






PCA算法的必要性
多变量大数据集无疑会为研究和应用提供丰富的信息,但是许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此如果可以在减少需要分析的指标同时,尽量减少原指标包含信息的损失,那么将有利于算法模型的搭建。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。PCA算法就属于这类降维算法。
我们所使用的数据集
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。数据集的部分数据如下所示:

可以看出这个数据集中的数据分为5列,也就是5个特征,5个维度,这5个列分别是:鸢尾花的花萼长度、花萼宽度、花瓣长度、 花瓣宽度、以及花的类别。这样的5个维度很难通过可视化的方式,所以下面我们将通过PCA算法来完成降维的操作,将5维数据将成2维。
数据的读取
下面我们先读取文件中的数据,并且为每列数据指定其列名,这样更加的有利于查看我们读取到数据。
import numpy as npimport pandas as pddf=pd.read_csv('iris.data')df.columns=['sepal_len','sepal_wid','petal_len','petal_wid','class']print(df.hean())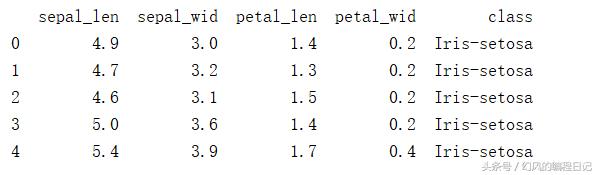
部分数据
可视化
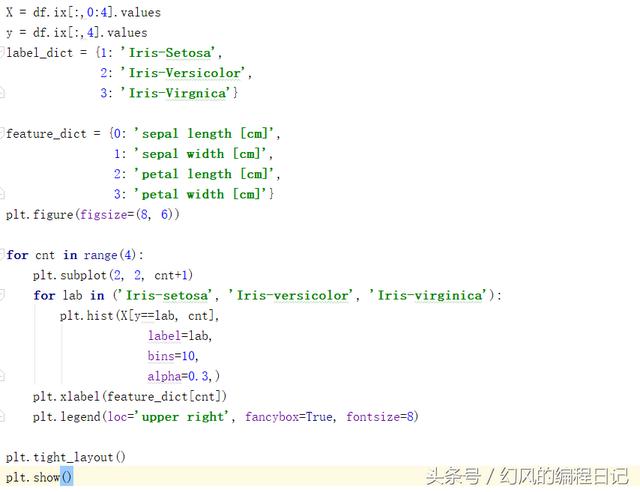
可视化代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









