





我们的欲望,把彩虹的颜色,借给那只不过是云雾的人生。
- 泰戈尔《飞鸟集》
 面试官:用sql统计次日留存。不会?那用sql统计不同在线时长的用户数。还不会?没事下一题,用sql……
我的内心:可以用python吗,这样那样再那样就可以了,可是sql怎么搞哇
面试官:用sql统计次日留存。不会?那用sql统计不同在线时长的用户数。还不会?没事下一题,用sql……
我的内心:可以用python吗,这样那样再那样就可以了,可是sql怎么搞哇 世界上最遥远的距离莫过于,当我熟稔了常用sql语句写法之后,你却不再招实习生了……
拿之前的数据集,自问自答了不同业务需求,实现了诸如上面问到的次日留存、特征分箱一类的sql语句,另附python实现相同需求。
01
概览数据
还是之前《数据清洗与特征工程》中用到的数据,这次用用户行为表behavior和用户交易表trade。
世界上最遥远的距离莫过于,当我熟稔了常用sql语句写法之后,你却不再招实习生了……
拿之前的数据集,自问自答了不同业务需求,实现了诸如上面问到的次日留存、特征分箱一类的sql语句,另附python实现相同需求。
01
概览数据
还是之前《数据清洗与特征工程》中用到的数据,这次用用户行为表behavior和用户交易表trade。
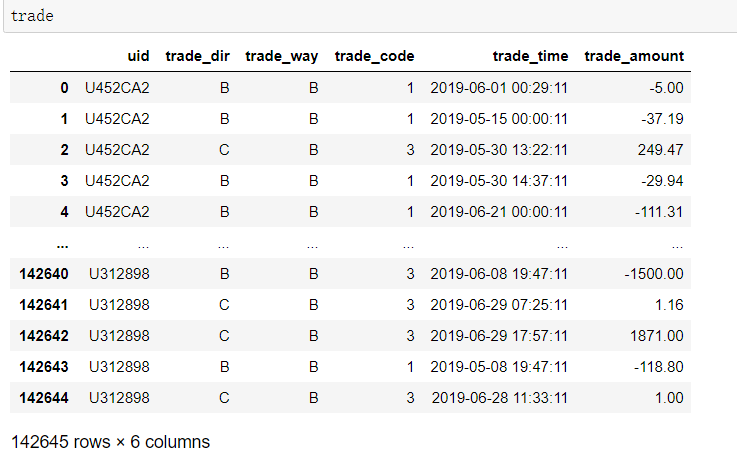
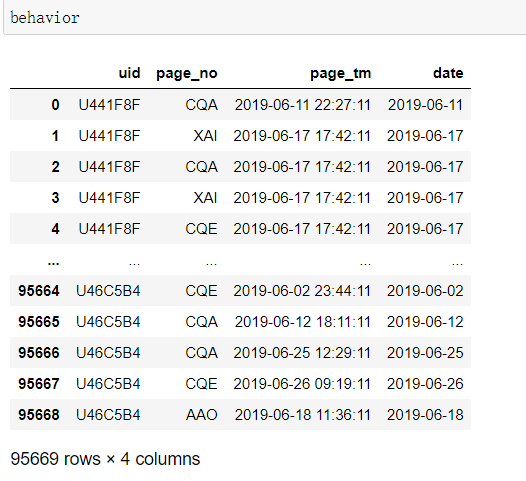 我将这两个表同样导入了mysql数据库,sql语句是通过pymysql连接到数据库写的。
所以先
连接数据库。
我将这两个表同样导入了mysql数据库,sql语句是通过pymysql连接到数据库写的。
所以先
连接数据库。

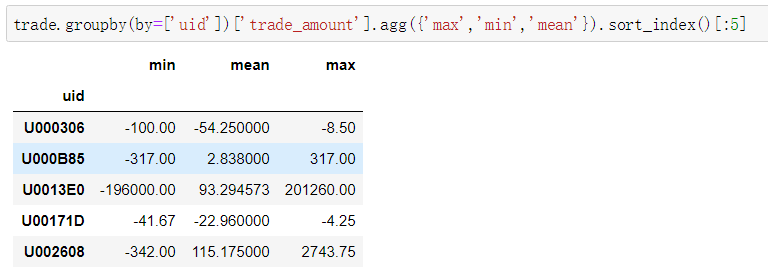 取前5个看一下,可以看到除了小数点保留位数不同其他都是一样的。
03
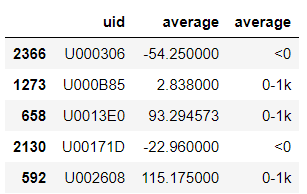
以平均交易额进行特征分箱,返回用户id,分箱结果和平均交易额
取前5个看一下,可以看到除了小数点保留位数不同其他都是一样的。
03
以平均交易额进行特征分箱,返回用户id,分箱结果和平均交易额
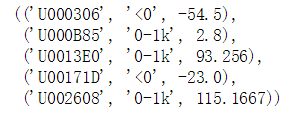
 04
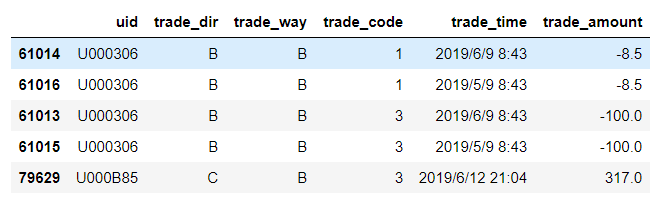
对用户进行分组并按其交易金额降序排列交易记录
04
对用户进行分组并按其交易金额降序排列交易记录
 05
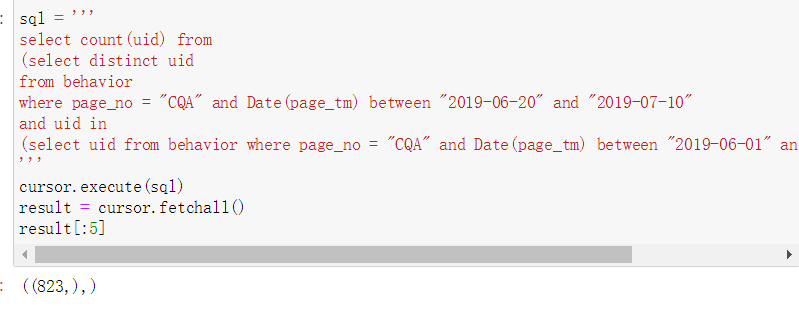
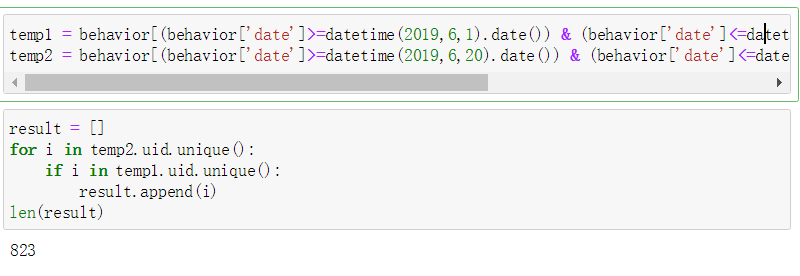
计算在6.1-6.15登陆过CQA页面且6.20-7.10也登陆过CQA的用户数量
05
计算在6.1-6.15登陆过CQA页面且6.20-7.10也登陆过CQA的用户数量
 06
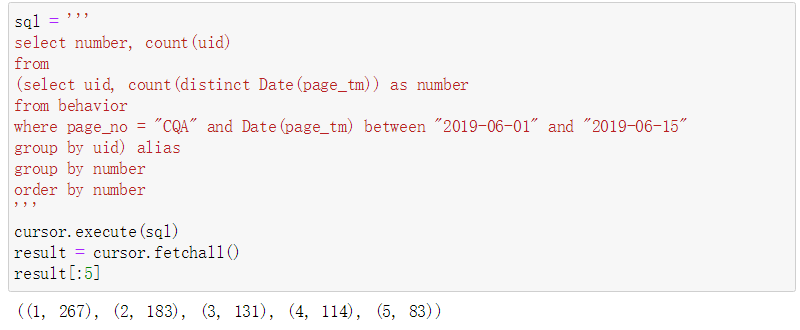
计算在6.1-6.15期间登陆过CQA页面的用户的累积登录天数分布
06
计算在6.1-6.15期间登陆过CQA页面的用户的累积登录天数分布
 07
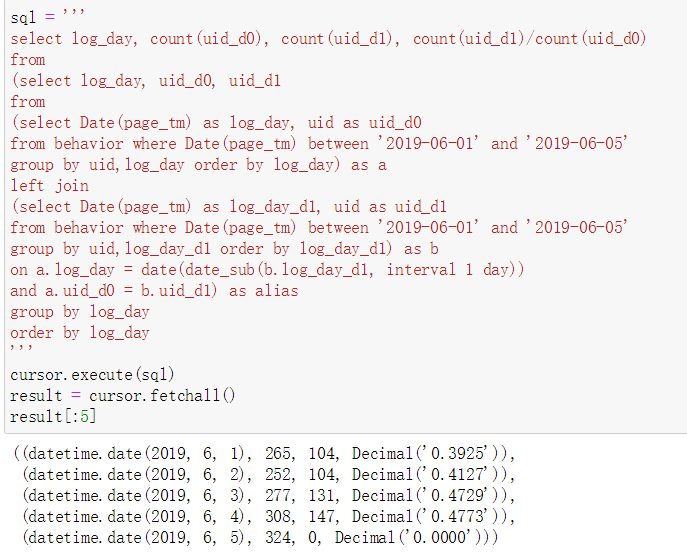
【次日留存】计算在6.1-6.5期间登录且第二天也登录了的用户数量
