', re.UNICODE)
TextDirectoryCorpus简单使用
先看以下基本用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# 引入用到的库
from gensim.corpora.textcorpus import TextDirectoryCorpus
import locale
locale.setlocale(locale.LC_ALL, 'en_US.utf-8')
# 数据所在路径
dpath = r'D:\mysites\notebooks\data\test-corpus'
class MyTextDirCorpus(TextDirectoryCorpus):
# 为了强制使用'utf8'编码, 我们复写了这个方法
def getstream(self):
"""Yield documents from the underlying plain text collection (of one or more files).
Each item yielded from this method will be considered a document by subsequent
preprocessing methods.
If `lines_are_documents` was set to True, items will be lines from files. Otherwise
there will be one item per file, containing the entire contents of the file.
"""
num_texts = 0
for path in self.iter_filepaths():
with open(path, 'rt', encoding='utf8') as f:
if self.lines_are_documents:
for line in f:
yield line.strip()
num_texts += 1
else:
content = f.read().strip()
yield content
num_texts += 1
self.length = num_texts
# 实例化一个语料库,
# 遍历的最小深度是1
# 设置lines_are_documents为False
# 后缀为txt的文件才会被当作是一个文档
corpus = MyTextDirCorpus(dpath, min_depth=1, pattern='.*\.txt', lines_are_documents=False)
print('语料库计数:', len(corpus))
print('第一条:',next(corpus.get_texts()))
输出:
语料库计数: 7
第一条: ['树中路径的交集图']
分词和词典生成
为了让同事之间的工作更有一致性, 我们通常要预先对语料库进行分词, 使得不同的人具有相同的分词结果. 我们就用最简单的方法, 使用pyltp模块进行分词, 然后生成一个词典.
我们先来看看pyltp是如何进行分词的:
1
2
3
4
5
6
7
8
9# 分词测试
from pyltp import Segmentor
new_doc = '实验室中测量无序响应中时间'
model_path = r'D:\mysites\text-characters\tcharacters\ltp\ltp_data\cws.model'
segmentor = Segmentor() # 初始化实例
segmentor.load(model_path)
new_tokens = segmentor.segment(new_doc)
print('Tokens:', '\t'.join(new_tokens))
segmentor.release() # 释放模型
输出:
Tokens: 实验室中测量无序响应中时间
实现一个分词器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61class MyTextDirCorpus(TextDirectoryCorpus):
def __init__(self, input, **kwargs):
kwargs['tokenizer'] = self.tokenizer
super().__init__(input, **kwargs)
def tokenizer(self, text):
if not hasattr(self, '_segmentor'):
model_path = r'D:\mysites\text-characters\tcharacters\ltp\ltp_data\cws.model'
segmentor = Segmentor() # 初始化实例
segmentor.load(model_path)
self._segmentor = segmentor
segmentor = self._segmentor
return segmentor.segment(text)
def __del__(self):
'''释放资源'''
if hasattr(self, '_segmentor'):
self._segmentor.release()
try:
super().__del__()
except AttributeError:
pass
# 为了强制使用'utf8'编码, 我们复写了这个方法
def getstream(self):
"""Yield documents from the underlying plain text collection (of one or more files).
Each item yielded from this method will be considered a document by subsequent
preprocessing methods.
If `lines_are_documents` was set to True, items will be lines from files. Otherwise
there will be one item per file, containing the entire contents of the file.
"""
num_texts = 0
for path in self.iter_filepaths():
with open(path, 'rt', encoding='utf8') as f:
if self.lines_are_documents:
for line in f:
yield line.strip()
num_texts += 1
else:
content = f.read().strip()
yield content
num_texts += 1
self.length = num_texts
# 实例化一个语料库
# 注意我们传入了一个token_filters参数, 实际上是一个空列表, 意思是, 不要过滤词, 所有词都要
# 当然在有需要的情况下, 我们需要定义自己的token_filters
corpus = MyTextDirCorpus(dpath, min_depth=1,
pattern='.*\.txt',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
# 保存词典到本地硬盘
dict_path = r'D:\mysites\notebooks\data\test-corpus\dictionary.model'
corpus.dictionary.save_as_text(fname=dict_path)
# 查看词典内容
corpus.dictionary.token2id
输出:
{'中': 0,
'交集图': 1,
'树': 2,
'的': 3,
'路径': 4,
'\ufeff': 5,
'无序': 6,
'生成': 7,
'随机二进制': 8,
'与': 9,
'关系': 10,
'响应': 11,
'感知': 12,
'时间': 13,
'测量': 14,
'用户': 15,
'误差': 16,
'eps': 17,
'人体': 18,
'和': 19,
'测试': 20,
'系统': 21,
'系统工程': 22,
'界面': 23,
'管理': 24,
'对': 25,
'看法': 26,
'计算机': 27,
'调查': 28,
'实验室': 29,
'应用': 30}
你可以在dict_path这个路径下看到我们的字典内容, 使用任意一个文本编辑器即可打开, 如下图, 三列数据分别表示id/词/计数.
