







全文共6522字,预计学习时长19分钟

图源:Unsplash
前不久,AWS re:Invent, Netflix 开源了一个自主开发的构建和管理数据科学项目的框架——Metaflow。在过去的两年里,他们内部数据科学团队迅速地应用它,使得许多项目能够缩短生产时间。
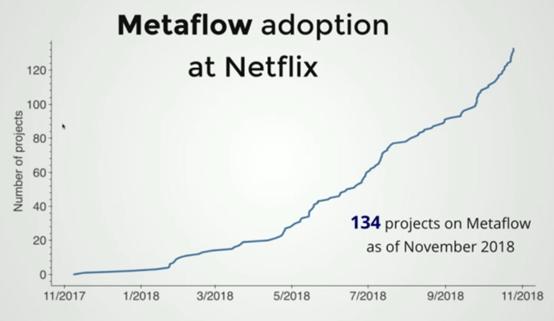
Netflix采用Metaflow

什么是Metaflow?
Metaflow是创建和执行数据科学工作流的框架,并配备了内置功能:
· 管理计算机资源,
· 执行容器化运行,
· 管理外部依赖,
· 版本、重播和恢复工作流运行
· 客户端 API 检查过去的运行适合笔记本电脑,
· 在本地,比如笔记本电脑,和远程云端执行模式之间切换
在内容寻址的数据存储中,Metaflow 自动对代码、数据和依赖关系进行快照,这通常由 S3支持,但也支持本地文件系统。这样就可以总结工作流,重现过去的结果,并检查关于工作流的任何东西,例如笔记本。—— Ycombinator上的vtuulos
基本上它旨在提高数据科学家的生产力,使他们能够专注于实际的数据科学工作,促进其交付成果的更快生产。
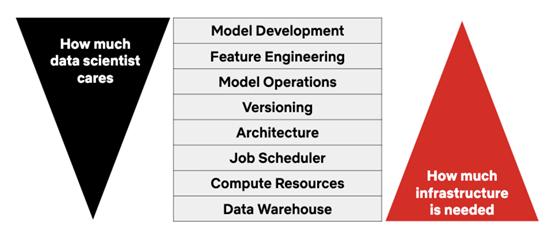
实际数据科学与基础设施需要
每天都有可能发生的事情
· 协作:帮助另一个数据科学家调试错误。希望可以在自己的笔记本电脑中按原样调出他失败的运行状态。
· 恢复运行: 运行失败或故意停止。修复代码中的错误后,希望可以从工作流失败、或停止的地方重新启动工作流。
· 混合运行:希望在本地运行工作流中的一个步骤,可能是数据加载步骤,因为数据集下载文件夹中;但是希望在云上运行另一个计算密集步骤:模型训练。
· 检查运行元数据: 三位数据科学家一直在调整超参数,以便在同一模型上获得更高的准确性。需要分析他们所有的训练运行情况,并选择性能最好的超参数集。
· 相同软件包的多个版本: 希望能够在项目中使用sklearn库的多个版本:0.20版本用于预处理步骤,0.22版本用于建模。
典型的Meta(工作)流是什么样子的?
概念
Metaflow工作流本质上是DAGs (有向无环图) 。下面的图像对其进行了最好的描述。图中的每个节点代表工作流中的一个处理步骤。

线性无环图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









