这是Python数据分析实战基础的第一篇内容,主要是和Pandas来个简单的邂逅。已经熟练掌握Pandas的同学,可以加快手速滑动浏览或者直接略过本文。
01 重要的前言
这段时间和一些做数据分析的同学闲聊,我发现数据分析技能入门阶段存在一个普遍性的问题,很多凭着兴趣入坑的同学,都能够很快熟悉Python基础语法,然后不约而同的一头扎进《利用Python进行数据分析》这本经典之中,硬着头皮啃完之后,好像自己什么都会了一点,然而实际操作起来既不知从何操起,又漏洞百出。
至于原因嘛,
理解不够,实践不够是两条老牌的拦路虎,只能靠自己来克服。还有一个非常有意思且经常被忽视的因素——
陷入举三反一的懵逼状态。
什么意思呢?假如我是个旱鸭子,想去学游泳,教练很认真的给我剖析了蛙泳的动作,扶着我的腰让我在水里划拉了5分钟,接着马上给我讲解了蝶泳,又是划拉了5分钟,然后又硬塞给我潜泳的姿势,依然是划拉5分钟。最后,教练一下子把我丢进踩不到底的泳池,给我呐喊助威。
作为一个还没入门的旱鸭子,教练倾囊授了我3种游泳技巧,让我分别实践了5分钟。这样做的结果就是我哪一种游泳技巧也没学会,只学会了喝水。
当一个初学者一开始就陷入针对单个问题的多种解决方法,而每一种方法的实践又浅尝辄止,在面对具体问题时往往会手忙脚乱。
拿Pandas来说,它的多种构造方式,多种索引方式以及类似效果的多种实现方法,很容易把初学者打入举三反一的懵逼状态。所以,尽量避开这个坑
也
是我
写
Pandas
基础系列的初衷,
希望通过
梳理
和精简知识点
的方式,
给需要的同学一些启发。目前暂定整个基础系列分为4篇,基础篇过后便是有趣的实战篇。
下面开始进入正题(我真是太唠叨了)。
02 Pandas简介
江湖上流传着这么一句话——分析不识潘大师(PANDAS),纵是老手也枉然。
Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器。它提供了两种类型的数据结构,分别是DataFrame和Series,
我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列,后面学习和用到的所有Pandas骚操作,都是基于这些表和列进行的操作(关于Pandas和Excel的形象关系,这里推荐我的好朋友张俊红写的《对比EXCEL,轻松学习Python数据分析》)。
这里有一点需要强调,Pandas和Excel、SQL相比,只是调用和处理数据的方式变了,
核心都是对源数据进行一系列的处理,在正式处理之前,更重要的是
谋定而后动,明确分析的意义,理清分析思路之后再处理和分析数据
,往往事半功倍。
03 创建、读取和存储
1、创建
在Pandas中我们想要构造下面这一张表应该如何操作呢?

别忘了,第一步一定是先导入我们的库——import pandas as pd
构造DataFrame最常用的方式是字典+列表,语句很简单,先是字典外括,然后依次打出每一列标题及其对应的列值(此处一定要用列表),这里列的顺序并不重要:

左边是jupyter notebook中dataframe的样子,如果对应到excel中,他就是右边表格的样子,通过改变columns,index和values的值来控制数据。
PS,如果我们在创建时不指定index,系统会自动生成从0开始的索引。
2、 读取
更多时候,我们是把相关文件数据直接读进PANDAS中进行操作,这里介绍两种非常接近的读取方式,一种是CSV格式的文件,一种是EXCEL格式(.xlsx和xls后缀)的文件。
读取csv文件:
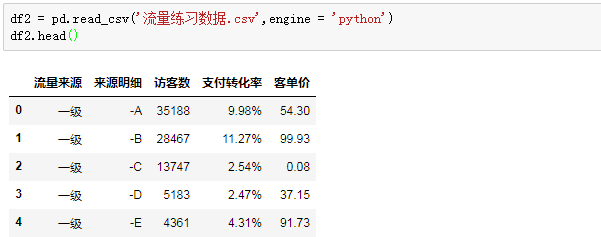
engine是使用的分析引擎,读取csv文件一般指定python避免中文和编码造成的报错。
而读
取Excel文件,则是一样的味道:
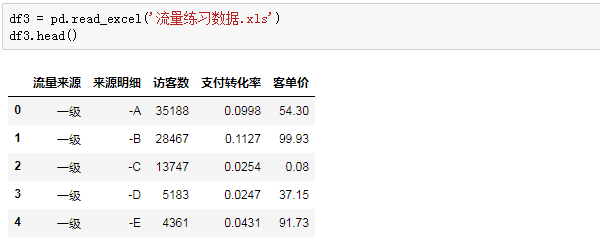
非常easy,其实read_csv和read_excel还有一些参数,比如header、sep、names等,大家可以做额外了解。实践中数据源的格式一般都是比较规整的,更多情况是直接读取。
3、存储
存储起来一样非常简单粗暴且相似:
 04 快速认识数据
04 快速认识数据
这里以我们的案例数据为例,迅速熟悉查看N行,数据格式概览以及基础统计数据。
1、查看数据,掐头看尾
很多时候我们想要对数据内容做一个总览,用df.head()函数直接可以查看默认的前5行,与之对应,df.tail()就可以查看数据尾部的5行数据,这两个参数内可以传入一个数值来控制查看的行数,例如df.head(10)表示查看前10行数据。
 2、 格式查看
2、 格式查看
df.info()帮助我们一步摸清各列数据的类型,以及缺失情况:

