






我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。
这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数据库的处理模型定义了系统如何运行一个查询计划,不同的工作负载选择不同的处理模型。
在进入下面的文章之前,假设我们有以下的 SQL 查询:
|
根据之前的文章,我们很快就可以将上面这条 SQL 的查询计划画出来:
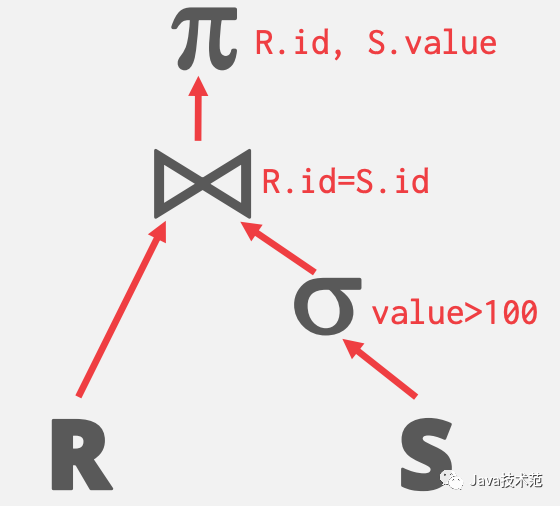
系统为了处理这个查询计划,主要有三种执行模型:
迭代模型(Iterator Model)
物化模型(Materialization Model)
向量化/批处理模型(Vectorized / Batch Model)
下面我们来简单介绍这三种执行模型的区别。
迭代模型(Iterator Model)
迭代模型又称 Volcano Model 或者 Pipeline Model。这种模型中的查询计划算子(query plan operator)都需要实现 next() 函数:
每次调用的时候,operator 将返回一个元组(tuple)或一个空标记(null),空标记代表数据已经遍历完;
operator 需要实现一个循环,其调用子 operator 的
next()函数,用于从子 operator 中获取数据,然后再处理它。
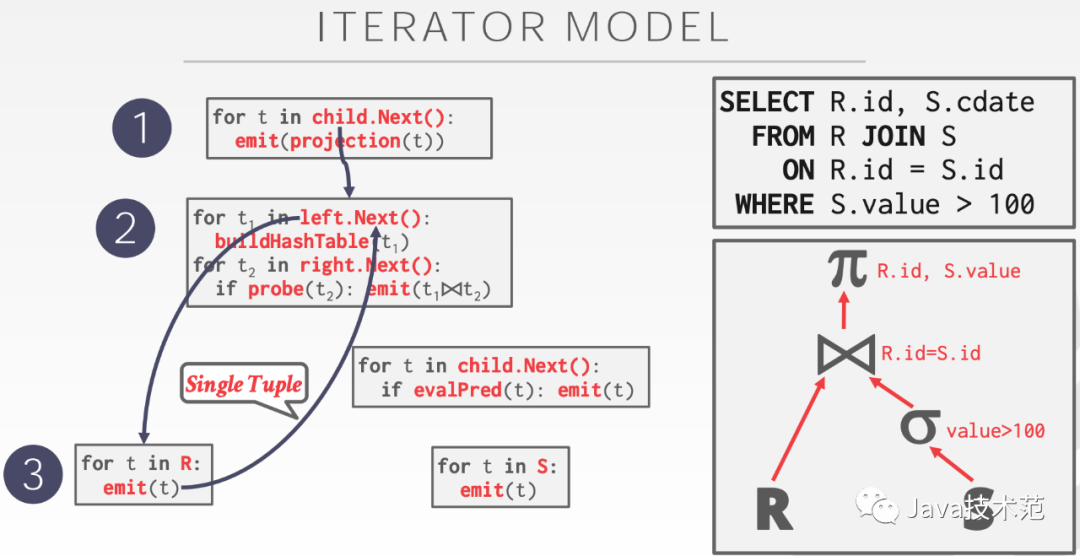
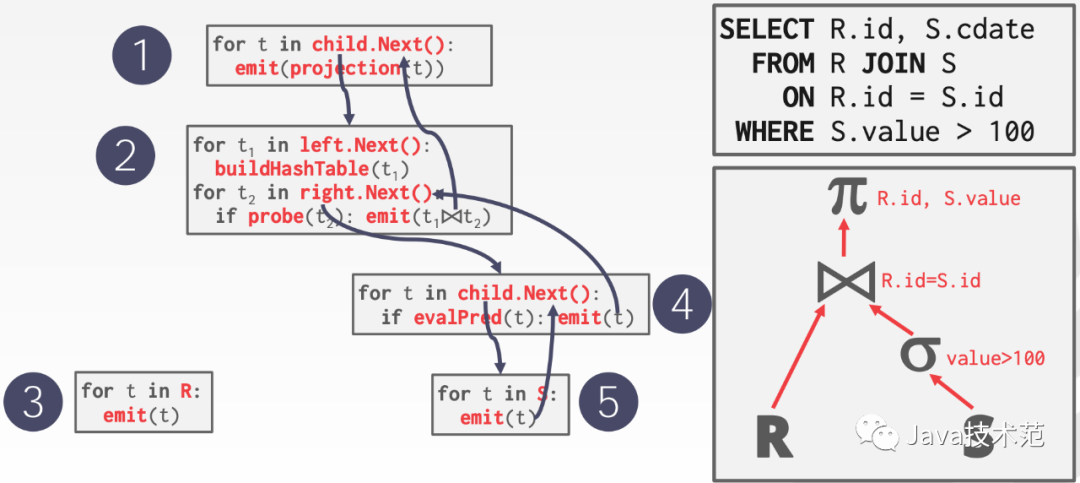
