
在说stream之前,给大家分享一个数组匹配性能优化技巧,其实平时注意一些编码的优化,对整个系统的性能优化是有很大帮助的,积少成多。往往一个项目都是毁在一行行粗心代码上的,比如这里多占点内存,那里多占点内存,慢慢内存就不够用了,结果就想着升级机器配置。下面给出的代码例子就是判断一个整数是否在数组中,实际项目中数组是无序的。

如果
用List的
c
ont
ains方法,其实就是
数组遍历。从输出结果看,
使用
字符串匹配的方式会比使用
c
ont
ains快出6ms,数组大小还仅仅是10w不到。不要少看这几毫秒的差距,一个线程中调用几十万次这个方法,你就知道所提升的性能了。
但是我没有计算将一个数组转为字符串的时间,如果加上,那就没有可比性了,之所以我会忽略这个转化的时间,因为这步我用定时任务更新数据的时候就做了。
Stream并行流的使用注意事项Java8提供的流式编程Stream,相信大家每天都在用。但是读过源码的,我猜也没有几个,包括我。只是最近使用上遇到些问题,不得不去深入了解,所以我花了点时间粗略看了一下,但关于并行流的逻辑我也没理解清楚。为什么说不了解点框架源码就用不好一个框架,今天的例子就能很好说明白这个道理。Stream利用的管道思想其实在很多框架中也能看到,比如Netty、RxJava。
我在17年的时候有去看过RxJava的源码,那时是用来做安卓开发解决线程切换问题的,因为页面的渲染只能在主线程,但是那时候读源码很是头大,后面放弃了。做后端之后就没再用过RxJava。看了网上有挺多分析stream源码的文章的,所以我也不打算跟大家分析stream的源码,至于并行流parallelStream,网上没能找到能说清楚的文章,但是我自己也没理解清楚,所以还是得靠自己啊。今天主要说的是使用parallelStream的一些注意细节,看了之后不要再踩这些坑了哦。

Parallel Stream实现任务的切分,并将任务提交到全局的ForkJoinPool线程池中执行,注意,是全局的线程池。关于ForkJoinPool,我这里简单介绍下。
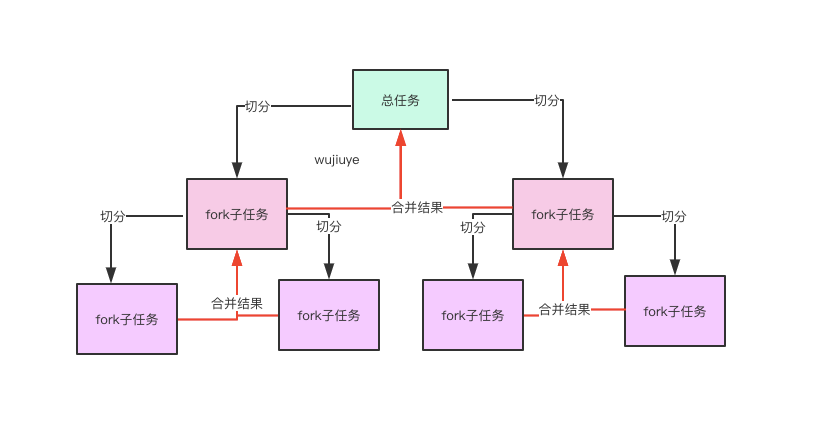
本来想偷懒,直接去网上找张图的。网上画的图很好看,但我觉得并没有画出Fork-Join这两个词的真正含义。只可意会不可言传哪。我的理解范围内,Fork-Join的最大特点是分治思想,与Hadoop的MapReduce(这个单词写对了吗)一个原理,其实如果用过归并排序算法的,也能看出,这跟归并排序算法很像。
关于工作窃取机制,这应该是go语言协程里的概念。在Fork-Join中,比如一个拥有4个线程的ForkJoinPool线程池,有一个任务队列,一个大的任务切分出的子任务会提交到线程池的任务队列中,4个线程从任务队列中获取任务执行,哪个线程执行的任务快,哪个线程执行的任务就多,只有队列中没有任务线程才是空闲的,这就是工作窃取。可以这样理解工作窃取,比如有4个人干8件事情,理应每个人干2件,但干活快的干完自己的事情后可以去帮别人干。正如图中所示,一个任务可以fork中很多个子任务,当然不只是图中看到的只有左右两个。假设,每个任务都只fork出两个子任务,如果负责fork子任务的当前任务不做任何事情,那么最终将只有叶子节点真正做事情,其它节点都只是负责fork子任务与合并结果(假设是有返回值的任务)。如果是没有返回值的任务,是没有图中“合并结果”这个流程的;而且,也不是必须要等待子任务执行完成。这些都是根据自己的需求来自定义使用的。要灵活去使用。比如,处理一个1+2+3+....+100的加法运算任务,就需要获取返回值,而切分任务我们可以这样切分:每次除2切分左右两个子任务,如100/2=50,1到50的相加由左子任务完成,51到100的由右子任务完成,1到50同理继续除2切分出子任务,切到只剩一个数的时候就返回。没错,我说的就是归并算法。核心逻辑代码实现如下。
// 分治MyForkTask leftTask = new MyForkTask(numbers);leftTask.fork();MyForkTask rightTask = new MyForkTask(numbers);rightTask.fork(); // 等待子任务完成,合并结果count += leftNextPullTask.join();count += rightNextPullTask.join();// (微信公众号:Java艺术)
对了,既然是线程池,那肯定是要提交任务。前面说了Fork-Join支持切分的任务分有返回值和没有返回值两种,任务是分别对应实现RecursiveTask接口与RecursiveAction接口。关于Fork-Join就说这么多吧。

