





一、物理建模合成
在我们手指拨动吉他琴弦的瞬间,我们就对琴弦产生了一个类似于冲激函数的输入。它给琴弦带来了让它振动的能量,以及宽阔的频谱。
接下来,大部分的频率成分都在使琴弦产生受迫振动的过程中迅速消散,而符合琴弦共振频率的成分,消散的速度则要慢许多。迅速消散的那些成分,形成了音头,而剩下的谐波列就给了这个声音一个确切的音高,它们一起又形成了拨弦这样的一个音色。
实际上,拨动琴弦之后产生的事情可能还要复杂许多。比如共鸣箱的形状,会放大某些特定的频率、抑制某些特定的频率,让不同的琴有不同的特色。比如拨片拨弦和手指拨弦这样不同的拨弦方式,又给了琴弦的振动不太一样的初始条件从而产生不同的音色。
我们很难将所有影响其振动的因素一一列举出来。而建模就是对现实世界里,复杂的物理过程进行抽象和简化的过程。抽象和简化之后,我们便得到了一个模型,一个可以借助计算机等有限的运算能力来模拟现实世界中的过程的模型。上面描述拨动琴弦后所发生的事情的过程,其实就是建模的过程。
而在音乐领域,我们就把通过对现实世界的振动的模拟,叫做物理建模合成(Physical Modelling Synthesis)。
这种模拟,可以很复杂,也可以很简单。有时候,它可以是在了解某个过程后,精心设计出来的算法。而有时候,它也可以是在无意之中发现的方法,而后再反过来寻找一些理论去解释它。
二、Karplus-Strong算法
Kevin Karplus 和 Alex Strong 在1980年代一起,就提出了这么一个模拟拨弦乐器的算法。它十分简单,但是它计算出来的声音又十分真实。[1][2]
它的核心只有两步:1. 生成一组随机数2. 不断对它们前后求平均
我们首先生成一组一定长度的随机数。随机数拥有着十分宽阔的频谱范围,这组随机数就代表了拨弦的那一瞬间给琴弦带来的能量输入。
但是,噪声本身是没有音高的。为了让我们生成的声音具有一定的音高,我们就需要重复得播放我们所生成的噪声片段。当一段固定的波形以一定的速度重复播放的时候,它就产生了与它重复的频率对应的音高。
(想象一下播放视频或者音频的时候要是卡住了,不断重复的最后那一瞬间的声音。后面附上的代码也提供了一个函数,可以生成一段不断重复的白噪声片段的声音)
但是如果我们只是简单地不断重复它,我们得到的是一段带有复杂的频谱的刺耳的有音高的声音。这时候,Karplus-Strong算法的第二步,前后求平均就上场了!
在我们循环播放这一组随机数的同时,对当前采样点和它的上一个采样点进行求平均。
其中,t是当前时刻,p是初始数组的长度。
求平均的过程,其实就是一个低通滤波的过程。
如果我们对[-1,1,-1,1,-1,1,-1,1]前后求平均,我们就得到了[0,0,0,0,0,0,0]
如果我们对[-1,0,1,0,-1,0,1,0]前后求平均,就得到了[-0.5,0.5,0.5,-0.5,-0.5,0.5,0.5]
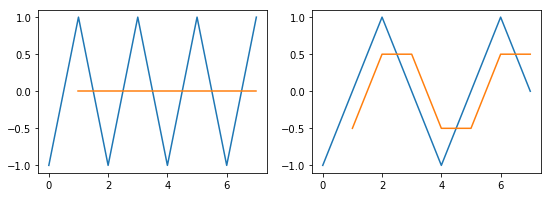
显然,变化越快,也即频率越高的成分,衰减得多。
Karplus-Strong算法的另一个精妙之处在于,它是不断地对当前采样点和上一个采样点求平均,而不是对初始的随机数组求平均之后重复播放。如果我们对初始的数组求平均后播放,我们得到的就是经过一次低通滤波之后的声音。
而对当前值不断求平均,则带来了动态的变化。这组随机数在上一时刻的基础上一次又一次地经过低通滤波器,从而一次又一次地减少其高频成分。同时,这个过程还会不停地改变波形的基本形状,它不仅仅是高频成分不断在衰减,同时它还没衰减的那些成分也在不断地轻微地改变着。
在每次生成声音之前,我们都可以重新生成初始的随机数组,从而让每一次生成的声音都有略微的不同。
这种波形的动态改变,让它生成的声音更加接近于现实世界中的声音。
Karplus-Strong算法仅仅用这么简单的两个步骤,就把拨弦的过程给囊括了进来。这就是抽象和简化精美的地方。
虽然简洁的 Karplus-Strong算法可以生成类似于拨弦的声音,但是世界上的拨弦乐器可不止一种。吉他、琵琶、尤克里里啥啥的。如果需要更精确的模拟,我们就需要更复杂的模型。
而Karplus-Strong本身,除了上面提到的,也还有许多可以改变的地方,比如,使用不同类型的噪声作为初始条件,会得到什么样的不同结果?如果我们不仅仅是把前后两个点做平均,而是更多的点,又会怎么样?
三、后记
物理合成算法跟其他的合成算法比起来,最大的一个区别就是物理建模合成可以让用户更好地理解自己制作音色时的每一个步骤。
像加减法合成、FM合成等,都需要大量的经验来告诉乐手,什么样的谐波组合、什么样的滤波、什么样的调制会产生什么样的听觉效果。它们之间的很多步骤都很不直观。除了John Chowning,又有谁能想到一个迅速衰减的调制信号能让FM调制产生敲钟的音色呢?
而物理建模合成,则可以使用一些我们对音色的感性描述,像“明暗”、“鼻音”、“气声”等,来帮助我们去做出脑子里的音色。
四、Karplus-Strong算法的Python实现
下面的Python类包括了一个基本的Karplus-Strong算法,并且可以通过类中的方法来将生成的类保存为.wav文件,或者直接播放(需要PyAudio库)
类中的核心只有__buffer()方法,其他的代码大部分都是用于实现示波器和播放音频的
# -*- coding: utf-8 -*-
参考
- ^Karplus, K., & Strong, A. (1983). Digital Synthesis of Plucked-String and Drum Timbres. Computer Music Journal, 7(2), 43-55. doi:10.2307/3680062
- ^Music and Computers - Chapter 4: The Synthesis of Sound by Computer http://sites.music.columbia.edu/cmc/MusicAndComputers/chapter4/04_09.php














 2493
2493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