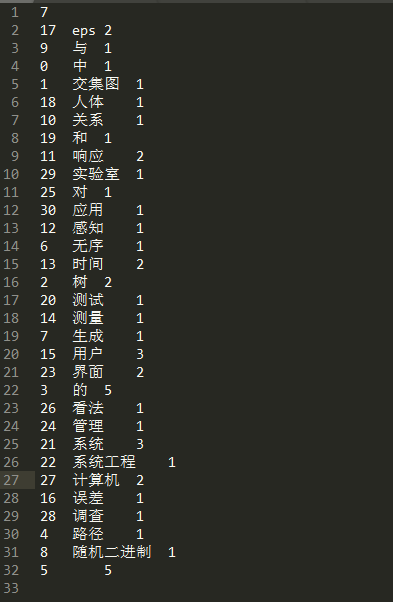
词典的使用
生成了词典以后, 我们以后再使用语料库的时候, 可以不必每次都重新计算词典, 这个过程非常耗费资源, 所以我们使用已经存储在硬盘的词典数据.
1from gensim.corpora.dictionary import Dictionary
1
2
3
4
5
6
7
8
9
10%%timeit
# 预加载字典
dic = Dictionary.load_from_text(dict_path)
MyTextDirCorpus(dpath,
dictionary=dic,
min_depth=1,
pattern='.*\.txt',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
输出:
122 µs ± 435 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
1
2
3
4
5
6
7
8%%timeit
# 每次生成词典
MyTextDirCorpus(dpath,
min_depth=1,
pattern='.*\.txt',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
输出:
190 ms ± 116 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
通过上面的测试, 我们发现两种方式的差别很大, 这还是在小语料库上测试的, 如果是大语料库, 这个差别就是几个数量级的差别了.
预先分词
其实, 很多人协作的情况下, 保证大家的分词结果的一致性是很有必要的, 不然很多结果都没有可比性. 与其每个人都分一遍词, 不如从一开始就分好词. 所以我们可以把词分好, 然后保存到硬盘.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import pickle
from pathlib import Path
dic = Dictionary.load_from_text(dict_path)
corpus = MyTextDirCorpus(dpath,
dictionary=dic,
min_depth=1,
pattern='.*\.txt$',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
for fpath in corpus.iter_filepaths():
fpath = Path(fpath)
token_path = fpath.parent / (fpath.name + '.cached_tokens')
txt = fpath.read_text(encoding='utf8').strip()
tokens = corpus.tokenizer(txt)
token_path.write_bytes(pickle.dumps(list(tokens)))
使用预先分好的词, 可以再给我们的MyTextDirCorpus添加一个方法get_texts_from_tokens
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51class MyTextDirCorpus(TextDirectoryCorpus):
def __init__(self, input, **kwargs):
kwargs['tokenizer'] = self.tokenizer
super().__init__(input, **kwargs)
def tokenizer(self, text):
if not hasattr(self, '_segmentor'):
model_path = r'D:\mysites\text-characters\tcharacters\ltp\ltp_data\cws.model'
segmentor = Segmentor() # 初始化实例
segmentor.load(model_path)
self._segmentor = segmentor
segmentor = self._segmentor
return segmentor.segment(text)
def __del__(self):
'''释放资源'''
if hasattr(self, '_segmentor'):
self._segmentor.release()
try:
super().__del__()
except AttributeError:
pass
# 为了强制使用'utf8'编码, 我们复写了这个方法
def getstream(self):
"""Yield documents from the underlying plain text collection (of one or more files).
Each item yielded from this method will be considered a document by subsequent
preprocessing methods.
