





环境配置
1.本文使用的python版本是python3
2.使用到的依赖包如下:
requestsscrapy
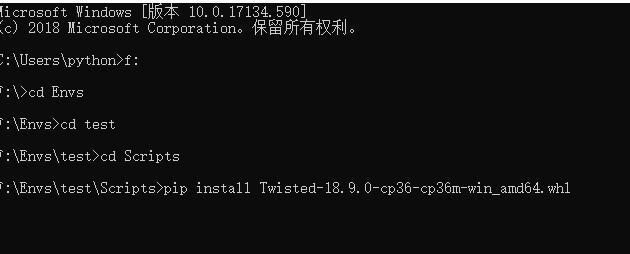
在安装 scrapy 之前需要先安装 Twisted 地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted。下载符合自己版本的 Twisted,然后将其放入 python 安装目录中,先使用命令安装 pip install Twisted。安装完之后,scrapy 就很容易安装了,安装命令如下: pip install scrapy。
本文要点
1.xpath 基本语法和用法示例
2.使用 xpath 爬取《盗墓笔记》实例
xpath 基本语法
xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。xpath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式,几乎所有我们想要定位的节点都可以用 xpath 来选择。首先我们来看下 xpath 的基本语法。
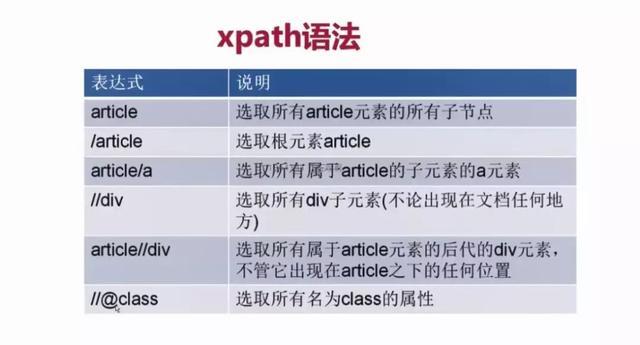

在这里列出了xpath的常用匹配规则,例如 / 代表选取直接子节点,// 代表选择所有子孙节点,. 代表选取当前节点,.. 代表选取当前节点的父节点,@ 则是加了属性的限定,选取匹配属性的特定节点。
xpath 用法举例
接下来我们以豆瓣电影为例子,来熟悉一下 xpath 基本用法:
打开网页 https://movie.douban.com/top250
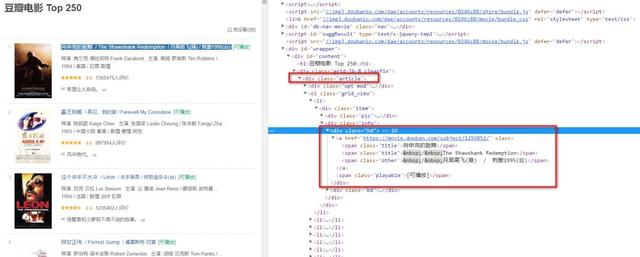 豆瓣电影top250
豆瓣电影top250
首先需要找到我们所匹配的内容在 html 中的位置。
从图片中可以看到排名第一的电影标题是在标签为 div,class 属性为 *hd中的 a 标签中所有的 span 标签里面!
然后我们需要一级一级往上面找,因为这个层级太深了,有时候会匹配不到我们所需要的内容。
我们最开始匹配的标签要满足它的所有特征加起来是唯一的。
很容易看到属性为 article 正是我们所需要的标签!因为找不到第二个 div 标签且 class 属性为 article 的标签! 因为是文本内容,所以要用 text(),获取电影标题语法如下 :
1html.xpath(同理,我们获取电影详情链接的语法,因为是属性,所以要用 @属性值:
1html.xpath(我们可以将其加入到爬虫代码中,效果如下:
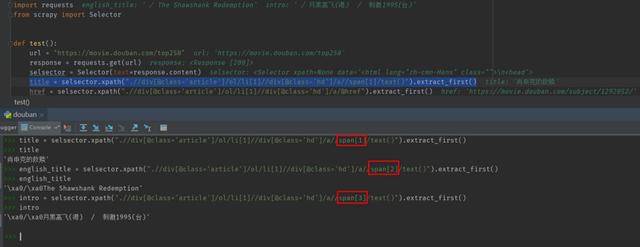 豆瓣电影爬虫
豆瓣电影爬虫
使用 xpath 爬取盗墓笔记
目标地址:
盗墓笔记全篇 http://seputu.com/
总体思路:
1.分析网页结构,取出我们需要的标题,以及下一步需要用到的链接
2.根据章节的链接地址,再爬取出章节小说
首先分析我们需要爬取的内容,在网页中的位置。
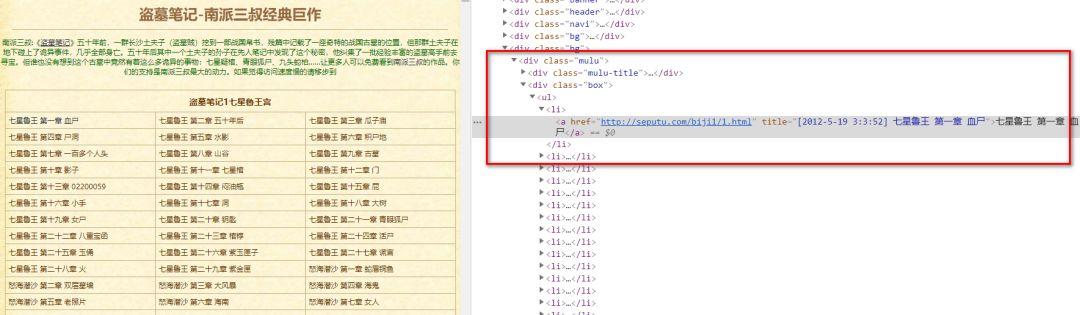
经过上面的讲解,相信大家很容易就可以写出 xpath 的语法。因为我们是要爬取所有小说内容,所以我们要循环所有 li 标签里面的内容!
1html.xpath(遍历这个列表,取出我们所需要的章节,详细链接
1li_list = selector.xpath(接下来,从详情链接中取出小说内容,即完成了这个小爬虫!
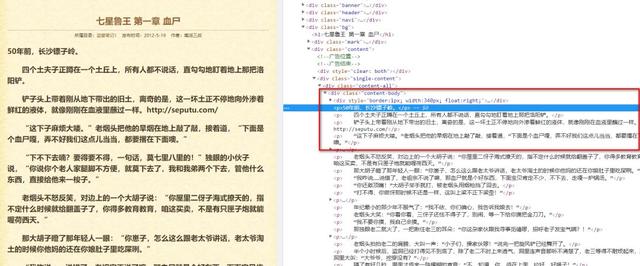
1p_list = selector.xpath(最重要的分析部分完成了,接下来主要就是将所有的内容放入代码中,然后保存到本地就完成了。

最终爬虫代码如下:
1总结
本文主要介绍了 python 中解析库 xpath 的使用方法和示例,用法其实很简单,关键在于多多练习!下篇文章打算分享另一个解析库 css 的用法,以及和 xpath 之间的区别,欢迎关注!
如果觉得不错或对你有帮助,请分享给更多人
关注[Python编程与实战]
从零开始学Python,提升Python技能















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









