





在之前的示例(分类影评)中,我们了解到在训练周期达到一定次数后,模型在验证数据上的准确率会达到峰值,然后便开始下降。
也就是说,模型会过拟合训练数据。请务必学习如何处理过拟合。尽管通常可以在训练集上实现很高的准确率,但我们真正想要的是开发出能够很好地泛化到测试数据(或之前未见过的数据)的模型。
与过拟合相对的是欠拟合。当测试数据仍存在改进空间时,便会发生欠拟合。出现这种情况的原因有很多:模型不够强大、过于正则化,或者根本没有训练足够长的时间。这意味着网络未学习训练数据中的相关模式。
如果训练时间过长,模型将开始过拟合,并从训练数据中学习无法泛化到测试数据的模式。我们需要在这两者之间实现平衡。了解如何训练适当的周期次数是一项很实用的技能,接下来我们将介绍这一技能。
为了防止发生过拟合,最好的解决方案是使用更多训练数据。用更多数据进行训练的模型自然能够更好地泛化。如无法采用这种解决方案,则次优解决方案是使用正则化等技术。这些技术会限制模型可以存储的信息的数量和类型。如果网络只能记住少量模式,那么优化过程将迫使它专注于最突出的模式,因为这些模式更有机会更好地泛化。
在此笔记本中,我们将探索两种常见的正则化技术(权重正则化和丢弃),并使用它们改进我们的 IMDB 影评分类笔记本。
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
1.12.0-rc1
下载 IMDB 数据集
我们不会像在上一个笔记本中那样使用嵌入,而是对句子进行多热编码。该模型将很快过拟合训练集。它将用来演示何时发生过拟合,以及如何防止过拟合。
对列表进行多热编码意味着将它们转换为由 0 和 1 组成的向量。例如,将序列 [3, 5] 转换为一个 10000 维的向量(除索引 3 和 5 转换为 1 之外,其余全为 0)。
NUM_WORDS = 10000
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences, dimension):
# Create an all-zero matrix of shape (len(sequences), dimension)
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0 # set specific indices of results[i] to 1s
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789 [==============================] - 0s 0us/step
我们来看看生成的其中一个多热向量。字词索引按频率排序,因此索引 0 附近应该有更多的 1 值,如下图所示:
plt.plot(train_data[0])
[]
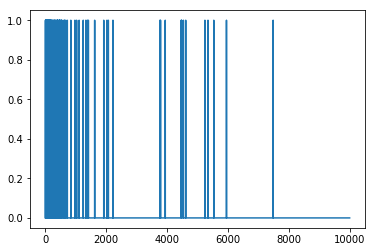
演示过拟合
要防止过拟合,最简单的方法是缩小模型,即减少模型中可学习参数的数量(由层数和每层的单元数决定)。在深度学习中,模型中可学习参数的数量通常称为模型的 “容量”。直观而言,参数越多的模型 “记忆容量” 越大,因此能够轻松学习训练样本与其目标之间的字典式完美映射(无任何泛化能力的映射),但如果要对之前未见过的数据做出预测,这种映射毫无用处。
请务必谨记:深度学习模型往往善于与训练数据拟合,但真正的挑战是泛化,而非拟合。
另一方面,如果网络的记忆资源有限,便无法轻松学习映射。为了最小化损失,它必须学习具有更强预测能力的压缩表示法。同时,如果模型太小,它将难以与训练数据拟合。我们需要在 “太多容量” 和 “容量不足” 这两者之间实现平衡。
