






上篇看这里:MySQL窗口函数总结(上)
2.4 取行函数
FIRST_VALUE() and LAST_VALUE() and NTH_VALUE():根据分区及其排序取指定参数的值
SELECT
id,
`year`,
country,
product,
profit,
ROW_NUMBER ( ) over w AS row_num,
RANK ( ) over w AS rank_num,
FIRST_VALUE ( profit ) OVER w AS first_v,
LAST_VALUE ( profit ) OVER w AS last_v,
NTH_VALUE ( profit, 2) OVER w AS second_v,
NTH_VALUE ( profit, 5) OVER w AS fifth_v
FROM
`test`.`sales`
WINDOW w AS ( PARTITION BY country ORDER BY `year` DESC, profit ASC )
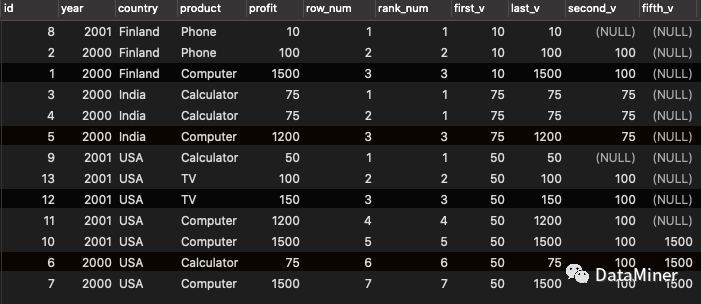
从以上输出结果我们可以看出:
FIRST_VALUE()取分区中rank第一的行对应的profit值;
FIRST_VALUE()取分区中rank最后的行对应的profit值;
NTH_VALUE()取分区中rank为n的行对应的profit值,如果n超过窗口的最大长度,返回NULL
2.5 偏移函数
LAG() and LEAD() :LAG/LEAD(expr,offset, default) 按偏移量取分区中当前行之前/之后第几行的值,如果当前行号为rn,则取行号为rn±offset的值,其中offset:偏移量,BIGINT类型常量,取值大于0,缺省为1,default:当offset指定的范围越界时的缺省值,常量,默认值为NULL。
SELECT
id,
`year`,
country,
product,
profit,
ROW_NUMBER ( ) over w AS row_num,
RANK ( ) over w AS rank_num,
LAG ( profit) OVER w AS lag_v,
LEAD ( profit ) OVER w AS lead_v,
profit - LAG ( profit ) OVER w AS lag_diff_v,
profit - LEAD ( profit ) OVER w AS lead_diff_v,
LAG ( profit,2,0) OVER w AS lag_v1, -- 偏移量=2,如果超出分区的行数,则返回0
LEAD ( profit,2,-1) OVER w AS lead_v1 -- 偏移量=2,如果超出分区的行数,则返回-1
FROM
`test`.`sales`
WINDOW w AS ( PARTITION BY country ORDER BY `year` DESC, profit ASC )
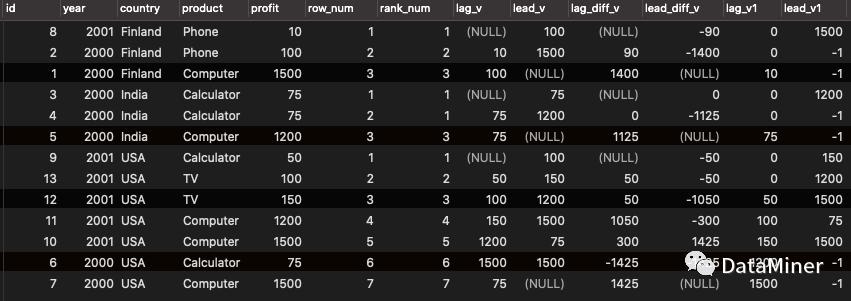
输出结果中可以看出:
lag_v 和lead_v未指定偏移量使用默认值,分别默认返回分区中当前行向前偏移1行和向后偏移1行的值;
lag_v1和lead_v1指定了偏移量和缺省值,返回指定偏移量的值,超出分区行数返回设置缺省值;
在取订单时间间隔、登录时间间隔等问题中非常有用。
2.6 切片函数
NTILE(N)将分区数据按照顺序切分成n片,并返回当前切片值。如果切片不均匀,默认增加第一个切片的分布。
SELECT
id,
`year`,
country,
product,
profit,
ROW_NUMBER ( ) over w AS row_num,
RANK ( ) over w AS rank_num,
NTILE ( 2) OVER w AS nitle_2,
