





前言:
python是易语言,简单易学,今天来讲解一个爬虫小demo。主要功能包括某招聘网站的数据抓取,以及把数据存入Excel表中。注:本文仅用于学习交流。
思路:
程序是死的,数据是多样性的。要想去抓取数据某网站的数据,首先需要做的就是打开网站,按一下F12,然后分析前端页面的数据展示的规律。
一般情况,页面数据都是通过遍历集合循环出来的。
一、引用资源模块
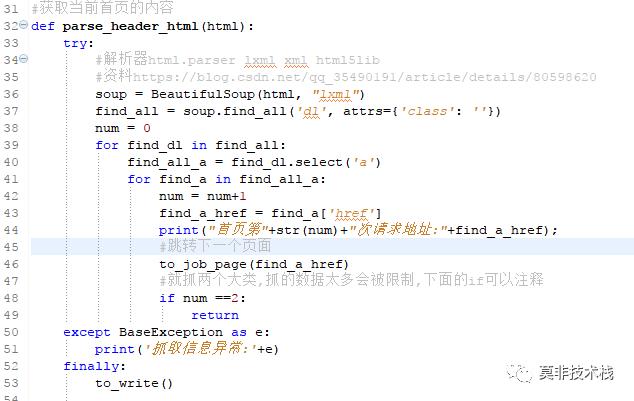
二、模拟一个用户,请求网站,并获取网站首页内容

三、解析网站首页内容(大的分类)
解析网站首页,可以获取网站首页职业分类的集合,可以根据每一个职业分类和对应的跳转地址,跳转下一个页面。
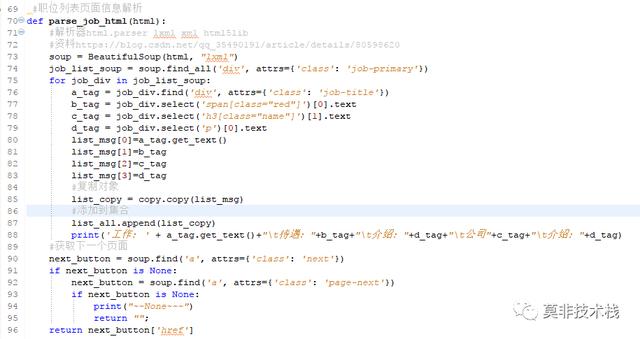
四、跳转详细职业信息的列表页面
需要有一个循环,获取列表页面每一个页面的内容。

解析当前页面的信息,并返回下一个页面的地址。
五、抓取的信息写入Excel

6、程序入口

注意事项;现在的大型网站都是反爬虫机制,所以抓取的频率不要太高。我现在的处理是让每个页面随机停顿1-3秒。为了演示,只抓取两个职业大类的数据。代码中有个判断放开,就会抓取整个网站的数据。
需要源码的可以关注公众号领取:
















 5392
5392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