遗憾的是,并没有什么神奇公式可用来确定合适的模型大小或架构(由层数或每层的合适大小决定)。您将需要尝试一系列不同的架构。
要找到合适的模型大小,最好先使用相对较少的层和参数,然后开始增加层的大小或添加新的层,直到看到返回的验证损失不断减小为止。我们在影评分类网络上试试这个方法。
我们将仅使用 Dense 层创建一个简单的基准模型,然后创建更小和更大的版本,并比较这些版本。
创建基准模型
baseline_model = keras.Sequential([
# `input_shape` is only required here so that `.summary` works.
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 160016
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
dense_2 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 4s - loss: 0.4765 - acc: 0.8168 - binary_crossentropy: 0.4765 - val_loss: 0.3289 - val_acc: 0.8784 - val_binary_crossentropy: 0.3289
Epoch 2/20
- 3s - loss: 0.2437 - acc: 0.9122 - binary_crossentropy: 0.2437 - val_loss: 0.2828 - val_acc: 0.8878 - val_binary_crossentropy: 0.2828
Epoch 3/20
- 3s - loss: 0.1782 - acc: 0.9376 - binary_crossentropy: 0.1782 - val_loss: 0.2912 - val_acc: 0.8845 - val_binary_crossentropy: 0.2912
Epoch 4/20
- 3s - loss: 0.1416 - acc: 0.9506 - binary_crossentropy: 0.1416 - val_loss: 0.3214 - val_acc: 0.8790 - val_binary_crossentropy: 0.3214
Epoch 5/20
- 3s - loss: 0.1173 - acc: 0.9608 - binary_crossentropy: 0.1173 - val_loss: 0.3502 - val_acc: 0.8735 - val_binary_crossentropy: 0.3502
Epoch 6/20
- 3s - loss: 0.0964 - acc: 0.9697 - binary_crossentropy: 0.0964 - val_loss: 0.3860 - val_acc: 0.8688 - val_binary_crossentropy: 0.3860
Epoch 7/20
- 3s - loss: 0.0795 - acc: 0.9768 - binary_crossentropy: 0.0795 - val_loss: 0.4404 - val_acc: 0.8605 - val_binary_crossentropy: 0.4404
Epoch 8/20
- 3s - loss: 0.0662 - acc: 0.9814 - binary_crossentropy: 0.0662 - val_loss: 0.4748 - val_acc: 0.8612 - val_binary_crossentropy: 0.4748
Epoch 9/20
- 3s - loss: 0.0540 - acc: 0.9871 - binary_crossentropy: 0.0540 - val_loss: 0.5181 - val_acc: 0.8584 - val_binary_crossentropy: 0.5181
Epoch 10/20
- 3s - loss: 0.0441 - acc: 0.9906 - binary_crossentropy: 0.0441 - val_loss: 0.5704 - val_acc: 0.8554 - val_binary_crossentropy: 0.5704
Epoch 11/20
- 3s - loss: 0.0376 - acc: 0.9919 - binary_crossentropy: 0.0376 - val_loss: 0.6164 - val_acc: 0.8547 - val_binary_crossentropy: 0.6164
Epoch 12/20
- 3s - loss: 0.0289 - acc: 0.9951 - binary_crossentropy: 0.0289 - val_loss: 0.6639 - val_acc: 0.8528 - val_binary_crossentropy: 0.6639
Epoch 13/20
- 3s - loss: 0.0225 - acc: 0.9967 - binary_crossentropy: 0.0225 - val_loss: 0.7050 - val_acc: 0.8518 - val_binary_crossentropy: 0.7050
Epoch 14/20
- 3s - loss: 0.0174 - acc: 0.9982 - binary_crossentropy: 0.0174 - val_loss: 0.7472 - val_acc: 0.8502 - val_binary_crossentropy: 0.7472
Epoch 15/20
- 3s - loss: 0.0132 - acc: 0.9990 - binary_crossentropy: 0.0132 - val_loss: 0.7909 - val_acc: 0.8502 - val_binary_crossentropy: 0.7909
