






医维视界致力面向广大医生群体提供IT相关的解决方案包括大数据处理、数据分析、IT应用工具等等。充分利用AI等相关技术赋能医疗行业,提高医疗从业者的工作效率。
相信很多医生都要和excel打交道, 那么使用python来进行excel批量处理可以做到事半功倍。
那么这里介绍一下如何使用python处理excel的常规操作,以及为什么excel就可以的操作非要用python呢
因为如下几点:
1. 在操作excel不可以回退版本,没有版本的概念可能改到最后发现不是自己想要的但也不知道该回退到那个版本了
2. excel在处理数据量稍大的时候就特别慢,经常一个删除列的操作就卡死了
这里需要注意 python的环境下预先安装Pandas
Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建。
1. 导入pandas库
代码:
import pandas as pd2. 导入excel的数据
代码:
data = pd.read_excel("./seer.xlsx",sheet_name = 0)3. 查看数据
代码:
data.head()输出效果:
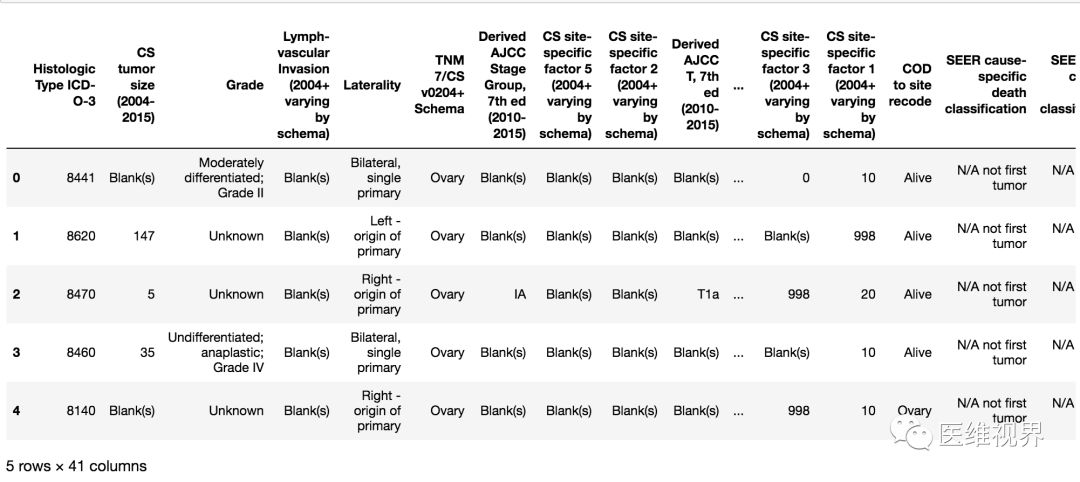
4. 查看首三行数据
代码:
data.head(3)输出效果:
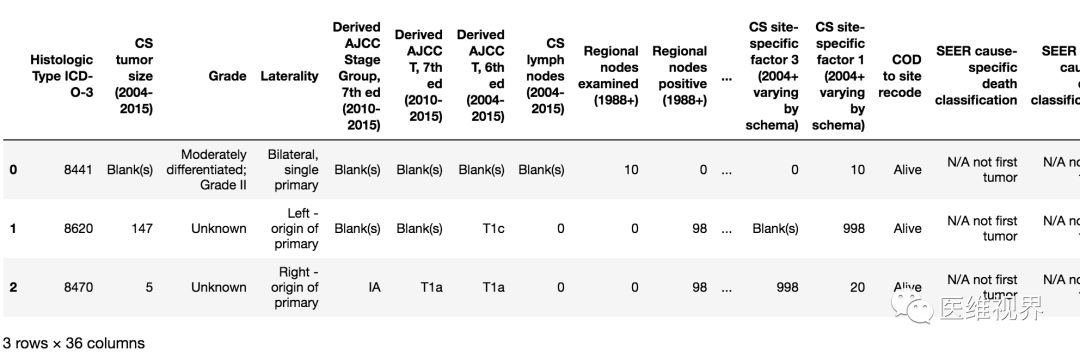
