






一、Pod控制器有什么用,是什么?
通过内部和解(reconciliation loop)不断地监控Kubernetes集群内资源对象以保证集群中的资源对象的状态无限接近于用户所期望的状态,特别是当Pod对象遭到意外删除或者工作节点发生故障的时候。
Pod控制器是由Master节点的kube-controller-manager组件提供的,常见的控制器有Replication Controller、ReplicaSet、Deployment、DaemonSet、StatefulSet、Job、CronJob等。
二、kube-controller-manager 组件
kube-controller-manager是一个独立的单体守护进程,包含了众多功能不同的控制器类型用于各类和解任务。
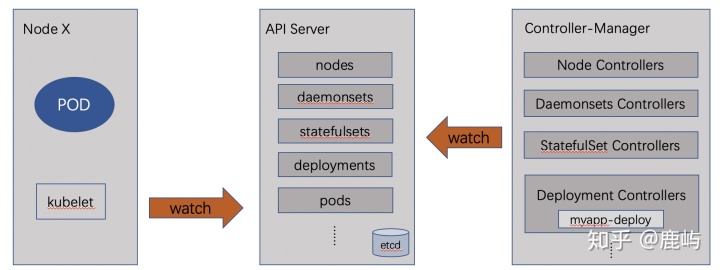
每个控制器通过API Server提供的接口获取到资源对象的状态,并在状态发生变化时,尝试让资源对象的当前状态无限接近期望状态。实现的过程(List-watch是Kubernetes实现的核心机制之一):
- 资源对象状态发生变动时--->API Server将状态写入etcd中,并且通过水平触发机制(level-triggered)将事件主动通知给相关的客户端程序
- 控制器通过API Server的watch接口实时监控目标资源对象的变动并在必要时执行和解
三、Pod控制器资源通常包括三个基本部分
- 标签选择器:匹配并关联Pod资源对象
- 期望的副本数:期望运行的Pod资源的对象数量
- Pod模板:用于新建Pod资源对象的Pod模板
- 其他字段因不同的控制器而不同,后面介绍不同的控制器详细再说
四、ReplicaSet控制器
ReplicaSet相比于老版本的控制器ReplicationController(已弃用),除了额外支持基于集合的标签选择器之外其他都功能都一样。当然更高级别的控制器Deployment是基于ReplicaSet实现的。
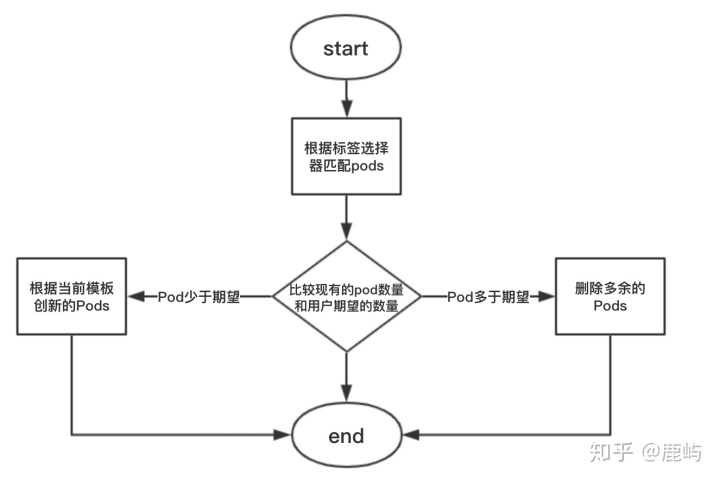
ReplicaSet能够实现以下功能:
- 确保Pod资源对象的数量精确反映期望值
- 确保Pod健康运行:探测到管控的Pod对象因为所在工作节点故障而不可用时,会自动请求由调度器于其他工作节点创建缺失的Pod副本
- 弹性伸缩:扩容或者缩容Pod数量,另外可以通过HPA(HroizontalPodAutoscaler)来实现Pod资源规模的自动伸缩
一个ReplicaSet的资源配置文件yaml模板:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-demo
spec:
replicas: 2
selector:
matchLabels:
app: rs-demo
minReadySeconds: 3
template:
metadata:
labels:
app: rs-demo
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v2
ports:
- name: http
containerPort: 80其中说下minReadySeconds这个参数指的是新建的Pod对象在启动多久后若容器未出现异常即被视为就绪,默认是0秒。启动这个控制器后,若修改replicas期望副本数apply或者replace后直接生效。但是修改Pod模板只会对后来新建的Pod副本产生影响。
其次,使用kubectl label命令强行修改隶属于控制器的Pod对象的标签会导致该Pod脱离控制器的管控,该Pod成为自主式Pod对象。
另外,如果想要升级容器应用一般会修改image的版本号,但这种修改仅影响之后由其创建的Pod对象,对已有的副本不会产生作用。所以,升级应用需要手动先删除之前的Pod。
最后,使用kubeclt scale replicasets rsname --replicas --current-replicas的命令可实现Pod的实时扩容和缩容。使用kubectl delete replicasets rs_name --cascade=false可以删除控制器(--cascade作用是要不要级联删除控制器下的所有管控的Pods)
五、Deployment控制器(管理无状态的应用使用最多的控制器)
1、Deployment控制器相较于ReplicaSet控制器多了以下几种特性:
- 事件和状态查看:可以查看应用升级时的详细进度和状态
- 回滚:升级应用出现问题,支持回滚到指定的历史版本
- 版本记录:记录每次操作Deployment的日志,以便后续回滚
- 暂停和继续:对于一次升级应用,能够随时暂停和继续
- 自动更新:包括重建更新机制(Recreate)和滚动更新机制(RollingUpdate)
2、一个Deployment的资源配置文件yaml模板:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-demo
spec:
replicas: 3
selector:
matchLabels:
app: deployment-demo
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: deployment-demo
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80需要详细讲的配置项:
- strategy 更新策略:
- Recreate:重新重建,这种方式先把旧版本全部删除之后,再创建新的版本的Pod。好处是不存在中间状态,用户要么访问到新的版本要么访问到旧的版本。缺点是更新过程可能会有短暂的服务不可用的情况。
- RollingUpdate:默认的策略,滚动更新。这种方式是在删除一部分旧版本的Pod资源的同事补充创建一部分新的Pod资源。优势是升级期间,容器提供的服务不会中断。缺点是,要求应用程序能够应对新旧版本同时工作时的兼容问题。