07
【次日留存】计算在6.1-6.5期间登录且第二天也登录了的用户数量
 08
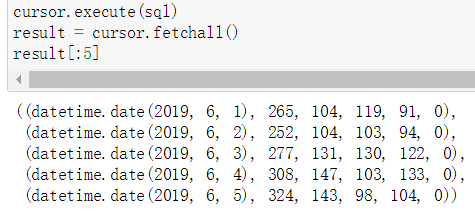
次日留存、三日留存、七日留存和三十日留存
08
次日留存、三日留存、七日留存和三十日留存
 09
Python实现次日留存、三日留存、七日留存和三十日留存
09
Python实现次日留存、三日留存、七日留存和三十日留存
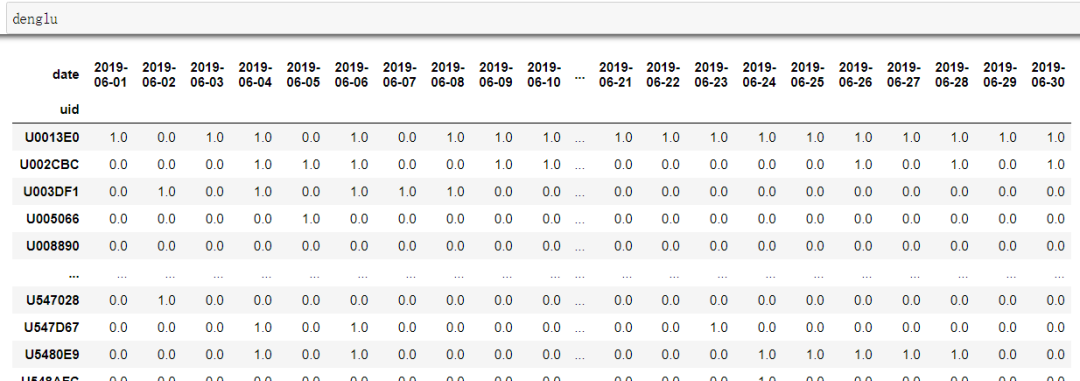 而temp0601的作用就是以0601为激活日期(即这天登录过的用户)统计留存,如果每天都需要统计可以循环传入每天的日期。至于这个变量怎么统计呢?这就是神奇的python时刻啦。
激活日期之后的每天的留存数量:
而temp0601的作用就是以0601为激活日期(即这天登录过的用户)统计留存,如果每天都需要统计可以循环传入每天的日期。至于这个变量怎么统计呢?这就是神奇的python时刻啦。
激活日期之后的每天的留存数量:
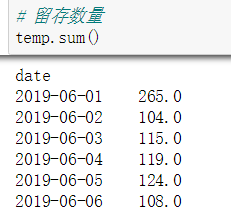 激活日期之后的每天的留存率:
激活日期之后的每天的留存率:
 The End
The End
面试官:用sql统计次日留存。不会?那用sql统计不同在线时长的用户数。还不会?没事下一题,用sql……
我的内心:可以用python吗,这样那样再那样就可以了,可是sql怎么搞哇
世界上最遥远的距离莫过于,当我熟稔了常用sql语句写法之后,你却不再招实习生了……
拿之前的数据集,自问自答了不同业务需求,实现了诸如上面问到的次日留存、特征分箱一类的sql语句,另附python实现相同需求。
01
概览数据
还是之前《数据清洗与特征工程》中用到的数据,这次用用户行为表behavior和用户交易表trade。
我将这两个表同样导入了mysql数据库,sql语句是通过pymysql连接到数据库写的。
所以先
连接数据库。
import pymysql
db=pymysql.connect(host='localhost',user='root', password='password',
port=3306, db='sqlpython', charset='utf8')
cursor = db.cursor()
sql = "select * from behavior"
cursor.execute(sql)
result = cursor.fetchall()
db.close()sql = '''
select uid, min(trade_amount), avg(trade_amount), max(trade_amount) from trade
group by uid
order by uid
'''
trade.groupby(by=['uid'])['trade_amount'].agg({'max','min','mean'}).sort_index()[:5]sql = '''
select uid,
(case
when average when average >=0 and average <1000 then "0-1k"
else "1k+" end), average
from (select uid, avg(trade_amount) as average from trade