If `lines_are_documents` was set to True, items will be lines from files. Otherwise
there will be one item per file, containing the entire contents of the file.
"""
num_texts = 0
for path in self.iter_filepaths():
with open(path, 'rt', encoding='utf8') as f:
if self.lines_are_documents:
for line in f:
yield line.strip()
num_texts += 1
else:
content = f.read().strip()
yield content
num_texts += 1
self.length = num_texts
def get_texts_from_tokens(self):
for fpath in self.iter_filepaths():
fpath = Path(fpath)
token_path = fpath.parent / (fpath.name + '.cached_tokens')
yield pickle.loads(token_path.read_bytes())
测试以下我们新的方法是不是更节省时间:
1
2
3
4
5
6
7
8
9
10
11
12
13%%timeit
dic = Dictionary.load_from_text(dict_path)
corpus = MyTextDirCorpus(dpath,
dictionary=dic,
min_depth=1,
pattern='.*\.txt$',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
for i in corpus.get_texts():
pass
输出:
154 ms ± 2.82 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
1
2
3
4
5
6
7
8
9
10
11
12
13%%timeit
dic = Dictionary.load_from_text(dict_path)
corpus = MyTextDirCorpus(dpath,
dictionary=dic,
min_depth=1,
pattern='.*\.txt$',
lines_are_documents=False,
tokenizer=tokenizer,
token_filters=[])
for i in corpus.get_texts_from_tokens():
pass
输出:
969 µs ± 7.14 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
测试显示, 时间还是差了几个数量级, 而且第二种方法的好处是, 我们使用语料库时不必再依赖分词模块pyltp.
总结
现在我们基本上已经构建了一个标准统一的语料库, 而且预先进行了分词和词典生成. 现在我们把所有用到的代码都封装到MyTextDirCorpus类中. 看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68# author: mlln.cn
# email: xxxspy@126.com
# qq: 675495787
class MyTextDirCorpus(TextDirectoryCorpus):
def __init__(self, input, **kwargs):
kwargs['tokenizer'] = self.tokenizer
super().__init__(input, **kwargs)
def tokenizer(self, text):
if not hasattr(self, '_segmentor'):
model_path = r'D:\mysites\text-characters\tcharacters\ltp\ltp_data\cws.model'
segmentor = Segmentor() # 初始化实例
segmentor.load(model_path)
self._segmentor = segmentor
segmentor = self._segmentor
return segmentor.segment(text)
def __del__(self):
'''释放资源'''
if hasattr(self, '_segmentor'):
self._segmentor.release()
try:
super().__del__()
except AttributeError:
pass
# 为了强制使用'utf8'编码, 我们复写了这个方法
def getstream(self):
"""Yield documents from the underlying plain text collection (of one or more files).
Each item yielded from this method will be considered a document by subsequent
preprocessing methods.
If `lines_are_documents` was set to True, items will be lines from files. Otherwise
there will be one item per file, containing the entire contents of the file.
"""
num_texts = 0
for path in self.iter_filepaths():
with open(path, 'rt', encoding='utf8') as f:
if self.lines_are_documents:
for line in f:
yield line.strip()
num_texts += 1
else:
content = f.read().strip()
yield content
num_texts += 1
self.length = num_texts
def get_texts_from_tokens(self):
for fpath in self.iter_filepaths():
fpath = Path(fpath)
token_path = fpath.parent / (fpath.name + '.cached_tokens')
yield pickle.loads(token_path.read_bytes())
def save_tokens(self):
'''保存tokens到硬盘, 只需要运行一次'''
for fpath in self.iter_filepaths():
fpath = Path(fpath)
token_path = fpath.parent / (fpath.name + '.cached_tokens')
txt = fpath.read_text(encoding='utf8').strip()
tokens = self.tokenizer(txt)
token_path.write_bytes(pickle.dumps(list(tokens)))
def save_dictionary(self, dpath):
'''把字典保存到硬盘'''
self.dictionary.save_as_text(fname=dpath)
本为由mlln.cn原创, 转载请注明出处(mlln.cn), 本站保留版权. 欢迎童鞋在下方留言反馈.
注意
本文由jupyter notebook转换而来, 您可以在这里下载notebook
有问题可以直接在下方留言
或者给我发邮件675495787[at]qq.com
请记住我的网址: mlln.cn 或者 jupyter.cn

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