重点说下Parallel Stream并行流使用的一些坑。一个是使用.parallelStream()之后,在接下来的管道中做任何业务逻辑都需要确保线程安全,比如。
List<Int..> result = new ArrayList<>();tmpList.parallerStream() .foEach(item -> { .....(微信公众号:Java艺术) result.add(item); });
由于
ArrayList并不是线程安全的,这样使用就会出现线程安全问题,所以注意了,使用
parallerS
tream必须确保线程安全问题。可能很多人都像我一样,自从用了stearm之后就很少写for循环了,这不是一个好的习惯。比如我只是简单的遍历一遍int数组,那就不要使用stearm,直接使用for循环性能会更好,因为stream你只是用着简单,但你看下源码,封装很多复杂逻辑,原本只是简单的数组遍历,你用stream之后将会创建出很多中间对象,还有一大堆的流式调用逻辑。

你以为这样就完了吗?还有更恐怖的线程安全问题。在并发量高的接口中不要直接使用stream的
parallerS
tream处理耗时的逻辑,因为并行流运行时,内部使用的fork-join线程池是整个JVM进程全局唯一的线程池。而这个线程池其默认线程数为处理器核心数。
// (微信公众号:Java艺术)Runtime.getRuntime().availableProcessors()
可以通过配置修改这个值 。
// (微信公众号:Java艺术)System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
一般不建议修改,最好是自己创建一个Fork-Join线程池来用,因为你如果改了,虽然对你当前的业务逻辑来说,算是调优了,但对于项目中其它地方只是用来做非耗时的并行流运算,性能就差了。对的,由于所有使用并行流
parallerS
tream的地方都是使用同一个Fork-Join线程池,而线程池线程数仅为cpu的核心数。我们可以来写个例子验证是不是整个java进程使用的
parallerS
tream都是用的同一个进程,我这里提供例子,不相信的可以自己拿去跑下看看。
/** * @author wujiuye * @version 1.0 on 2019/9/25 {描述:} */public class PStream { // (微信公众号:Java艺术) public static void main(String[] args) throws InterruptedException { final List list = new ArrayList<>(100); for (int i = 0; i < 100; i++) { list.add(1); } for (int i = 1; i <= 50; i++) { new Thread("test-" + i) { String currentThreaName = this.getName(); @Override public void run() { list.parallelStream() .forEach(numbser -> { Thread c = Thread.currentThread(); System.out.println(currentThreaName + "===> " + c.getClass().getName() + ":" + c.getName() + ":" + c.getId()); try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } }); } }.start(); } Thread.sleep(Integer.MAX_VALUE); }}
程序运行结果部分截图

你可能会被线程id62、63、64吓到,因为for循环创建了50个线程,jvm启动后自身也会创建一些线程,比如gc线程。所以全局Fork-Join线程池的线程id是从62开始的几个。你还可以去调试看源码。
对应forEach流 ForEachOps::compute方法打个断点, 或者直接forEach方法的输出语句打个断点,找到ForkJoinWorkerThread类 public class ForkJoinWorkerThread extends Thread { final ForkJoinPool pool; // the pool this thread works in final ForkJoinPool.WorkQueue workQueue; // work-stea public void run() { .... (微信公众号:Java艺术) pool.runWorker(workQueue); ...... } }

假设,分布式服务中(rpx框架:dubbo),有一个接口,用于批量处理数据,如果每次消费者调用都用了批量处理1000条记录的过滤,假设一条记录的过滤逻辑需要耗时4ms( 涉及到redis缓存的读),如果有40个请求并发过滤,那就是40000条记录交给2个线程去处理(cpu核心线程数),你猜下结果是什么?结果是,服务消费端报错,一堆的接口调用超时异常,导致服务雪崩。后果很严重。原因你猜到了吗?40个请求开启40个并行流
parallerS
tream,40个并行流
parallerS
tream使用同一个只有2个线程的Fork-Join线程池(2核8g机器),意味着40个请求争抢着执行任务。假设一条记录的过滤耗时为4ms,在串行的情况下1000条记录应该只是4000ms。但如果是400000条记录争抢2个线程执行,我们转变一下,假设每线程每200000记录执行,由于是无序的,但可以想象对请求来说任务是被交替执行完成的。什么意思呢,比如当前执行1号请求的第一个任务,执行完后切换到2号个请求的第一个任务,接着3号请求的第一个任务,一轮完成后接着是1号请求的第二个任务...所以,最坏的情况下,一个请求需要200000*4ms才能执行完成。就会导致接口调用超时。总之,不要在高并发的接口中使用并行流,直接使用处理请求的线程执行就行,如果有需要,那就全局创建一个Fork-Join线程池自己切分任务来执行。刚刚说的例子只是40个并发,实现项目中都是上千上万的并发请求,如果这样使用并行流,服务直接崩掉。假设用的dubbo默认配置200个工作线程,那么是200个线程处理业务逻辑快呢,还是将200个线程的请求都交给只有2个线程的线程池处理快呢?毫无疑问。
总结那些耗时很长的任务,请不要使用
parallerS
tream。假设原本一个任务执行需要1分钟时间,有10个任务并行执行,如果你偷懒,只是使用
parallerS
tream来将这10个任务并行执行,那你这个jvm进程中,其它同样使用
parallerS
tream的地方也会因此被阻塞住,严重的将会导致整个服务瘫痪。关于stream的并行流
parallerS
tream使用注意事项就说到这。切记,请不要乱用并行流,在使用之前一定、一定、一定要考虑清楚任务是否耗时,有i/o操作的一定不要使用并行流,有线程休眠的也一定不要使用并行流,原本就只有两个线程,还搞休眠,等着整个服务崩溃咯。快去扫描一遍你项目中的代码吧,如果是自己写的,就默默删掉吧,哈哈!




点个在看吧,证明你还爱我





















 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