group by uid) as alias
order by uid
'''
trd_avg = trade.groupby(by=['uid'])['trade_amount'].agg({'mean'}).rename(columns={"mean":"average"}).sort_values(by='average', ascending=False)
trd_avg.reset_index(inplace = True)
trd_avg_bin = pd.cut(trd_avg['average'], bins = [trd_avg['average'].min(),0,1000,trd_avg['average'].max()+0.1], right = False, labels=['<0','0-1k','1k+'])
result = pd.concat([trd_avg, trd_avg_bin], axis=1).sort_values(by='uid')[:5]sql = '''
select *,
row_number() over (partition by uid order by trade_amount desc)
as row_num
from trade
'''
trade.sort_values(by=['uid','trade_amount'], ascending=[True, False])[:5]sql = '''
select count(uid) from
(select distinct uid
from behavior
where page_no = "CQA" and Date(page_tm) between "2019-06-20" and "2019-07-10"
and uid in
(select uid from behavior where page_no = "CQA" and Date(page_tm) between "2019-06-01" and "2019-06-15")) alias
'''
temp1 = behavior[(behavior['date']>=datetime(2019,6,1).date()) & (behavior['date']<=datetime(2019,6,15).date()) &(behavior['page_no']=='CQA')]
temp2 = behavior[(behavior['date']>=datetime(2019,6,20).date()) & (behavior['date']<=datetime(2019,7,10).date()) &(behavior['page_no']=='CQA')]
result = []for i in temp2.uid.unique():if i in temp1.uid.unique():
result.append(i)
len(result)sql = '''
select number, count(uid)
from
(select uid, count(distinct Date(page_tm)) as number
from behavior
where page_no = "CQA" and Date(page_tm) between "2019-06-01" and "2019-06-15"
