







model
Parameter 和 Buffer
https://zhuanlan.zhihu.com/p/89442276
优化器
SGD
https://blog.csdn.net/weixin_39228381/article/details/108310520
Adam
https://blog.csdn.net/weixin_39228381/article/details/108548413
lr_scheduler
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
学习率的调整策略。参考https://blog.csdn.net/happyday_d/article/details/85267561
调整策略参考:https://blog.csdn.net/zisuina_2/article/details/103258573
- 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和余弦退火CosineAnnealing。
- 自适应调整:自适应调整学习率 ReduceLROnPlateau。
- 自定义调整:自定义调整学习率 LambdaLR。
torch.nn模块
卷积层
conv2d
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,
dilation=1, groups=1, bias=True, padding_mode='zeros')
输出维度计算:

convTranspose2d
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1,
padding=0, output_padding=0, groups=1, bias=True,
dilation=1, padding_mode=‘zeros’)
size_output = (size_input - 1)*stride + k - 2*padding + outpadding
Norm归一化层
四种Norm:BN,LN,IN,GN
https://blog.csdn.net/shanglianlm/article/details/85075706
在Generator中我们使用InstanceNorm,在channel内做归一化,适用于图片的风格迁移。
pytorch batch_norm
https://pytorch.org/docs/stable/nn.functional.html?highlight=batch_norm#torch.nn.functional.batch_norm
Padding
-
可以在卷积之前进行padding操作。
-
有四种基本的padding类型:https://zhuanlan.zhihu.com/p/95368411
- 零填充ZeroPad2d
- 常数填充ConstantPad2d
- 镜像填充ReflectionPad2d
- 重复填充ReplicationPad2d
pad = nn.ZeroPad2d(padding=(1, 2, 3, 4))
y = pad(x)
padding的参数指定左、右、上、下四个方向padding的数目。
Pooling
AdaptiveAvgPool
自适应池化。
torch.nn.AdaptiveAvgPool1d(output_size)
*#output_size:输出尺寸*
通道数前后不发生变化。
激活函数
https://blog.csdn.net/qq_23304241/article/details/80300149
init模块
参数初始化
He et. al Initialization
在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0。推荐在ReLU网络中使用。
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
自定义参数初始化
使用apply(weight_init)函数,weight_init可以是自定义参数初始化函数。
dropout
防止过拟合的方法。
https://blog.csdn.net/junbaba_/article/details/105673998
upsample
实现上采样。参考
ModuleList和Sequential
- nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数。
- nn.Sequential可以使用OrderedDict对每层进行命名。
- nn.Sequential里面的模块按照顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言。
- nn.ModuleList可以使用for循环直接创建
class net4(nn.Module):
def __init__(self):
super(net4, self).__init__()
layers = [nn.Linear(10, 10) for i in range(5)]
self.linears = nn.ModuleList(layers)
def forward(self, x):
for layer in self.linears:
x = layer(x)
return x
Parameter
torch.nn.Parameter():构建一个可以学习的参数。
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))
https://www.jianshu.com/p/d8b77cc02410
network
Resnet
代码实现https://blog.csdn.net/litt1e/article/details/89316705?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-0&spm=1001.2101.3001.4242接近官方版本。
https://blog.csdn.net/winycg/article/details/86709991写法相似,把downsample写在了block中判断,有点小问题。
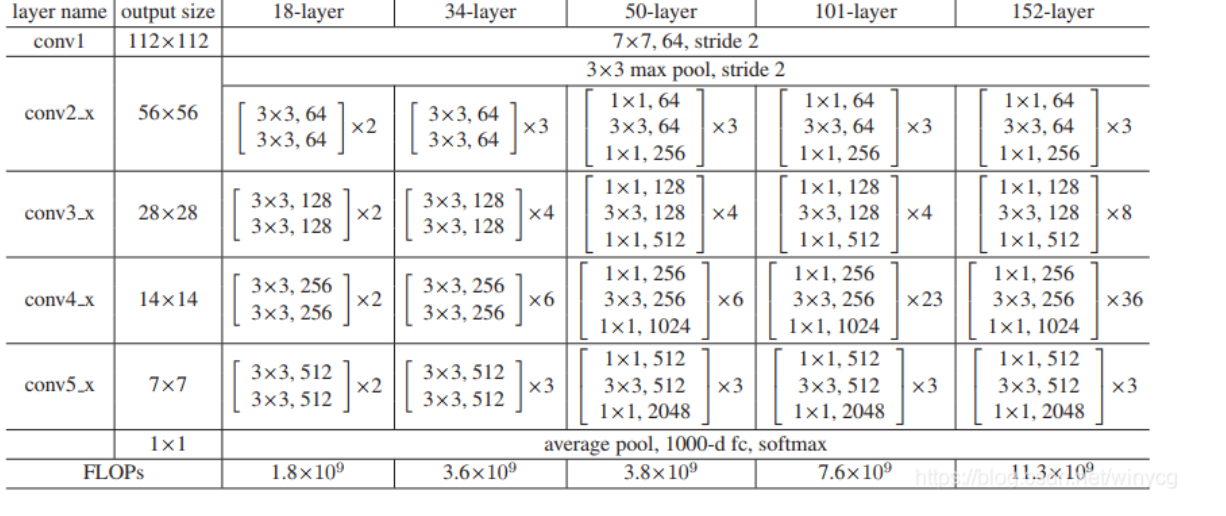
- 第一层size:conv1:torch.Size([64,3,7,7])
ASPP
即带有空洞卷积的空间金字塔结构
https://blog.csdn.net/qq_41174201/article/details/88787770
就是对于同一幅顶端feature map,使用不同dilation rate的空洞卷积去处理它,将得到的各个结果concat到一起,扩大通道数,最后再通过一个[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S06T3Wbs-1617177529724)(typora_imgs/gif.latex)]的卷积层,将通道数降到我们想要的数值。















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