Epoch 16/20
- 3s - loss: 0.0103 - acc: 0.9994 - binary_crossentropy: 0.0103 - val_loss: 0.8295 - val_acc: 0.8500 - val_binary_crossentropy: 0.8295
Epoch 17/20
- 3s - loss: 0.0080 - acc: 0.9998 - binary_crossentropy: 0.0080 - val_loss: 0.8620 - val_acc: 0.8490 - val_binary_crossentropy: 0.8620
Epoch 18/20
- 3s - loss: 0.0063 - acc: 0.9999 - binary_crossentropy: 0.0063 - val_loss: 0.8932 - val_acc: 0.8484 - val_binary_crossentropy: 0.8932
Epoch 19/20
- 3s - loss: 0.0051 - acc: 1.0000 - binary_crossentropy: 0.0051 - val_loss: 0.9225 - val_acc: 0.8490 - val_binary_crossentropy: 0.9225
Epoch 20/20
- 3s - loss: 0.0042 - acc: 1.0000 - binary_crossentropy: 0.0042 - val_loss: 0.9477 - val_acc: 0.8478 - val_binary_crossentropy: 0.9477
创建一个更小的模型
我们创建一个隐藏单元更少的模型,然后与我们刚刚创建的基准模型进行比较:
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 4) 40004
_________________________________________________________________
dense_4 (Dense) (None, 4) 20
_________________________________________________________________
dense_5 (Dense) (None, 1) 5
=================================================================
Total params: 40,029
Trainable params: 40,029
Non-trainable params: 0
_________________________________________________________________
使用相同的数据训练该模型:
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.6094 - acc: 0.6707 - binary_crossentropy: 0.6094 - val_loss: 0.5141 - val_acc: 0.8269 - val_binary_crossentropy: 0.5141
Epoch 2/20
- 3s - loss: 0.4043 - acc: 0.8810 - binary_crossentropy: 0.4043 - val_loss: 0.3588 - val_acc: 0.8788 - val_binary_crossentropy: 0.3588
Epoch 3/20
- 3s - loss: 0.2764 - acc: 0.9154 - binary_crossentropy: 0.2764 - val_loss: 0.3011 - val_acc: 0.8870 - val_binary_crossentropy: 0.3011
Epoch 4/20
- 3s - loss: 0.2182 - acc: 0.9295 - binary_crossentropy: 0.2182 - val_loss: 0.2861 - val_acc: 0.8880 - val_binary_crossentropy: 0.2861
Epoch 5/20
- 3s - loss: 0.1842 - acc: 0.9400 - binary_crossentropy: 0.1842 - val_loss: 0.2870 - val_acc: 0.8848 - val_binary_crossentropy: 0.2870
Epoch 6/20
- 3s - loss: 0.1599 - acc: 0.9477 - binary_crossentropy: 0.1599 - val_loss: 0.2898 - val_acc: 0.8852 - val_binary_crossentropy: 0.2898
Epoch 7/20
- 3s - loss: 0.1409 - acc: 0.9563 - binary_crossentropy: 0.1409 - val_loss: 0.2994 - val_acc: 0.8824 - val_binary_crossentropy: 0.2994
Epoch 8/20
- 3s - loss: 0.1259 - acc: 0.9618 - binary_crossentropy: 0.1259 - val_loss: 0.3139 - val_acc: 0.8792 - val_binary_crossentropy: 0.3139
Epoch 9/20
- 3s - loss: 0.1136 - acc: 0.9653 - binary_crossentropy: 0.1136 - val_loss: 0.3287 - val_acc: 0.8755 - val_binary_crossentropy: 0.3287
Epoch 10/20
