





上节我们说了留出法,这次说下K折交叉验证,这是我们做模型评估时经常使用的方法。
K折交叉验证的3个要点:
1:数据集划分为K个相同大小的互斥子集。
2:通过分层抽样K个子集保持分布一致性。
3:K次评估结果的均值,每次用K-1个集合训练,剩下的一个做模型评估。

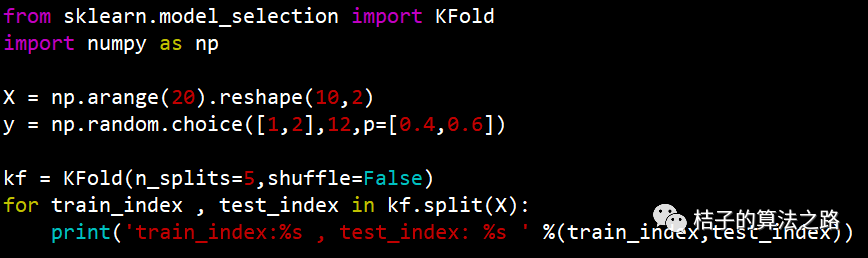

上述例子中共有样本10个,我们做了5折交叉验证,看下测试集索引,所有样本集的并集就是整个样本集了,训练集与当前测试集的并集也是整个样本集,其实就是每次用其中把本样本做为训练集,剩余的两个做为测试集,最终是用这5组样本集训练的模型进行性能评估的平均。
当K是样本集大小时就是:留一法。也就是每次只有一个样本做为验证集,留一法评估结果一般比较准确,就是当样本集太大时太耗时,所以一般很少用到留一法,这里就不多介绍了。















 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









