





从2018年起,图神经网络(GNN)开始受到了额外的关注,成为了一个新的热点。在2019年CVPR所有录用的论文中,关键字graph出现的次数就从2018年的15次增长到了45次,增长态势凶猛。其中许多工作都与GCN相关(比如之前解读过的IGCN),这是一篇被ICLR2017会议录用的频谱图卷积工作,非常经典。而GCN又来源于对ChebNet的进一步简化与近似,他们都属于在频域上定义的图卷积网络。本文将对ChebNet和GCN这两个经典方法进行梳理,重点解释GCN从ChebNet的简化过程,原始论文可参考:
[1] Convolutional neural networks on graphs with fast localized spectral filtering (NIPS2016)
[2] Semi-supervised classification with graph convolutional networks (ICLR17)
另外,本文的内容与之前的解读文相关,一些预备知识已在下文中说明,本文不再赘述。
[3] 【CVPR2019论文解读】具有高标签利用率的图滤波半监督学习方法
频谱图卷积的一般形式
图的结构不像二维网格那样稳定,每个图节点的度不尽相同,所以无法像CNN一样直接在空间域(节点域)上为所有节点使用相同大小的局部图卷积核。于是研究者们提出可以在频域上定义卷积,因为在空间域的卷积其实就相当于在频域上的乘积。图信号处理根据图的拉普拉斯矩阵L的特征分解定义了图的频谱,结合这种图的频谱的定义,研究者们定义了空域上的图信号x和y的卷积为:
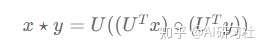
即先使用U^TUT将信号x和y变换到频域,然后相乘(逐元素相乘),最后再使用UU将乘积后的信号变换到空间域。具体地,对于一个参数化的滤波器信号G与输入信号x,频谱图卷积可定义为:
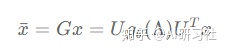
其中的函数g_theta(Lambda)gθ(Λ)为卷积核的频率响应函数,thetaθ为待学习参数。以上就是频谱图卷积的一般形式,有许多频谱图卷积的工作以此式为核心展开。
k阶近似与ChebNet
ChebNet的作者指出原始的频谱图卷积有两大缺点:
① 图卷积核是全局的且参数量大 (卷积核大小与输入信号相同,参数量与图节点数相同)
② 图卷积运算的复杂度高 (运算过程涉及高计算复杂度的特征分解)
可以想象一下一个卷积核大小与输入图像大小相同的普通CNN卷积层,再想象CNN的卷积运算是平方复杂度,这样的“卷积”运算的实用性毋庸置疑是很差的,更别利用其构造深层神经网络。
首先,为了克服卷积核过“大”的缺点,ChebNet指出可以使用多项式展开近似计算图卷积,即对参数化的频率响应函数进行多项式近似:
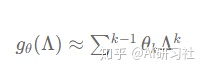
其中k代表多项式的最高阶数,这一步近似将卷积核的参数数量从n个减少到了k个,使卷积核变“小”了,变得“局部”了。但是整个图卷积运算的复杂度还是O(n^2)O(n2),因为输入信号要与傅里叶基U做矩阵乘法。为了进一步降低计算复杂度,作者使用迭代定义的切比雪夫多项式(ChebShev Polynomial)作近似并证明可以将计算复杂度降低至O(K|E|)O(K∣E∣),其中K为多项式的阶数,E为图中边的数量。作者将基于切比雪夫多项式定义的卷积核称为切比雪夫卷积核,对应的卷积运算则称为切比雪夫卷积,他们的公式定义如下:

图1. 切比雪夫图卷积的定义
式中的lambda_{max}λmax表示拉普拉斯矩阵的最大特征值,添加’是为了表明这是近似的参数。从替换和化简后的卷积运算式可以发现,切比雪夫多项式矩阵的运算是固定,可以在预处理阶段完成,且拉普拉斯矩阵一般是稀疏的,可以使用稀疏张量乘法加速,因此整个图卷积的计算复杂度大大降低。除了定义切比雪夫图卷积外,ChebNet的作者还提出了图池化层,有兴趣的读者可以阅读原文深入了解,由于图池化不是本文的重点,所以此处不展开叙述。
1阶近似与GCN
受切比雪夫图卷积的启发,Thomas等人(GCN的作者)提出了一种更加简单的图卷积变种GCN。GCN相当于对一阶切比雪夫图卷积的再近似。在切比雪夫卷积核定义的基础上,我们令多项式的阶数K=1,再令矩阵L的大特征值为2(带来的缩放效应可以通过网络学习自动适应),则图卷积运算过程可以按如下过程进一步简化:

图2. GCN简化ChebNet的过程
可以发现,GCN的卷积核更小,参数量也更少,计算复杂度也随之减小,可以说是将简化进行到了极致,它等价于最简的一阶切比雪夫卷积。上图中倒数第三行的变换被称为“重归一化技巧”,GCN的作者指出,前者的特征值范围是在区间[0,2]内的,所以在神经网络当中多次反复运用这样的算子(多层堆叠)会导致梯度消失和梯度爆炸的问题,为此他们使用归一化技巧将其转化成后者。而我们从吴晓明老师团队的图滤波半监督学习的研究中了解到,重归一化技巧能够将特征值范围进一步缩小以使滤波器变得更加低通,这也是一种有力的解释。
对比ChebNet和GCN,ChebNet的复杂度和参数量比GCN要高,但是表达能力强。ChebNet的K阶卷积算子可以覆盖节点的K阶邻居节点,而GCN则只覆盖一阶邻居节点,但是通过堆叠多个GCN层也可以扩大图卷积的感受域,所以灵活性比较高。最重要的是复杂度较低的GCN相比之前的方法都更加易于训练,速度快且效果好,实用性很强,所以成为了倍最多提到的典型方法(当前引用量为1094)。为了直观的感受GCN的样子,我画了一个简单的示意图:

图3. GCN图卷积层的示意图
总的来看,频谱图卷积网络的研究以图的频谱分析为理论基础,沿着“降低模型复杂度”的主线进行,大多数常规的图运算天然的平方复杂度是掣肘图卷积实用性的主要阻碍,但是最终研究者们还是利用多项式近似和神经网络的适应性一步步将图卷积网络改造到了实用级别,也提高了图卷积网络的研究热度。图嵌入、半监督学习等方向的研究也在不断助推者GNN研究的发展,将卷积从规则的欧式空间推广到非欧式空间是一个非常有意义的课题,这能够使神经网络应用到更多的问题领域,让我们拭目以待它的后续发展。对图神经网络感兴趣的同学可以参考这篇IEEE Fellow给新人的图神经网络综述文章。
以上解读为本人 @月本诚 在AI研习社 CVPR 小组原创首发,我已经努力保证解读的观点正确、精准,但本人毕竟才学疏浅,文中若有不足之处欢迎大家批评指正。所有方法的解释权归原始论文作者所有。
AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。ai.yanxishe.com今日资源推荐:















 4242
4242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