- 3s - loss: 0.1021 - acc: 0.9707 - binary_crossentropy: 0.1021 - val_loss: 0.3449 - val_acc: 0.8727 - val_binary_crossentropy: 0.3449
Epoch 11/20
- 3s - loss: 0.0923 - acc: 0.9747 - binary_crossentropy: 0.0923 - val_loss: 0.3632 - val_acc: 0.8712 - val_binary_crossentropy: 0.3632
Epoch 12/20
- 3s - loss: 0.0829 - acc: 0.9778 - binary_crossentropy: 0.0829 - val_loss: 0.3812 - val_acc: 0.8693 - val_binary_crossentropy: 0.3812
Epoch 13/20
- 3s - loss: 0.0749 - acc: 0.9805 - binary_crossentropy: 0.0749 - val_loss: 0.3996 - val_acc: 0.8670 - val_binary_crossentropy: 0.3996
Epoch 14/20
- 3s - loss: 0.0677 - acc: 0.9844 - binary_crossentropy: 0.0677 - val_loss: 0.4238 - val_acc: 0.8648 - val_binary_crossentropy: 0.4238
Epoch 15/20
- 3s - loss: 0.0608 - acc: 0.9867 - binary_crossentropy: 0.0608 - val_loss: 0.4385 - val_acc: 0.8646 - val_binary_crossentropy: 0.4385
Epoch 16/20
- 3s - loss: 0.0548 - acc: 0.9886 - binary_crossentropy: 0.0548 - val_loss: 0.4602 - val_acc: 0.8630 - val_binary_crossentropy: 0.4602
Epoch 17/20
- 3s - loss: 0.0493 - acc: 0.9906 - binary_crossentropy: 0.0493 - val_loss: 0.4828 - val_acc: 0.8601 - val_binary_crossentropy: 0.4828
Epoch 18/20
- 3s - loss: 0.0439 - acc: 0.9923 - binary_crossentropy: 0.0439 - val_loss: 0.5161 - val_acc: 0.8589 - val_binary_crossentropy: 0.5161
Epoch 19/20
- 3s - loss: 0.0390 - acc: 0.9940 - binary_crossentropy: 0.0390 - val_loss: 0.5295 - val_acc: 0.8580 - val_binary_crossentropy: 0.5295
Epoch 20/20
- 3s - loss: 0.0349 - acc: 0.9948 - binary_crossentropy: 0.0349 - val_loss: 0.5514 - val_acc: 0.8565 - val_binary_crossentropy: 0.5514
创建一个更大的模型
作为练习,您可以创建一个更大的模型,看看它多快开始过拟合。接下来,我们向这个基准添加一个容量大得多的网络,远远超出解决问题所需的容量:
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 5120512
_________________________________________________________________
dense_7 (Dense) (None, 512) 262656
_________________________________________________________________
dense_8 (Dense) (None, 1) 513
=================================================================
Total params: 5,383,681
Trainable params: 5,383,681
Non-trainable params: 0
_________________________________________________________________
再次使用相同的数据训练该模型:
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 6s - loss: 0.3481 - acc: 0.8512 - binary_crossentropy: 0.3481 - val_loss: 0.2956 - val_acc: 0.8800 - val_binary_crossentropy: 0.2956
Epoch 2/20
- 6s - loss: 0.1474 - acc: 0.9462 - binary_crossentropy: 0.1474 - val_loss: 0.3600 - val_acc: 0.8643 - val_binary_crossentropy: 0.3600
Epoch 3/20
- 6s - loss: 0.0576 - acc: 0.9824 - binary_crossentropy: 0.0576 - val_loss: 0.4228 - val_acc: 0.8669 - val_binary_crossentropy: 0.4228
