



 本文深入探讨Pandas的DataFrame数据结构,讲解其组成部分、读取数据的方法、属性以及索引和列的使用。通过实例展示了如何从DataFrame中选择Series,以及如何利用索引对齐和操作数据。此外,还介绍了DataFrame与NumPy数组的关系以及如何访问和操作DataFrame的不同组件。
本文深入探讨Pandas的DataFrame数据结构,讲解其组成部分、读取数据的方法、属性以及索引和列的使用。通过实例展示了如何从DataFrame中选择Series,以及如何利用索引对齐和操作数据。此外,还介绍了DataFrame与NumPy数组的关系以及如何访问和操作DataFrame的不同组件。
1. 导入Pandas
大多数 Pandas 库的使用者会使用别名来完成导入,因此他们可以将其称为pd。在本书中,我们不会显示 Pandas 和 NumPy 的导入,但是它们看起来像这样:>>> import pandas as pd>>> import numpy as np2. 介绍
本文的目标是通透了解 Series 和 DataFrame 数据结构来介绍 pandas 的基础。
对于 Pandas 用户来说,了解 Series 和 DataFrame 之间的区别非常重要。
Pandas 库对于处理结构化数据很有用。什么是结构化数据?存储在表格中的数据,如CSV文件、Excel电子表格或数据库表格,都是结构化数据。
非结构化数据由自由形式的文本、图像、声音或视频组成。
如果你发现自己在处理结构化数据,那么 pandas 将对你有很大的帮助。
在本文中,你将学习如何从 DataFrame(二维数据集)中选择一列数据,并将其作为 Series(一维数据集)返回。
使用这种一维对象可以很容易地展示不同的方法和操作符是如何工作的。
许多 Series 方法会返回另一个 Series 作为输出。这导致了连续调用更多方法的可能性,这就是所谓的方法链。
Series 和 DataFrame 的索引组件是 pandas 与大多数其他数据分析库的区别,也是理解许多操作工作的关键。
当我们使用它作为 Series 值的一个有意义的标签时,我们将一睹这个强大的对象的风采。
最后两个方法包含了数据分析过程中经常出现的任务。
3. Pandas DataFrame
在深入了解 pandas 之前,不妨先了解一下 DataFrame 的组成部分。
从视觉上看,Pandas DataFrame(在Jupyter Notebook中)的输出显示似乎只是一个普通的由行和列组成的数据表。
隐藏在表面之下的是三个组成部分--索引、列和数据,你必须意识到这一点,才能最大限度地发挥 DataFrame 的全部潜力。
这个方法将电影数据集读入 pandas DataFrame 中,并提供了它所有主要组件的标签图。
>>> movies = pd.read_csv("data/movie.csv")>>> movies color direc/_name ... aspec/ratio movie/likes0 Color James Cameron ... 1.78 330001 Color Gore Verbinski ... 2.35 02 Color Sam Mendes ... 2.35 850003 Color Christopher Nolan ... 2.35 1640004 NaN Doug Walker ... NaN 0... ... ... ... ... ...4911 Color Scott Smith ... NaN 844912 Color NaN ... 16.00 320004913 Color Benjamin Roberds ... NaN 164914 Color Daniel Hsia ... 2.35 6604915 Color Jon Gunn ... 1.85 456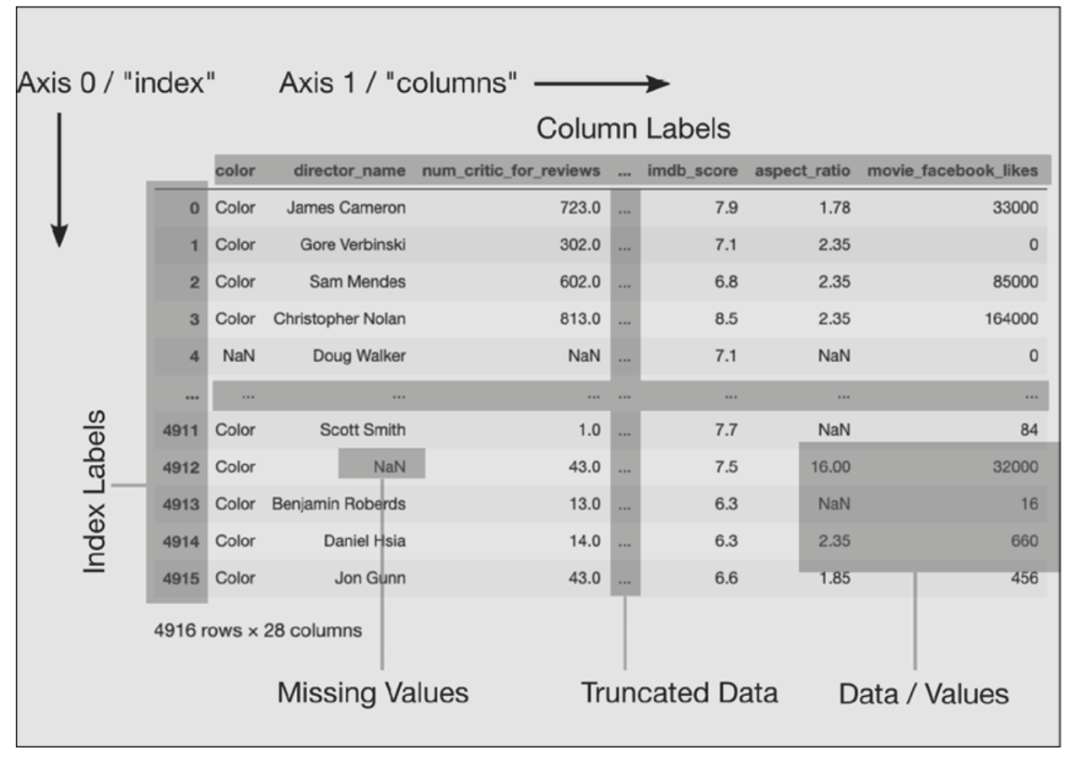