NTILE ( 3) OVER w AS nitle_3,
NTILE ( 4) OVER w AS nitle_4
FROM
`test`.`sales`
WINDOW w AS ( PARTITION BY product ORDER BY `year` DESC, profit ASC )
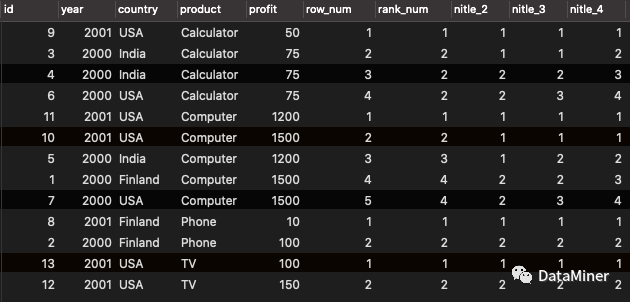
3. 聚合窗口函数
3.1 聚合函数
在窗口中每条记录动态应用聚合函数(SUM/AVG/MAX/MIN/COUNT),可以动态计算在指定的窗口内的各种聚合函数值。
SELECT
id,
`year`,
country,
product,
profit,
ROW_NUMBER ( ) over w AS row_num,
RANK ( ) over w AS rank_num,
SUM( profit ) OVER w AS sum_v,
AVG( profit ) OVER w AS avg_v,
MAX( profit ) OVER w AS max_v,
MIN( profit ) OVER w AS min_v,
COUNT( profit ) OVER w AS cnt_v
FROM
`test`.`sales`
WINDOW w AS ( PARTITION BY country ORDER BY `year` DESC, profit ASC )
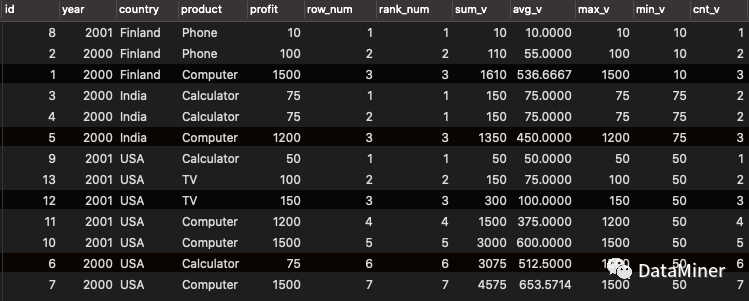
当frame_clause缺省的时候按当前行rank及之前的区域进行聚合计算;
我们观察id in (3,4)的行,它们的rank相同时,count产生间隔从结果没有直接从2开始,sum、avg在id=3时,聚合计算区域包含id=4的行
3.2 框架设置
框架设置frame_clause的参数见#1窗口函数语法部分
SELECT
id,
`year`,
country,
product,
profit,
ROW_NUMBER ( ) over w AS row_num,
RANK ( ) over w AS rank_num,
SUM( profit ) OVER w AS sum_v,
SUM( profit ) OVER ( PARTITION BY country ORDER BY `year` DESC, profit ASC ROWS UNBOUNDED PRECEDING ) AS running_sum_1,
SUM( profit ) OVER ( PARTITION BY country ORDER BY `year` DESC, profit ASC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) AS running_sum_2
FROM
`test`.`sales`
WINDOW w AS ( PARTITION BY country ORDER BY `year` DESC, profit ASC )
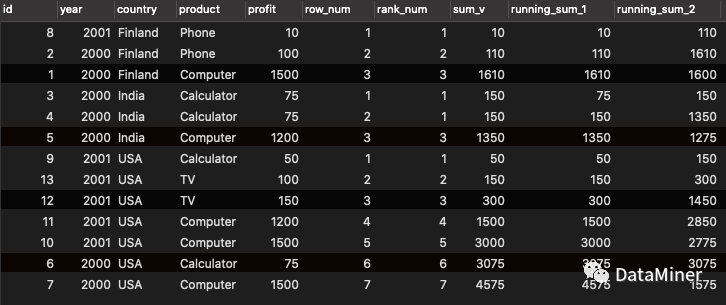
running_sum_1中指定了frame_start=UNBOUNDED PRECEDING,聚合时按当前行上侧所有行进行计算,可以对比一下id=3\4的sum_v与running_sum_1的值;
running_sum_2指定了参数frame_between=BETWEEN 1 PRECEDING AND 1 FOLLOWING,聚合时按当前行上侧1行到当前行下侧一行区域进行计算
窗口函数的增加,极大的方便了SQL代码的编写和逻辑的实现,还有一些其他的情况没有写到可以看一下官方文档。
















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