当今世界上绝大多数关系型数据库都是使用迭代模型的,比如 SQLite、MongoDB、Impala、DB2、SQLServer、Greenplum、PostgreSQL、Oracle、MySQL 等。我们熟悉的 Apache Spark 1.x 的 SQL 引擎也是基于这个模型做的(参见 Apache Spark作为编译器:深入介绍新的Tungsten执行引擎)。迭代模型的优点是抽象起来很简单,很容易实现,而且可以通过任意组合算子来表达复杂的查询。但是缺点也很明显,存在大量的虚函数调用,会引起 CPU 的中断,最终影响了执行效率;而且 Joins, Subqueries, Order By 等操作在其子 operator 返回数据之前会被 block 住。
物化模型(Materialization Model)
物化模型的处理方式是:每个 operator 一次处理所有的输入,处理完之后将所有结果一次性输出。由于这种模式中的 operator 其输出“物化”为单个结果,所以称为物化模型。在实现中,DBMS 一般会下推一些 hints 以避免扫描太多的数据。注意,这种模式可以返回物化的行数据或者单列数据。物化模型的处理流程如下:
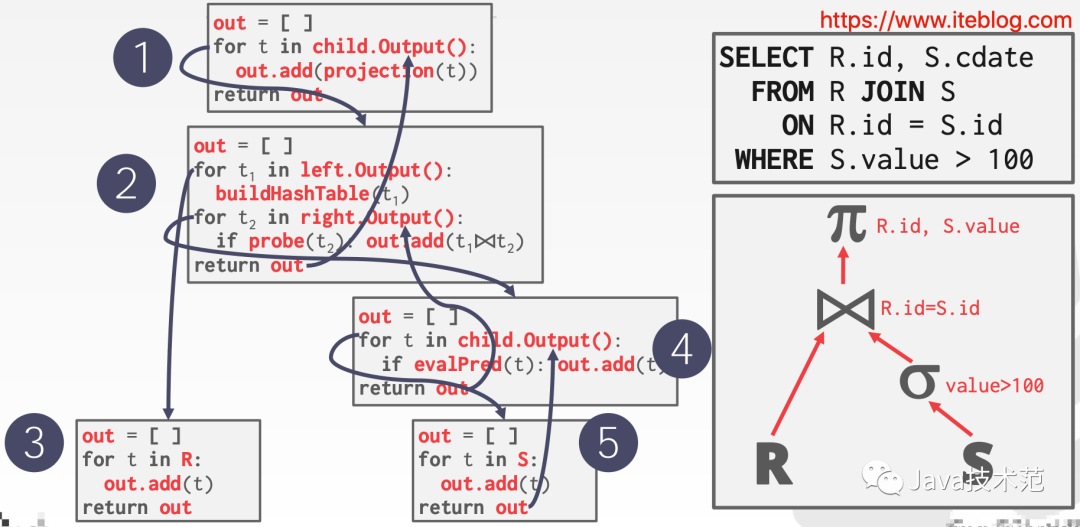
物化模型更适合 OLTP 负载,因为这些查询每次只访问小规模的数据,只需要少量的函数调用。
向量化/批处理模型(Vectorized / Batch Model)
Vectorization Model 和 Iterator Model 类似,每个 operator 需要实现一个 next() 函数,但是每次调用 next() 函数会返回一批的元组(tuples)而不是一个元组。在 operator 内部,每次循环都会处理多个元组。批次的大小可以根据硬件或者查询数据进行配置的。可以看出Vectorization Model 是 Iterator Model 和 Materialization Model 的折衷。向量化模型的处理流程如下:
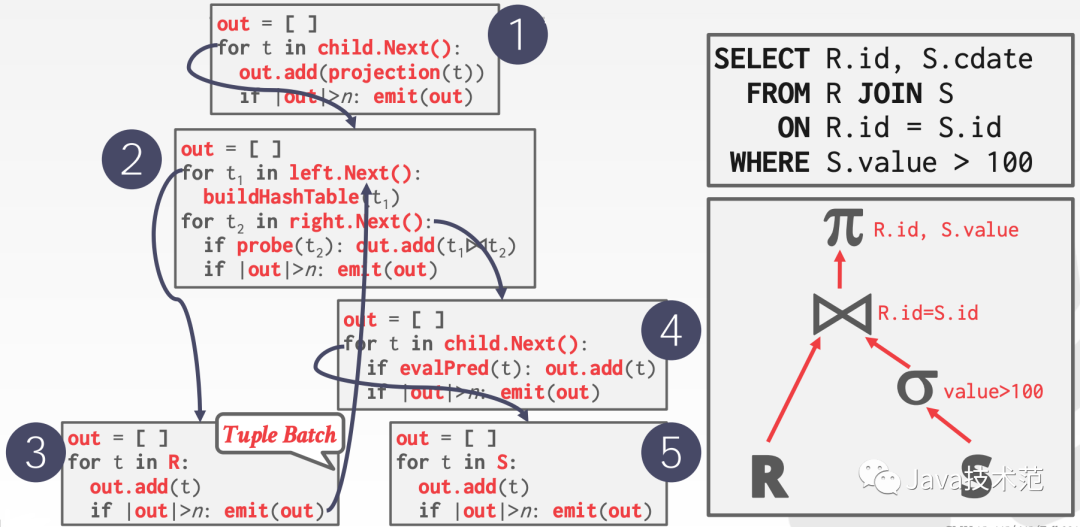
Vectorization Model 比较适合 OLAP 查询,因为其大大减少了每个 operator 的调用次数,也就简单减少了虚函数的调用。而且现代编译器和 CPU 在运行简单的循环时,是非常高效的。编译器会自动展开简单的循环,甚至在每个 CPU 指令中产生 SIMD 指令来处理多个元组。
Presto(参见 Aria 项目)、snowflake、SQLServer、Amazon Redshift 等数据库支持这种处理模式。
向量化/批处理模型与大数据
大家熟悉的 Apache Hive 从 0.13.0 版本开始也支持向量化执行模型,参见 HIVE-4160。为了在 Hive 中使用 vectorized query execution,我们必须以 ORC 格式来存储我们的数据,并且将 hive.vectorized.execution.enabled 参数设置为 true(默认是不开启的)。
另外,Apache Spark 2.x 的 SQL 引擎开始也支持向量化执行模型,参见 Apache Spark作为编译器:深入介绍新的Tungsten执行引擎。其效率比 Iterator Model 高出数倍。由于篇幅的原因,我们将在另外一篇文章介绍 Apache Spark 的 Vectorized Query Execution。
猜你喜欢1、经典Hive-SQL面试题
2、在 Hive 中使用 OpenCSVSerde
3、如果你也想做实时数仓…
4、面试官问我Arrays.sort()为什么可以对int等数组进行排序,我跟面试官扯了半个小时
















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