Epoch 4/20
- 6s - loss: 0.0111 - acc: 0.9980 - binary_crossentropy: 0.0111 - val_loss: 0.5609 - val_acc: 0.8688 - val_binary_crossentropy: 0.5609
Epoch 5/20
- 6s - loss: 0.0014 - acc: 1.0000 - binary_crossentropy: 0.0014 - val_loss: 0.6633 - val_acc: 0.8688 - val_binary_crossentropy: 0.6633
Epoch 6/20
- 6s - loss: 3.1242e-04 - acc: 1.0000 - binary_crossentropy: 3.1242e-04 - val_loss: 0.7067 - val_acc: 0.8696 - val_binary_crossentropy: 0.7067
Epoch 7/20
- 6s - loss: 1.7861e-04 - acc: 1.0000 - binary_crossentropy: 1.7861e-04 - val_loss: 0.7352 - val_acc: 0.8702 - val_binary_crossentropy: 0.7352
Epoch 8/20
- 6s - loss: 1.2336e-04 - acc: 1.0000 - binary_crossentropy: 1.2336e-04 - val_loss: 0.7565 - val_acc: 0.8706 - val_binary_crossentropy: 0.7565
Epoch 9/20
- 6s - loss: 9.1178e-05 - acc: 1.0000 - binary_crossentropy: 9.1178e-05 - val_loss: 0.7747 - val_acc: 0.8708 - val_binary_crossentropy: 0.7747
Epoch 10/20
- 6s - loss: 7.0124e-05 - acc: 1.0000 - binary_crossentropy: 7.0124e-05 - val_loss: 0.7901 - val_acc: 0.8708 - val_binary_crossentropy: 0.7901
Epoch 11/20
- 6s - loss: 5.5512e-05 - acc: 1.0000 - binary_crossentropy: 5.5512e-05 - val_loss: 0.8039 - val_acc: 0.8711 - val_binary_crossentropy: 0.8039
Epoch 12/20
- 6s - loss: 4.4797e-05 - acc: 1.0000 - binary_crossentropy: 4.4797e-05 - val_loss: 0.8167 - val_acc: 0.8711 - val_binary_crossentropy: 0.8167
Epoch 13/20
- 6s - loss: 3.6816e-05 - acc: 1.0000 - binary_crossentropy: 3.6816e-05 - val_loss: 0.8278 - val_acc: 0.8713 - val_binary_crossentropy: 0.8278
Epoch 14/20
- 6s - loss: 3.0683e-05 - acc: 1.0000 - binary_crossentropy: 3.0683e-05 - val_loss: 0.8389 - val_acc: 0.8714 - val_binary_crossentropy: 0.8389
Epoch 15/20
- 6s - loss: 2.5789e-05 - acc: 1.0000 - binary_crossentropy: 2.5789e-05 - val_loss: 0.8493 - val_acc: 0.8714 - val_binary_crossentropy: 0.8493
Epoch 16/20
- 6s - loss: 2.1778e-05 - acc: 1.0000 - binary_crossentropy: 2.1778e-05 - val_loss: 0.8598 - val_acc: 0.8716 - val_binary_crossentropy: 0.8598
Epoch 17/20
- 6s - loss: 1.8315e-05 - acc: 1.0000 - binary_crossentropy: 1.8315e-05 - val_loss: 0.8724 - val_acc: 0.8715 - val_binary_crossentropy: 0.8724
Epoch 18/20
- 6s - loss: 1.5310e-05 - acc: 1.0000 - binary_crossentropy: 1.5310e-05 - val_loss: 0.8847 - val_acc: 0.8716 - val_binary_crossentropy: 0.8847
Epoch 19/20
- 6s - loss: 1.2654e-05 - acc: 1.0000 - binary_crossentropy: 1.2654e-05 - val_loss: 0.8981 - val_acc: 0.8715 - val_binary_crossentropy: 0.8981
Epoch 20/20
- 6s - loss: 1.0461e-05 - acc: 1.0000 - binary_crossentropy: 1.0461e-05 - val_loss: 0.9131 - val_acc: 0.8714 - val_binary_crossentropy: 0.9131
绘制训练损失和验证损失图表
