






大数据安全问题至关重要,基于Hive创建的数据仓库也很普遍,提起Hive权限控制,首先能想到的可能就是Apache Ranger,通过拦截Hive Thrift Sever请求的方式,进行SQL解析与权限认证。但对于Spark SQL来讲,更倾向于直接使用SQL访问Hive,而不是通过JDBC方式。因此对于Spark SQL访问Hive,就需要用户自己去解决安全问题。今天,笔者以解析Spark SQL查询计划的方式,来提取库表列的信息,从而去做权限认证。
在开始之前,先讲一下Spark SQL的逻辑计划:
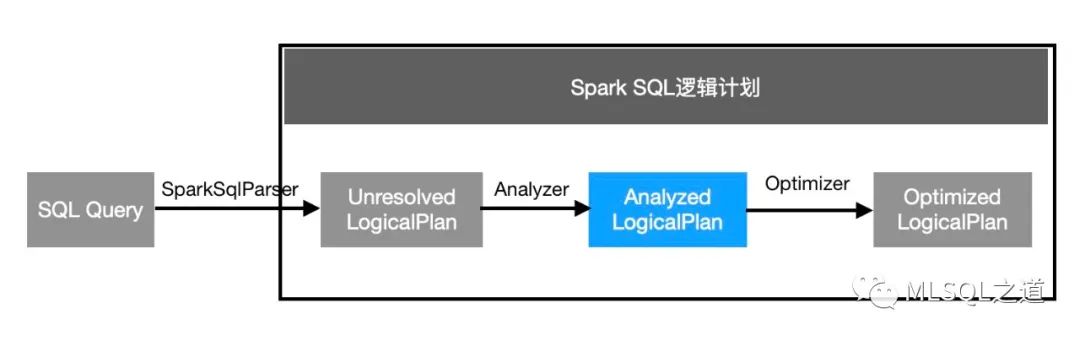
逻辑算子树的生成过程经历三个阶段:
由SparkSqlParser中的AstBuilder访问各种context节点,生成未解析的逻辑算子树,此时未绑定数据信息(数据源信息、列信息等);
Analyzer在Unresolved LogicalPlan上应用一系列Rule,绑定数据信息(数据源信息、列信息等),生成解析后的逻辑算子树;
应用各种优化Rule在保证语义正确的前提下对一些低效的逻辑计划进行转换等,生成优化的逻辑算子树。
//表信息CREATE TABLE if not exists respect.test(id string,name string, age int, dt string)//Spark SQL代码 val spark = SparkSession .builder() .enableHiveSupport() .master("local[*]") .getOrCreate() val sql = """ |select name, | max_age, | "mlsql" mlsql | from( | select name, | max(age) max_age | from respect.test | where dt <= 20200501 | group by name) t """.stripMargin val df = spark.sql(sql) df.explain(true)== Parsed Logical Plan =='Project ['name, 'max_age, mlsql AS mlsql#1]+- 'SubqueryAlias `t` +- 'Aggregate ['name], ['name, 'max('age) AS max_age#0] +- 'Filter ('dt <= 20200501) +- 'UnresolvedRelation `respect`.`test`== Analyzed Logical Plan ==name: string, max_age: int, mlsql: stringProject [name#12, max_age#0, mlsql AS mlsql#1]+- SubqueryAlias `t` +- Aggregate [name#12], [name#12, max(age#13) AS max_age#0] +- Filter (cast(dt#14 as int) <= 20200501) +- SubqueryAlias `respect`.`test` +- HiveTableRelation `respect`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#11, name#12, age#13, dt#14]== Optimized Logical Plan ==Aggregate [name#12], [name#12, max(age#13) AS max_age#0, mlsql AS mlsql#1]+- Project [name#12, age#13] +- Filter (isnotnull(dt#14) && (cast(dt#14 as int) <= 20200501)) +- HiveTableRelation `respect`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#11, name#12, age#13, dt#14]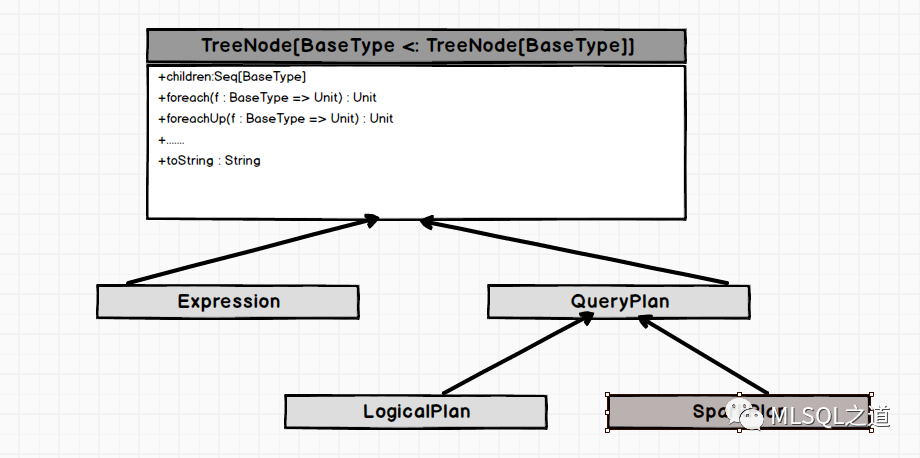

从上图中可以看出,逻辑计划属于TreeNode体系,因此它可以使用TreeNode的所有方法。
下面来看MLSQL中是如何实现的(MLSQLDFParser类):
def extractTableWithColumns(df: DataFrame) = { val tableAndCols = mutable.HashMap.empty[String, mutable.HashSet[String]] val relationMap = new mutable.HashMap[Long, String]() val analyzed = df.queryExecution.analyze(HiveTableRelation `respect`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#17, name#18, age#19, dt#20])
//只对Hive表处理,临时表不需要授权 analyzed.collectLeaves().foreach { lp => lp match {case r: HiveTableRelation => r.dataCols.foreach(c => relationMap.put(c.exprId.id , r.tableMeta.identifier.toString().replaceAll("`", "")) )case r: LogicalRelation => r.attributeMap.foreach(c =>if (r.catalogTable.nonEmpty) { relationMap.put(c._2.exprId.id , r.catalogTable.get.identifier.toString().replaceAll("`", "")) } )case _ => } }//如果查询SQL中包含Hive表if (relationMap.nonEmpty) { val neSet = mutable.HashSet.empty[NamedExpression] analyzed.map { lp => lp match {case wowLp: Project => wowLp.projectList.map { item => item.collectLeaves().foreach( _ match {case ne: NamedExpression => neSet.add(ne)case _ => } ) }case wowLp: Aggregate => wowLp.aggregateExpressions.map { item => item.collectLeaves().foreach( _ match {case ne: NamedExpression => neSet.add(ne)case _ => } ) }case _ => } }//相当于记录列的exprId与列名的对应关系 val neMap = neSet.zipWithIndex.map(ne => (ne._1.exprId.id ,ne._1)).toMap relationMap.foreach { x =>if (neMap.contains(x._1)) { val dbTable = x._2 val value = tableAndCols.getOrElse(dbTable, mutable.HashSet.empty[String]) value.add(neMap.get(x._1).get.name) tableAndCols.update(dbTable, value) } } } tableAndCols }println(extractTableWithColumns(df))//执行输出的结果为:Map(respect.test -> Set(name, age)) (当然这里面有一些要注意的地方,在做某些分析时,比如union、window等就需要特殊处理)
(当然这里面有一些要注意的地方,在做某些分析时,比如union、window等就需要特殊处理)
















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









