






 本文介绍了Python爬虫的三大基础库——Requests、BeautifulSoup和Lxml的使用方法。Requests库用于请求网页数据,BeautifulSoup库对网页进行解析以获取结构化数据,而Lxml库则提供XML和HTML的解析能力。通过实例演示了如何处理404错误,以及如何爬取酷狗音乐排行榜的歌曲信息。
本文介绍了Python爬虫的三大基础库——Requests、BeautifulSoup和Lxml的使用方法。Requests库用于请求网页数据,BeautifulSoup库对网页进行解析以获取结构化数据,而Lxml库则提供XML和HTML的解析能力。通过实例演示了如何处理404错误,以及如何爬取酷狗音乐排行榜的歌曲信息。
爬虫有三大基础库Requests、BeautifulSoup和Lxml,这三大库对于初学者使用频率最高,现在大家一起来看看这基础三大库的使用。
- Requests库
Requests库的作用就是请求网站获取网页数据。
Code:res=requests.get(url)
返回:
- 返回200说明请求成功
- 返回404、400说明请求失败
Code:res=request.get(url,headers=headers)
添加请求头信息伪装为浏览器,可以更好的请求数据信息
Code:res.text
详细的网页信息文本
- BeautifulSoup库
BeautifulSoup库用来将Requests提取的网页进行解析,得到结构化的数据
Soup=BeautifulSoup(res.text,’html.parser’)
详细数据提取:
infos=soup.select(‘路径’)
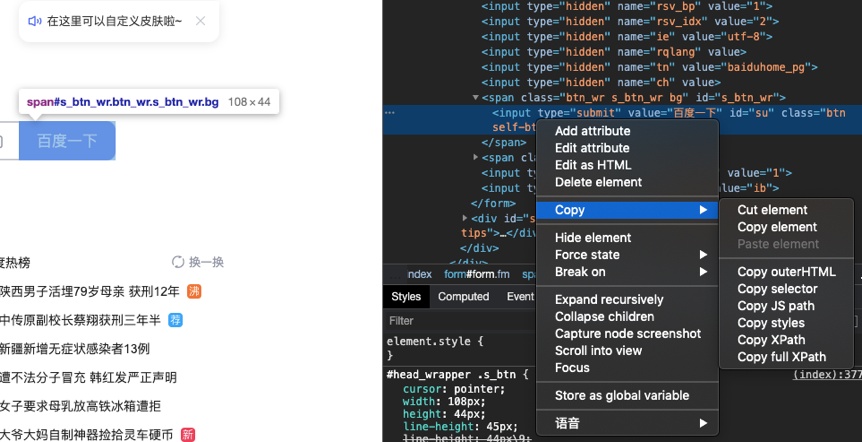
路径提取方法:在固定数据位置右键-copy-copy selector
- Lxml库
Lxml为XML解析库,可以修正HTML代码,形成结构化的HTML结构

Code:
From lxml import etree
Html=etree.HTML(text)
Infos=Html.xpath(‘路径’)
路径提取方法:在固定数据位置右键-Copy-Copy Xpath
实践案例:
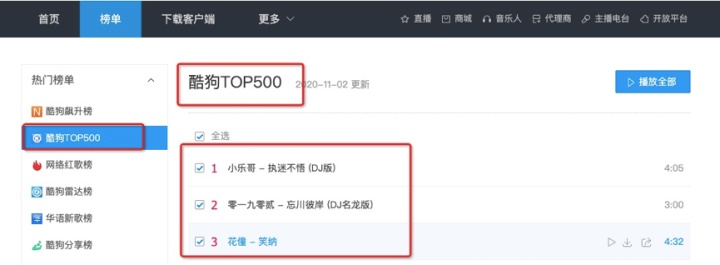
1、爬取酷狗榜单TOP500音乐信息
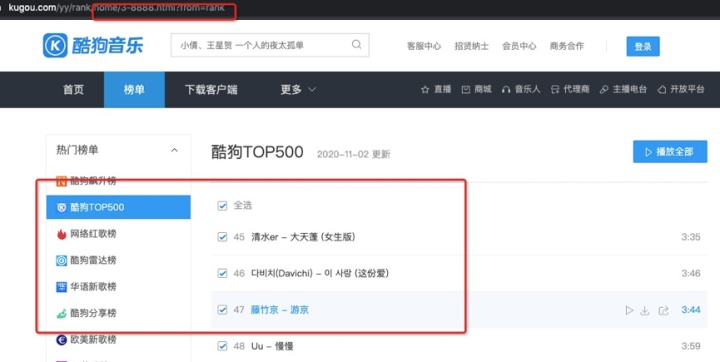
2、网页无翻页,如何寻找URL,发现第一页URL为:
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
尝试把1换成2,可以得到新的网页,依次类推,得到迭代的网页URL
3、爬取信息为歌曲名字、歌手等
4、详细代码如下:
import requests
from bs4 import BeautifulSoup
import time
headers={
"User-Agent": "web提取"
}
def get_info(url):
print(url)
#通过请求头和链接,得到网页页面整体信息
web_data=requests.get(url,headers=headers)
#print(web_data.text)
#对返回的结果进行解析
soup=BeautifulSoup(web_data.text,'lxml')
#print(soup)
#找到具体的相同的数据的内容位置和内容
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
#提取具体的文字内容
for rank, title, time in zip(ranks, titles, times):
data = {
'rank': rank.get_text().strip(),
'singer': title.get_text().split('-')[0],
'song': title.get_text().split('-')[1],
'time': time.get_text().strip()
}
print(data)
if __name__=='__main__':
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i) for i in range(1, 2)]
for url in urls:
get_info(url)
time.sleep(1)
















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