5. 查看最后三行数据
代码:
data.tail(3)输出效果:
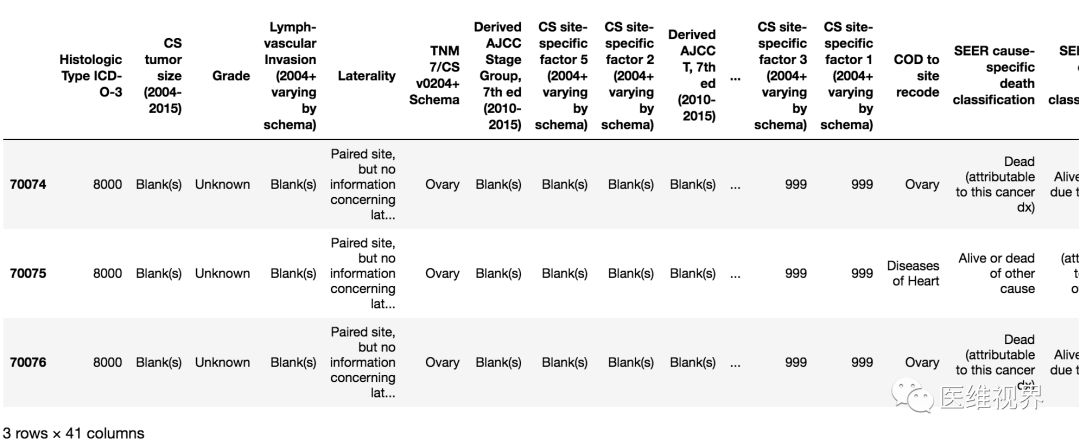
6. 查看data各列的属性(包括均值,标准差,频率等)
代码:
data.describe(include = "all")输出效果:
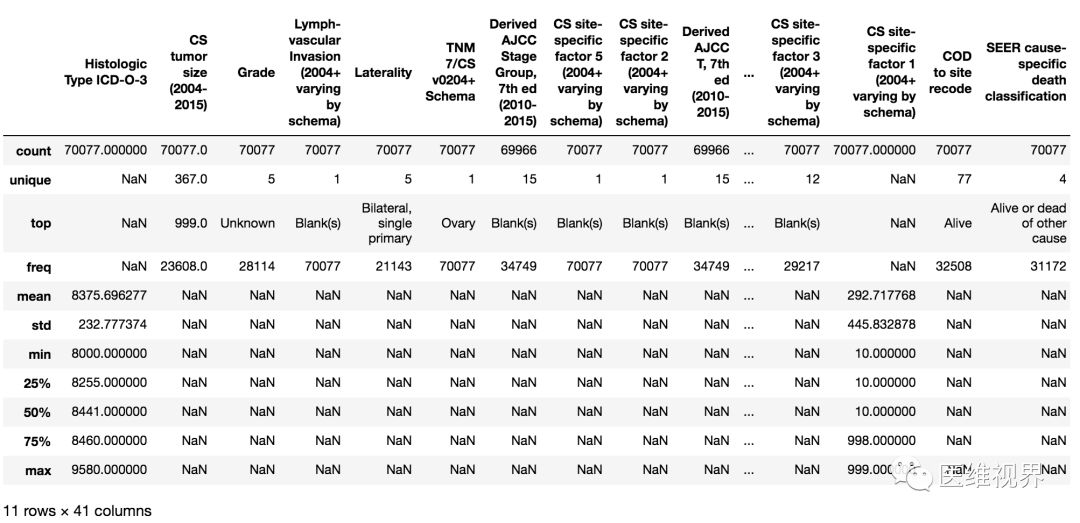
7. 选择数据:选择第0到2行数据
代码:
data[0:2]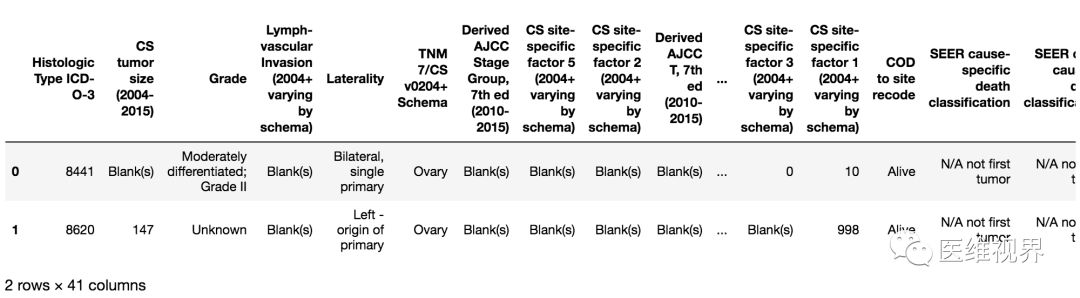
8. 按照第一列排序数据(从低到高)
代码:
data.sort_values(by = "Histologic Type ICD-O-3")[0:5]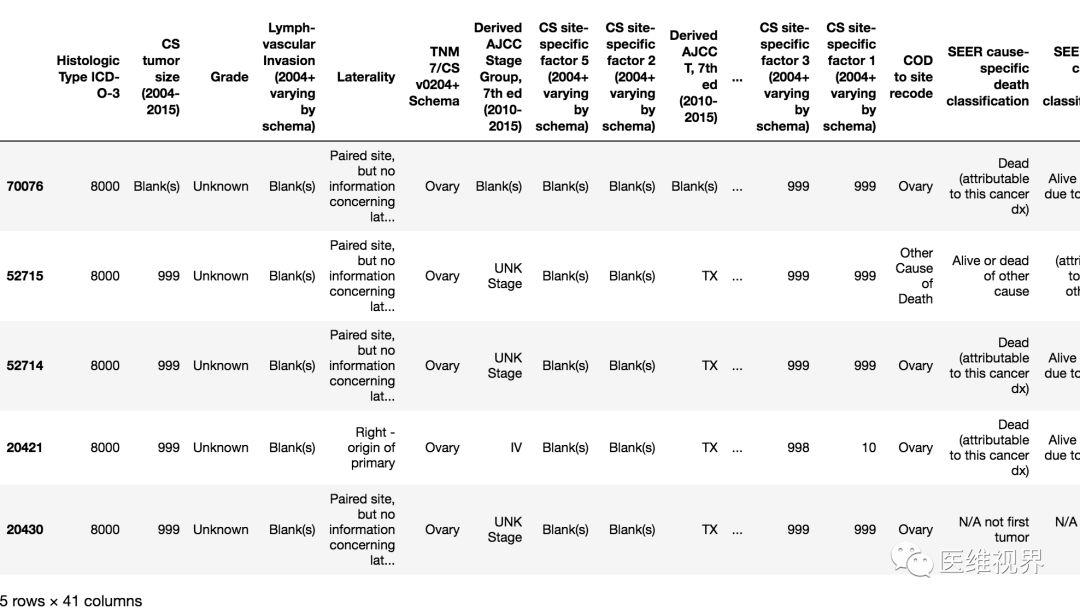
整体可以运行的代码块如下:
import pandas as pd data = pd.read_excel("./important.xls",sheet_name = 0)print data.head()如有不解的地方欢迎后台留言哈
想了解更多医疗数据数据分析方法,敬请关注公众号:医维视界
















 3175
3175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