实线表示训练损失,虚线表示验证损失(请谨记:验证损失越低,表示模型越好)。在此示例中,较小的网络开始过拟合的时间比基准模型晚(前者在 6 个周期之后,后者在 4 个周期之后),并且开始过拟合后,它的效果下降速度也慢得多。
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
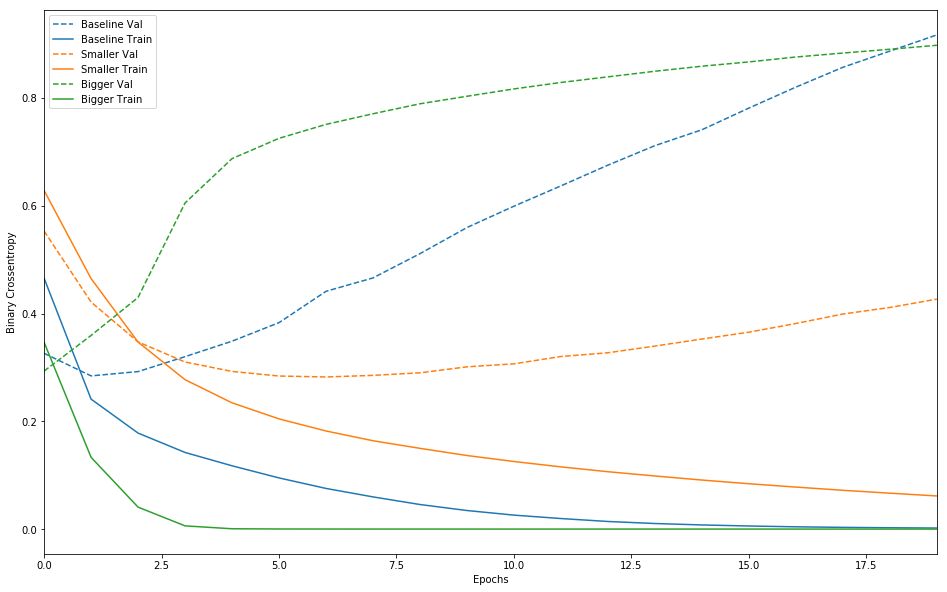
请注意,较大的网络几乎仅仅 1 个周期之后便立即开始过拟合,并且之后严重得多。网络容量越大,便能够越快对训练数据进行建模(产生较低的训练损失),但越容易过拟合(导致训练损失与验证损失之间的差异很大)。
策略
添加权重正则化
您可能熟悉奥卡姆剃刀定律:如果对于同一现象有两种解释,最可能正确的解释是 “最简单” 的解释,即做出最少量假设的解释。这也适用于神经网络学习的模型:给定一些训练数据和一个网络架构,有多组权重值(多个模型)可以解释数据,而简单模型比复杂模型更不容易过拟合。
在这种情况下,“简单模型” 是一种参数值分布的熵较低的模型(或者具有较少参数的模型,如我们在上面的部分中所见)。因此,要缓解过拟合,一种常见方法是限制网络的复杂性,具体方法是强制要求其权重仅采用较小的值,使权重值的分布更 “规则”。这称为 “权重正则化”,通过向网络的损失函数添加与权重较大相关的代价来实现。这个代价分为两种类型:
L1 正则化,其中所添加的代价与权重系数的绝对值(即所谓的权重 “L1 范数”)成正比
L2 正则化,其中所添加的代价与权重系数值的平方(即所谓的权重 “L2 范数”)成正比。L2 正则化在神经网络领域也称为权重衰减。不要因为名称不同而感到困惑:从数学角度来讲,权重衰减与 L2 正则化完全相同
在 tf.keras 中,权重正则化的添加方法如下:将权重正则化项实例作为关键字参数传递给层。现在,我们来添加 L2 权重正则化。
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.5232 - acc: 0.8118 - binary_crossentropy: 0.4838 - val_loss: 0.3806 - val_acc: 0.8779 - val_binary_crossentropy: 0.3387
Epoch 2/20
- 2s - loss: 0.3075 - acc: 0.9089 - binary_crossentropy: 0.2609 - val_loss: 0.3351 - val_acc: 0.8880 - val_binary_crossentropy: 0.2851
Epoch 3/20
- 2s - loss: 0.2582 - acc: 0.9281 - binary_crossentropy: 0.2059 - val_loss: 0.3369 - val_acc: 0.8861 - val_binary_crossentropy: 0.2829
Epoch 4/20
- 2s - loss: 0.2336 - acc: 0.9391 - binary_crossentropy: 0.1781 - val_loss: 0.3478 - val_acc: 0.8827 - val_binary_crossentropy: 0.2915
Epoch 5/20
- 2s - loss: 0.2204 - acc: 0.9445 - binary_crossentropy: 0.1625 - val_loss: 0.3598 - val_acc: 0.8794 - val_binary_crossentropy: 0.3011
Epoch 6/20
- 2s - loss: 0.2074 - acc: 0.9501 - binary_crossentropy: 0.1482 - val_loss: 0.3733 - val_acc: 0.8766 - val_binary_crossentropy: 0.3139
Epoch 7/20
- 2s - loss: 0.2003 - acc: 0.9524 - binary_crossentropy: 0.1399 - val_loss: 0.3875 - val_acc: 0.8736 - val_binary_crossentropy: 0.3264
Epoch 8/20
- 2s - loss: 0.1922 - acc: 0.9563 - binary_crossentropy: 0.1304 - val_loss: 0.3968 - val_acc: 0.8722 - val_binary_crossentropy: 0.3349
Epoch 9/20
- 2s - loss: 0.1863 - acc: 0.9576 - binary_crossentropy: 0.1239 - val_loss: 0.4127 - val_acc: 0.8709 - val_binary_crossentropy: 0.3498
Epoch 10/20
- 2s - loss: 0.1843 - acc: 0.9588 - binary_crossentropy: 0.1208 - val_loss: 0.4287 - val_acc: 0.8673 - val_binary_crossentropy: 0.3647
Epoch 11/20
- 2s - loss: 0.1787 - acc: 0.9612 - binary_crossentropy: 0.1142 - val_loss: 0.4393 - val_acc: 0.8654 - val_binary_crossentropy: 0.3742
Epoch 12/20
- 2s - loss: 0.1752 - acc: 0.9619 - binary_crossentropy: 0.1101 - val_loss: 0.4626 - val_acc: 0.8622 - val_binary_crossentropy: 0.3970
Epoch 13/20