- strategy.maxSurge:升级期间集群中存在的总的Pod的数量最多能够超过期望值多少。假如期望值是3,maxSurge的值是1,那么集群中新老Pod总共存在的数量不能超过4。
- strategy.maxUnavailable:集群中最少的可用的Pod。如果期望值是3,maxUnavailable的值是1,那么集群中至少要保证2个可用的Pod
- revisionHistoryLimit:定义控制器可保存的历史版本数(注意,为了能够保存升级的历史,需要在创建Deployment对象时加上--record命令)
3、升级Deployment的步骤
(1)修改镜像文件的版本
kubectl set image deployments deployment_name image_key=image_value(2)打印滚动更新过程中的状态信息
kubectl rollout status deployment deployment_name(3)监控升级过程中的Pod对象的变动过程
kubectl get deployments deployment_name --watch4、金丝雀发布
Deployment可以自定义控制更新过程中的滚动节奏,比如暂停(pause)或者继续(resume)更新操作。比如,待一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一小部分新版本的应用。然后,再根据用户特征筛选出一部分用户的请求路由至新版本的Pod应用,并持续观察是否能稳定按期望的方式运行。确定没有问题后再继续完成余下的Pod资源的滚动更新,否则立即回滚操作,这就是所谓的金丝雀发布。金丝雀发布过程通过建议采用"先添加再删除,且可用Pod资源对象总数不低于期望"的方式进行。
金丝雀发布步骤:
(1)修改容器镜像版本后立即暂停更新进度
kubectl set image deployment deployment_name image_key=image_value && kubectl rollout pause deployment deployment_name(2)查看更新状态
kubectl rollout status deployment deployment_name(3)将一部分用户的流量引入到这些Pod之上,保证没问题后再继续此前的滚动更新
kubectl rollout resume deployments deployment_name(4)如果更新过程发现问题,查看历史版本并立即回滚至指定版本
kubectl rollout history deployment deployment_name
kubectl rollout undo deployment deployment_name --to-revision=六、DaemonSet控制器
用于集群中的全部节点或者满足某些条件的节点都运行一份指定的Pod的资源副本,并且新的节点加入集群时会自动创建一个Pod资源副本,删除节点的时候也会自动回收。主要使用场景包括:
- 运行集群存储的守护进程
- 运行日志收集器守护进程
- 运行监控系统的代理守护进程
配置清单和滚动回滚等操作基本同Deployment一致,所以不再这里赘述
七、Job控制器
Job控制器用于调配Pod对象运行一次性任务,容器中的进程正常运行结束后不会对其进行重启。若容器中的进程因为错误而终止,则需要配置确定是否要重启。
Job控制器对象主要有两种:
- 单工作队列地串行式Job:多个一次性的作业方式串行执行多次作业,直到满足期望的次数
- 多工作队列的并行式Job:多个工作队列并行运行多个一次性作业
一个Job的资源配置文件yaml模板:
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
completions: 5
parallelism: 2
activeDeadlineSeconds: 100
backoffLimit: 5
template:
spec:
containers:
- name: myjob
image: alpine
command: ["/bin/sh", "-C", "sleep 60"]
restartPolicy: Never需要说明一下的配置项:
- completions:总的执行的作业数
- parallelism:作业执行的并行度
- activeDeadlineSeconds:最大活动时间长度,超出此时长的作业将被终止
- backoffLimit:将作业标记为失败状态之前的重试次数,默认为6
八、CronJob控制器
CronJob可以类似于Linux操作系统的周期性任务作业计划的方式控制其运行的时间点和重复运行的方式,主要参数说明:
- jobTemplate:Job控制器模板
- schedule:Cron格式的作业调度运行的时间点
- concurrencyPolicy:并发执行策略,用于定义前一次作业尚未完成时如何执行下一此任务。默认是Allow,即允许前后Job,甚至是属于同一个CrontJob的更多Job同时运行。如果设置为Forbid则禁止前后两个Job同时运行,如果前一个尚未结束,后一个不会启动(跳过),如果设置为Replace,则后一个Job会替代前一个Job,即终止前一个,启动后一个。
- failedJobHistoryLimit:为失败的任务执行保留的历史记录数,默认是1
- successfulJobsHistoryLimit:为成功的任务执行保留的历史记录数,默认是3
- startingDeadlineSeconds:因各种原因缺乏执行作业的时间点所导致的启动作业错误的超时时长,会被记入错误历史记录
- suspend:是否挂起后续的任务执行,默认是false















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