group by uid) alias
group by number
order by number
'''# 获得目标时间区间数据
behavior_target = behavior[(behavior['date']>=datetime(2019,6,1).date()) & (behavior['date']<=datetime(2019,6,15).date())]
behavior_temp = behavior_target[behavior_target['page_no']=='CQA'].groupby(by='uid')['date'].agg("nunique")
behavior_temp = behavior_temp.reset_index()
behavior_temp.rename(columns={'date':'number'},inplace=True)
behavior_temp.groupby('number')['uid'].agg('nunique')[:5]# 内层是获得当天登录的uid和第二天登录的uid# 如果第二天登录了返回和第一天一样的uid# 由于左连接如果的第二天没登录返回Null# 故计数时Null不被计数可以获得次日仍有登录的用户数# 有一个关键点,就是对用户id和日期一同分组以免丢失信息或者记录重复# python代码在最后面
sql = '''
select log_day, count(uid_d0), count(uid_d1), count(uid_d1)/count(uid_d0)
from
(select log_day, uid_d0, uid_d1
from
(select Date(page_tm) as log_day, uid as uid_d0
from behavior where Date(page_tm) between '2019-06-01' and '2019-06-05'
group by uid,log_day order by log_day) as a
left join
(select Date(page_tm) as log_day_d1, uid as uid_d1
from behavior where Date(page_tm) between '2019-06-01' and '2019-06-05'
group by uid,log_day_d1 order by log_day_d1) as b
on a.log_day = date(date_sub(b.log_day_d1, interval 1 day))
and a.uid_d0 = b.uid_d1) as alias
group by log_day
order by log_day
'''sql = '''
select log_day, count(uid_d0), count(uid_d1), count(uid_d3), count(uid_d7), count(uid_d30)
from
(
select log_day, uid_d0, uid_d1, uid_d3, uid_d7, uid_d30
from
(select Date(page_tm) as log_day, uid as uid_d0