# 如何工作
Pandas 首先使用 read_csv 函数将数据从磁盘读入内存,并读入DataFrame。
按照惯例,术语 index标签和Column列名分别指的是索引和列的各个成员。
术语索引指的是所有索引标签的整体,正如术语列指的是所有列名的整体。
通过索引和列名中的标签,可以根据索引和列名调出数据。我们将在后面展示。
索引也用于对齐。当多个 Series 或 DataFrames 组合在一起时,在任何计算发生之前,索引会先对齐。后面的操作示例也会显示这一点。
列和索引统称为轴。更具体地说,索引是0轴,列是1轴。
Pandas 使用 NaN(不是数字)来表示缺失的值。请注意,即使颜色列有字符串值,它也使用 NaN 来表示缺失的值。
列中间的三个连续的点,...,表示至少有一列存在,但由于列数超过了预定义的显示限制而没有显示。
默认情况下,pandas 显示60行20列,但我们在书中对其进行了限制,所以数据适合在一页中显示。
.head方法接受一个可选的参数 n,它控制显示的行数。同样,.tail 方法也会返回最后n行的数据。
4. DataFrame 的属性
三个 DataFrame 组件中的每一个组件--索引、列和数据--都可以从 DataFrame 中访问。
你可能希望对各个组件进行操作,而不是对整个 DataFrame 进行操作。
一般来说,虽然我们可以将数据拉出到 NumPy 数组中,但除非所有的列都是数字,否则我们通常会将其留在 DataFrame 中。
DataFrames 是管理异构数据列的理想选择,NumPy 数组则不然。
这个方法将DataFrame的索引、列和数据拉出到自己的变量中,然后展示如何从同一个对象中继承列和索引。
# 怎么做
1. 使用DataFrame 属性 index、列和值将索引、列和数据分配给自己的变量:
>>> movies = pd.read_csv("data/movie.csv")>>> columns = movies.columns>>> index = movies.index>>> data = movies.to_numpy()2. 显示每个组件的值:
>>> columnsIndex(['color', 'director_name', 'num_critic_for_reviews', 'duration', 'director_facebook_likes', 'actor_3_facebook_likes', 'actor_2_name', 'actor_1_facebook_likes', 'gross', 'genres', 'actor_1_name', 'movie_title', 'num_voted_users', 'cast_total_facebook_likes', 'actor_3_name', 'facenumber_in_poster', 'plot_keywords', 'movie_imdb_link', 'num_user_for_reviews', 'language', 'country', 'content_rating', 'budget', 'title_year', 'actor_2_facebook_likes', 'imdb_score', 'aspect_ratio', 'movie_facebook_likes'], dtype='object')>>> index RangeIndex(start=0, stop=4916, step=1)>>> dataarray([['Color', 'James Cameron', 723.0, ..., 7.9, 1.78, 33000], ['Color', 'Gore Verbinski', 302.0, ..., 7.1, 2.35, 0], ['Color', 'Sam Mendes', 602.0, ..., 6.8, 2.35, 85000], ..., ['Color', 'Benjamin Roberds', 13.0, ..., 6.3, nan, 16], ['Color', 'Daniel Hsia', 14.0, ..., 6.3, 2.35, 660], ['Color', 'Jon Gunn', 43.0, ..., 6.6, 1.85, 456]], dtype=object)3. 输出每个DataFrame组件的Python类型 (输出的最后一个点后面的单词):
