







知名的大数据中台技术分享基地,涉及大数据架构(hadoop/spark/flink等),数据平台(数据交换、数据服务、数据治理等)和数据产品(BI、AB测试平台)等,也会分享最新技术进展,大数据相关职位和求职信息,大数据技术交流聚会、讲座以及会议等。
背景
Impala是一个高性能的OLAP查询引擎,与其它SQL-on-Hadoop的ROLAP解决方案如Presto、SparkSQL 等不同的是,Impala对元数据(Metadata/Catalog)做了缓存,因此在做查询计划生成时不再依赖外部系统(如Hive、HDFS、Kudu),能做到毫秒级别的生成时间。另外缓存元数据也能极大减少对底层系统Master节点(Hive Metastore、HDFS NameNode、Kudu Master)的负载。
然而事情总有两面性,元数据缓存给Impala的系统设计引入了极大的复杂性。一方面在功能上为了维护缓存的正确性,引入了两个Impala特有的SQL语句:Invalidate Metadata 和 Refresh,另外还引入了query option SYNC_DDL。这些都让用户参与了缓存的维护。另一方面在架构设计上,有许多元数据相关的复杂设计,比如元数据的增量传播、缓存一致性的维护等。
在数仓规模较大时,Impala的元数据设计暴露出了许多问题,比如大表的元数据加载和刷新时间特别长、元数据的广播会被DDL阻塞导致广播延迟很大、元数据缓存导致节点Full GC或OOM等。因此Impala元数据设计也一直在演化之中,最新进展主要集中在Fetch-on-demand coordinator(又称local catalog mode、catalog-v2等)的设计,详见IMPALA-7127。
本文旨在介绍Impala元数据设计的基本概念,更多元数据相关的复杂设计将在后续文章中介绍。
Impala Server简介
Impala集群包含一个 Catalog Server (Catalogd)、一个 Statestore Server (Statestored) 和若干个 Impala Daemon (Impalad)。Catalogd 主要负责元数据的获取和DDL的执行,Statestored主要负责消息/元数据的广播,Impalad主要负责查询的接收和执行。
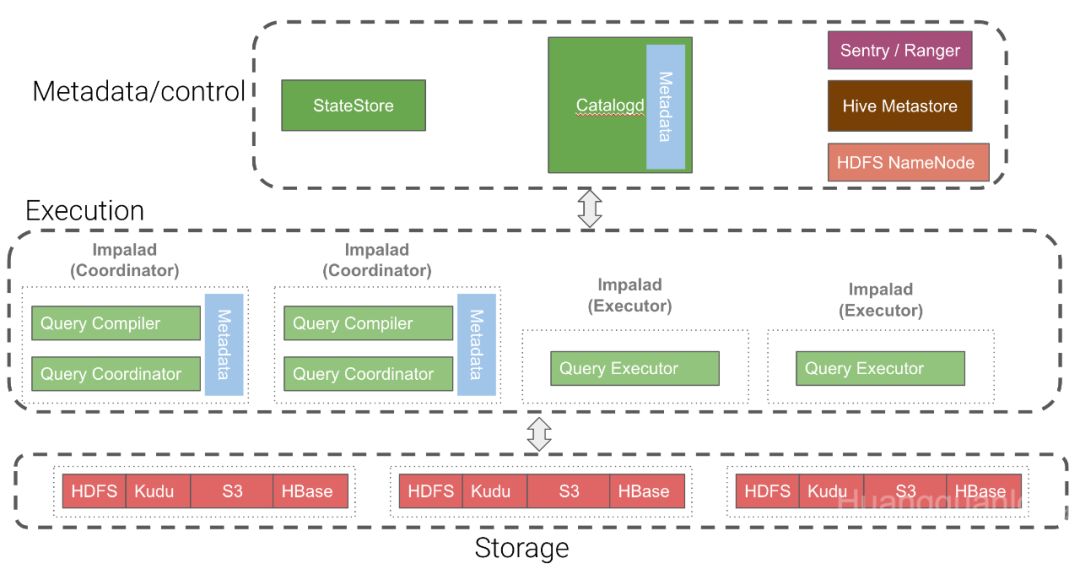
Impalad 又可配置为 coordinator only、 executor only 或 coordinator and executor(默认)三种模式。Coordinator角色的Impalad负责查询的接收、计划生成、查询的调度等,Executor角色的Impalad负责数据的读取和计算。默认配置下每个Impalad既是Coordinator又是Executor。生产环境建议做好角色分离,即每个Impalad要么是Coordinator要么是Executor,且可以以1:50的比例配置。更多细节可参考官方文档[1].
Impala元数据的构成
Impala的元数据缓存在catalogd和各个Coordinator角色的Impalad中。Catalogd中的缓存是最新的,各个Coordinator都缓存的是Catalogd内元数据的一个复本。如下图所示,元数据由Catalogd向外部系统获取,并通过 Statestored 传播给各个 Coordinator。
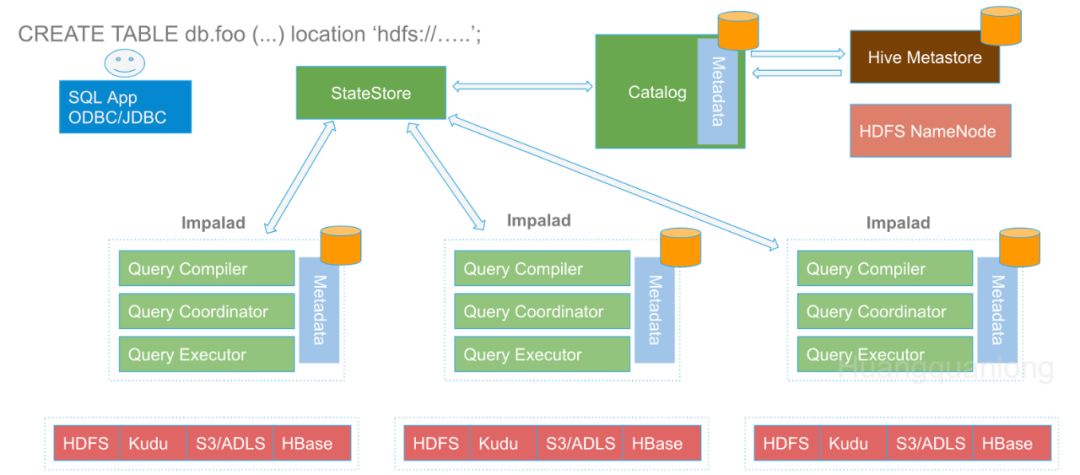
元数据缓存主要由Java代码实现,主体代码在FE中。另有一些C++实现的代码,主要处理FE跟BE的交互,以及元数据的广播。代码中把 Catalogd 和 Coordinator (Impalad) 中相同的元数据管理逻辑抽出来放在了 Catalog.java 中,Catalogd 里的实现是 CatalogServiceCatalog.java,Coordinator 里的实现是 ImpaladCatalog.java.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8698
8698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









