





利用Pandas将数据进行分组,并将各组进行聚合或自定义函数处理。
导入模块
import pandas as pd
缩写
df表示Dataframe对象
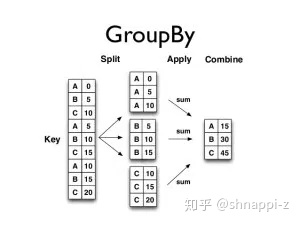
分组
- df.groupby('col1'): 根据col1列将df全部列分组(默认:axis=0行)
- df['col2'].groupby('col1'): 根据col1列对df中col2列分组
- =df['col2'].groupby(df['col1'])
- =df.groupby('col1')[['col2']]
- =df.groupby('col1')['col2']
- df.groupby(['col1','col2']): 根据col1,col2列将df分组
- dict(list(df.groupby('col1'))): 将分组存为key为组名,value为group的字典
- for name,group in df.groupby('col1'): 遍历分组名+组
- for (n1,n2),group in df.groupby(['col1','col2']): 遍历取层级分组名+组
- df.groupby(df.types, axis=1): 根据数据类型对df列分组
- df.groupby(dict/list,axis=1):以字典或列表对df各列分组
- dict中key为列名,value为分类标签,根据分类标签将列分类
- df.groupby(len):计算df索引值的字符串长度,以长度值为分组及组名
- df.groupby([len,list]):混和使用,层次化索引(0层:len,1层,list)
- df.groupby(level='num',axis=1):层次化索引df中,以索引层名为num的列分组
- groupby(group_keys=False): 分组列不成为索引
- =reset_index()
聚合
>>>grouped = df.groupby('col1')
- grouped.mean() :分组计算均值
- grouped.agg('mean'):同上
- grouped.size():分组大小
- grouped.count():分组中非NA的数量
- grouped.median():分组中位数
- grouped.std():分组无偏标准差(分母n-1)
- grouped.var():分组无偏方差
- grouped.min():非NA最小值
- grouped.max():非NA最大值
- grouped.prod():非NA值的积
- grouped.first():第一个非NA值
- grouped.last():最后一个非NA值
- grouped('col2').quantile(0.5):以col2列的0.5分位数聚合
自定义函数
- grouped.agg(func):以自定义的func函数聚合
- func 是以sereis为基础的操作
- 默认聚合后的列名为func名
- grouped.agg([(name,func)]):指定列名,不用func名
- =grouped.aggregate(func)
- grouped[col].agg([func1,‘mean','std',...,funcn]): 对分组列col使用多个聚合函数
- grouped[col1,col2].agg([func1,funcn]): 分组后的多列使用多个聚合函数
- grouped.agg({col:func1,col2:func2}): 对col1列用func1聚合,col2列用func2聚合
分组级运算
本质:将一维数组简化为标量值的函数
- grouped.transform(func): 将聚合的标量值广播
- grouped.apply(func,param1,param2....): 对各个分组列使用func函数,param是func的参数
- groupby + pd.cut : 将数据分为等距区间分组
- groupby + pd.qcut: 将数据根据分位数区间分组
透视表与交叉表
- df.pivot_table() : 透视表
- rows:行索引
- cols:列索引
- margins:总计行列数据,默认平均值
- fill_value:填补缺失值
- pd.crosstab(df.col1,df.col2) : 交叉表计算分组频率的特殊透视表














 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