>>> type(index)>>> type(columns)>>> type(data)4. 索引和列是密切相关的。它们都是 Index 的子类。这使得你可以对索引和列进行类似的操作:
>>> issubclass(pd.RangeIndex, pd.Index)True>>> issubclass(columns.__class__, pd.Index)True# 如何工作
指数和列数代表的是同一事物,但沿着不同的轴线。它们偶尔也被称为行索引和列索引。
Pandas 中的索引对象有很多类型。如果你没有指定索引,pandas 将使用RangeIndex。
RangeIndex 是 Index 的一个子类,类似于 Python 的 range 对象。
它的整个值序列在必要时才会被加载到内存中,从而节省内存。它完全由它的开始、停止和步长值定义。
# 还有更多
在可能的情况下,索引对象是用哈希表实现的,它允许快速选择和数据对齐。
它们类似于 Python 集合,因为它们支持交集和联合等操作,但不同的是它们是有序的,可以有重复的条目。
注意 .values DataFrame属性如何返回一个Numpy n维数组,或 ndarray。pandas的大部分内容都严重依赖于ndarray。
索引、列和数据下面是NumPy ndarray。它们可以被认为是pandas的基础对象,许多其他对象都是建立在它的基础上的。
要看到这一点,我们可以看看索引和列的值:
>>> index.to_numpy()array([ 0, 1, 2, ..., 4913, 4914, 4915], dtype=int64))>>> columns.to_numpy()array(['color', 'director_name', 'num_critic_for_reviews', 'duration', 'director_facebook_likes', 'actor_3_facebook_likes', 'actor_2_name', 'actor_1_facebook_likes', 'gross', 'genres', 'actor_1_name', 'movie_title', 'num_voted_users', 'cast_total_facebook_likes', 'actor_3_name', 'facenumber_in_poster', 'plot_keywords', 'movie_imdb_link', 'num_user_for_reviews', 'language', 'country', 'content_rating', 'budget', 'title_year', 'actor_2_facebook_likes', 'imdb_score', 'aspect_ratio', 'movie_facebook_likes'], dtype=object)说了这么多,我们通常不会访问底层的 NumPy 对象。
我们倾向于将对象作为pandas 对象,并使用 pandas 操作。
然而,需要记住我们经常将 NumPy 函数应用到pandas 对象上。
关注我,继续深度检查自己Pandas基础,透彻了解Pandas。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