from behavior where Date(page_tm) between '2019-06-01' and '2019-07-05'
group by uid,log_day order by log_day) as a
left join
(select Date(page_tm) as log_day_d1, uid as uid_d1
from behavior where Date(page_tm) between '2019-06-01' and '2019-07-05'
group by uid,log_day_d1 order by log_day_d1) as b
on a.log_day = date(date_sub(b.log_day_d1, interval 1 day))
and a.uid_d0 = b.uid_d1
left join
(select Date(page_tm) as log_day_d3, uid as uid_d3
from behavior where Date(page_tm) between '2019-06-01' and '2019-07-05'
group by uid,log_day_d3 order by log_day_d3) as c
on a.log_day = date(date_sub(c.log_day_d3, interval 3 day))
and a.uid_d0 = c.uid_d3
left join
(select Date(page_tm) as log_day_d7, uid as uid_d7
from behavior where Date(page_tm) between '2019-06-01' and '2019-07-05'
group by uid,log_day_d7 order by log_day_d7) as d
on a.log_day = date(date_sub(d.log_day_d7, interval 7 day))
and a.uid_d0 = d.uid_d7
left join
(select Date(page_tm) as log_day_d30, uid as uid_d30
from behavior where Date(page_tm) between '2019-06-01' and '2019-07-05'
group by uid,log_day_d30 order by log_day_d30) as e
on a.log_day = date(date_sub(e.log_day_d30, interval 30 day))
and a.uid_d0 = e.uid_d30
)
as alias
group by log_day
order by log_day
'''denglu = behavior.groupby(['uid','date'])['page_no'].agg(lambda x: 1).unstack().fillna(0)# denglu.columns[0]表示需要传入的日期就是激活日期
temp0601 = denglu[denglu[denglu.columns[0]]==1]














 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