- 2s - loss: 0.1747 - acc: 0.9629 - binary_crossentropy: 0.1083 - val_loss: 0.4641 - val_acc: 0.8640 - val_binary_crossentropy: 0.3973
Epoch 14/20
- 2s - loss: 0.1640 - acc: 0.9668 - binary_crossentropy: 0.0972 - val_loss: 0.4750 - val_acc: 0.8612 - val_binary_crossentropy: 0.4085
Epoch 15/20
- 2s - loss: 0.1570 - acc: 0.9700 - binary_crossentropy: 0.0907 - val_loss: 0.4934 - val_acc: 0.8612 - val_binary_crossentropy: 0.4270
Epoch 16/20
- 2s - loss: 0.1540 - acc: 0.9713 - binary_crossentropy: 0.0871 - val_loss: 0.5082 - val_acc: 0.8586 - val_binary_crossentropy: 0.4410
Epoch 17/20
- 2s - loss: 0.1516 - acc: 0.9726 - binary_crossentropy: 0.0844 - val_loss: 0.5187 - val_acc: 0.8576 - val_binary_crossentropy: 0.4510
Epoch 18/20
- 2s - loss: 0.1493 - acc: 0.9724 - binary_crossentropy: 0.0812 - val_loss: 0.5368 - val_acc: 0.8556 - val_binary_crossentropy: 0.4681
Epoch 19/20
- 2s - loss: 0.1449 - acc: 0.9753 - binary_crossentropy: 0.0761 - val_loss: 0.5439 - val_acc: 0.8573 - val_binary_crossentropy: 0.4750
Epoch 20/20
- 2s - loss: 0.1445 - acc: 0.9752 - binary_crossentropy: 0.0749 - val_loss: 0.5579 - val_acc: 0.8555 - val_binary_crossentropy: 0.4877
l2(0.001) 表示层的权重矩阵中的每个系数都会将 0.001 * weight_coefficient_value**2 添加到网络的总损失中。请注意,由于此惩罚仅在训练时添加,此网络在训练时的损失将远高于测试时。
以下是 L2 正则化惩罚的影响:
plot_history([('baseline', baseline_history),
('l2', l2_model_history)])
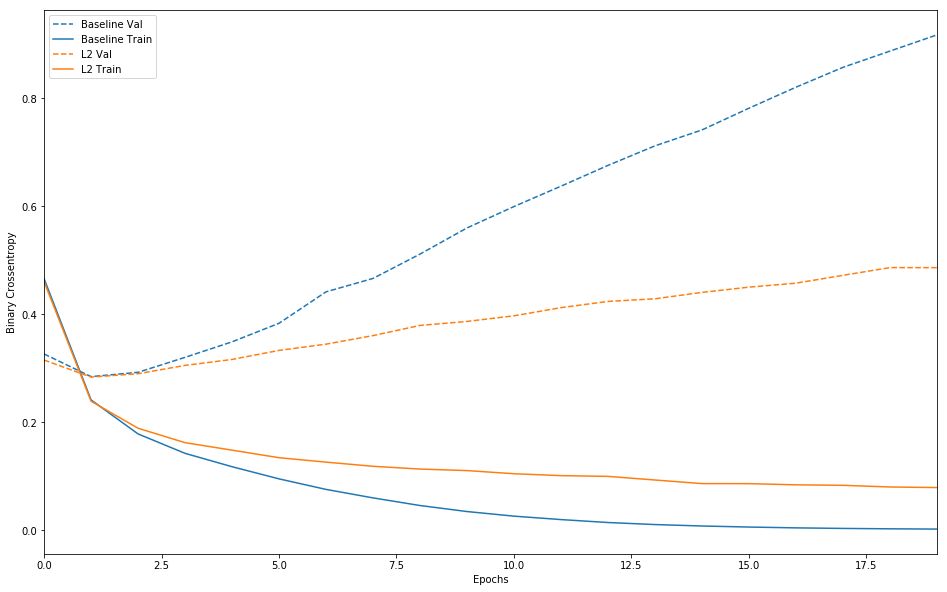
可以看到,L2 正则化模型的过拟合抵抗能力比基准模型强得多,虽然这两个模型的参数数量相同。
添加丢弃层
丢弃是由 Hinton 及其在多伦多大学的学生开发的,是最有效且最常用的神经网络正则化技术之一。丢弃(应用于某个层)是指在训练期间随机 “丢弃”(即设置为 0)该层的多个输出特征。假设某个指定的层通常会在训练期间针对给定的输入样本返回一个向量 [0.2, 0.5, 1.3, 0.8, 1.1];在应用丢弃后,此向量将随机分布几个 0 条目,例如 [0, 0.5, 1.3, 0, 1.1]。“丢弃率” 指变为 0 的特征所占的比例,通常设置在 0.2 和 0.5 之间。在测试时,网络不会丢弃任何单元,而是将层的输出值按等同于丢弃率的比例进行缩减,以便平衡以下事实:测试时的活跃单元数大于训练时的活跃单元数。
在 tf.keras 中,您可以通过丢弃层将丢弃引入网络中,以便事先将其应用于层的输出。
下面我们在 IMDB 网络中添加两个丢弃层,看看它们在降低过拟合方面表现如何:
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.6315 - acc: 0.6358 - binary_crossentropy: 0.6315 - val_loss: 0.5245 - val_acc: 0.8326 - val_binary_crossentropy: 0.5245
Epoch 2/20
- 2s - loss: 0.4959 - acc: 0.8044 - binary_crossentropy: 0.4959 - val_loss: 0.3973 - val_acc: 0.8743 - val_binary_crossentropy: 0.3973
Epoch 3/20
- 2s - loss: 0.3848 - acc: 0.8720 - binary_crossentropy: 0.3848 - val_loss: 0.3270 - val_acc: 0.8864 - val_binary_crossentropy: 0.3270
Epoch 4/20
- 2s - loss: 0.3106 - acc: 0.9069 - binary_crossentropy: 0.3106 - val_loss: 0.2972 - val_acc: 0.8883 - val_binary_crossentropy: 0.2972
Epoch 5/20
- 2s - loss: 0.2692 - acc: 0.9194 - binary_crossentropy: 0.2692 - val_loss: 0.2902 - val_acc: 0.8866 - val_binary_crossentropy: 0.2902
Epoch 6/20