从上面直接可以知道数据集的行列数,数据集的大小,每一列的数据类型,以及有多少条非空数据。
3、统计信息概览
快速计算数值型数据的关键统计指标,像平均数、中位数、标准差等等。
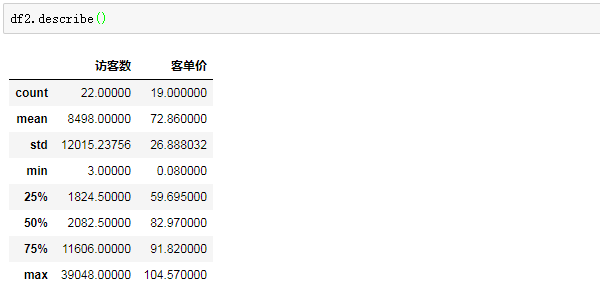
我们本来有5列数据,为什么返回结果只有两列?
那是因为这个操作只针对数值型的列。
其中count是统计每一列的有多少个非空数值,mean、std、min、max对应的分别是该列的均值、标准差、平均值和最大值,25%、50%、75%对应的则是分位数。
05 列的基本处理方式
这里,我们采用SQL四大法宝的逻辑来简单梳理针对列的基本处理方式——
增、删、选、改。
温馨提示:
使用Pandas时,尽量避免用行或者EXCEL操作单元格的思维来处理数据,要逐渐养成一种列向思维,每一列是同宗同源,处理起来是嗖嗖的快。
1、增
增加一列,用df['新列名'] = 新列值的形式,在原数据基础上赋值即可:
 2、删:
2、删:
我们用drop函数制定删除对应的列,axis = 1表示针对列的操作,inplace为True,则直接在源数据上进行修改,否则源数据会保持原样。
 3、选:
3、选:
想要选取某一列怎么办?
df['列名']即可:

选取多列呢?
需要用列表来传递:
df[['第一列','第二列','第三列'..]]
 4、 改:
4、 改:
好事多磨,复杂的针对特定条件和行列的筛选、修改,放在后面结合案例细讲,这里只讲一下最简单的更改:
df['旧列名'] = 某个值或者某列值,就完成了对原列数值的修改。
06 常用数据类型及操作
1、字符串
字符串类型是最常用的格式之一了,Pandas中字符串的操作和原生字符串操作几乎一毛一样,唯一不同的是需要在操作前加上".str"。
小Z温馨提示:
我们最初用df2.info()查看数据类型时,非数值型的列都返回的是object格式,和str类型深层机制上的区别就不展开了,在常规实际应用中,我们可以先理解为object对应的就是str格式,int64对应的就是int格式,float64对应的就是float格式即可。
在案例数据中,我们发现来源明细那一列,可能是系统导出的历史遗留问题,每一个字符串前面都有一个“-”符号,又丑又无用,所以把他给拿掉:
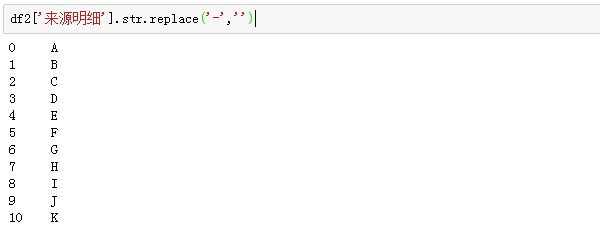
一般来说清洗之后的列是要替换掉原来列的:
 2、 数值型
2、 数值型
数值型数据,常见的操作是计算,分为与单个值的运算,长度相等列的运算。
以案例数据为例,源数据访客数我们是知道的,现在想把所有渠道的访客都加上10000,怎么操作呢?