- 2s - loss: 0.2264 - acc: 0.9343 - binary_crossentropy: 0.2264 - val_loss: 0.3005 - val_acc: 0.8848 - val_binary_crossentropy: 0.3005
Epoch 7/20
- 2s - loss: 0.2026 - acc: 0.9406 - binary_crossentropy: 0.2026 - val_loss: 0.3158 - val_acc: 0.8846 - val_binary_crossentropy: 0.3158
Epoch 8/20
- 2s - loss: 0.1801 - acc: 0.9482 - binary_crossentropy: 0.1801 - val_loss: 0.3287 - val_acc: 0.8830 - val_binary_crossentropy: 0.3287
Epoch 9/20
- 2s - loss: 0.1604 - acc: 0.9545 - binary_crossentropy: 0.1604 - val_loss: 0.3329 - val_acc: 0.8806 - val_binary_crossentropy: 0.3329
Epoch 10/20
- 2s - loss: 0.1483 - acc: 0.9588 - binary_crossentropy: 0.1483 - val_loss: 0.3490 - val_acc: 0.8786 - val_binary_crossentropy: 0.3490
Epoch 11/20
- 2s - loss: 0.1322 - acc: 0.9625 - binary_crossentropy: 0.1322 - val_loss: 0.3758 - val_acc: 0.8774 - val_binary_crossentropy: 0.3758
Epoch 12/20
- 2s - loss: 0.1249 - acc: 0.9644 - binary_crossentropy: 0.1249 - val_loss: 0.3953 - val_acc: 0.8764 - val_binary_crossentropy: 0.3953
Epoch 13/20
- 2s - loss: 0.1151 - acc: 0.9663 - binary_crossentropy: 0.1151 - val_loss: 0.4445 - val_acc: 0.8766 - val_binary_crossentropy: 0.4445
Epoch 14/20
- 2s - loss: 0.1096 - acc: 0.9686 - binary_crossentropy: 0.1096 - val_loss: 0.4400 - val_acc: 0.8753 - val_binary_crossentropy: 0.4400
Epoch 15/20
- 2s - loss: 0.0995 - acc: 0.9726 - binary_crossentropy: 0.0995 - val_loss: 0.4778 - val_acc: 0.8760 - val_binary_crossentropy: 0.4778
Epoch 16/20
- 2s - loss: 0.0959 - acc: 0.9734 - binary_crossentropy: 0.0959 - val_loss: 0.4899 - val_acc: 0.8759 - val_binary_crossentropy: 0.4899
Epoch 17/20
- 2s - loss: 0.0929 - acc: 0.9740 - binary_crossentropy: 0.0929 - val_loss: 0.5084 - val_acc: 0.8754 - val_binary_crossentropy: 0.5084
Epoch 18/20
- 2s - loss: 0.0917 - acc: 0.9733 - binary_crossentropy: 0.0917 - val_loss: 0.5460 - val_acc: 0.8745 - val_binary_crossentropy: 0.5460
Epoch 19/20
- 2s - loss: 0.0841 - acc: 0.9775 - binary_crossentropy: 0.0841 - val_loss: 0.5420 - val_acc: 0.8754 - val_binary_crossentropy: 0.5420
Epoch 20/20
- 2s - loss: 0.0803 - acc: 0.9786 - binary_crossentropy: 0.0803 - val_loss: 0.5750 - val_acc: 0.8744 - val_binary_crossentropy: 0.5750
plot_history([('baseline', baseline_history),
('dropout', dpt_model_history)])
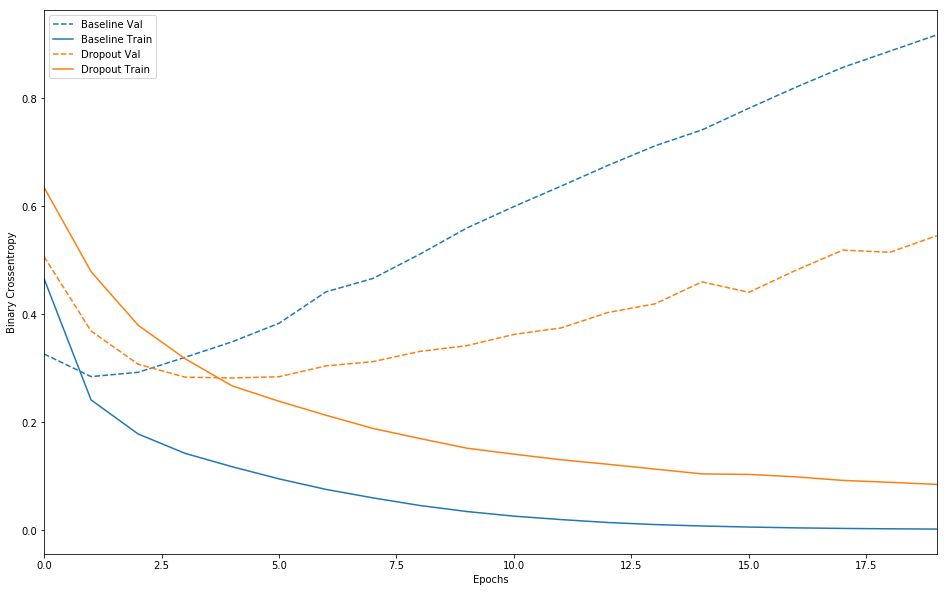
添加丢弃层可明显改善基准模型。
下面总结一下防止神经网络出现过拟合的最常见方法:
获取更多训练数据
降低网络容量
添加权重正则化
添加丢弃层
还有两个重要的方法在本指南中没有介绍:数据增强和批次归一化。
#@title MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
更多 AI 相关阅读:
实现 TensorFlow 架构的规模性和灵活性
tf.data API,构建高性能 TensorFlow 输入管道
TensorFlow 帮你实现更好的结构化图层和模型















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