只需要选中访客数所在列,然后加上10000即可,pandas自动将10000和每一行数值相加,针对单个值的其他运算(减乘除)也是如此。
列之间的运算语句也非常简洁。
源数据是包含了访客数、转化率和客单价,而实际工作中我们对每个渠道贡献的销售额更感兴趣。
(销售额 = 访客数 X 转化率 X 客单价)
对应操作语句:
df['销售额'] = df['访客数'] * df['转化率'] * df['客单价']
但为什么疯狂报错?
导致报错的原因,是数值型数据和非数值型数据相互计算导致的。
PANDAS把带“%”符号的转化率识别成字符串类型,我们需要先拿掉百分号,再将这一列转化为浮点型数据:
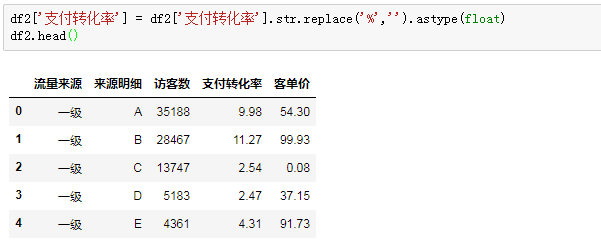
要注意的是,这样操作,把9.98%变成了9.98,所以我们还需要让支付转化率除以100,来还原百分数的真实数值:
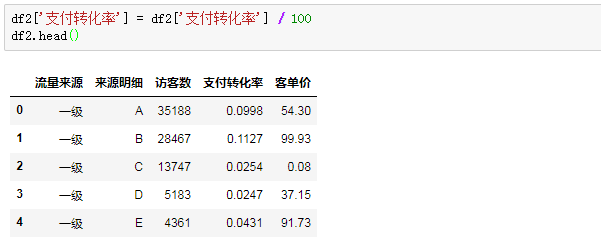
然后,再用三个指标相乘计算销售额:
 3、时间类型
3、时间类型
PANDAS中时间序列相关的水非常深,这里只对日常中最基础的时间格式进行讲解,对时间序列感兴趣的同学可以自行查阅相关资料,深入了解。
以案例数据为例,我们这些渠道数据,是在2019年8月2日提取的,后面可能涉及到其他日期的渠道数据,所以需要加一列时间予以区分,在EXCEL中常用的时间格式是'2019-8-3'或者'2019/8/3',
我们用PANDAS来实现一下:
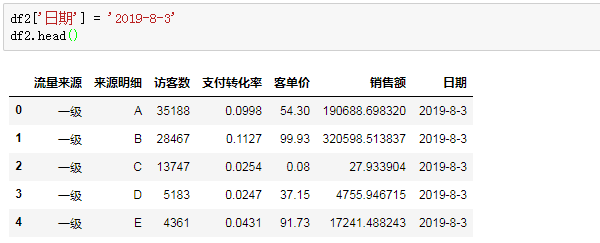
在实际业务中,一些时候PANDAS会把文件中日期格式的字段读取为字符串格式,这里我们先把字符串'2019-8-3'赋值给新增的日期列,然后用to_datetime()函数将字符串类型转换成时间格式:

转换成时间格式(这里是datetime64)之后,我们可以用处理时间的思路高效处理这些数据,比如,我现在想知道提取数据这一天离年末还有多少天('2019-12-31'),
直接做减法(
该函数接受时间格式的字符串序列,也接受单个字符串):

是不是非常简单?
最后我们一起快速回顾下第一篇文章的内容:
- 第一步,我们先了解PANDAS到底是个什么东西。
- 第二步,学习如何构建、读入存储数据。
- 第三步,拿到数据之后,怎么样快速查看数据。
- 第四步,对数据有了基础了解,就可以进行简单的增删选改了。
- 第五步,在了解基础操作之后,对Pandas中基础数据类型进行了初步照面。
每一步都是本着小而美(毕竟臭美也算美)和轻量的初心,和大家一起重新认识回顾这些模块,然后在接下来的案例实践中检验、巩固、沉淀这些操作与分析思路。























 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









